Κεφάλαιο 1 :
Γενικές αρχές Βάσεων Δεδομένων
1.1
Εισαγωγή στις Βάσεις Δεδομένων
Η αλματώδης ανάπτυξη της επιστήμης της πληροφορικής και των επικοινωνιών τα τελευταία χρόνια έχει καταστήσει την πληροφορία ως ένα από τα βασικότερα και πολυτιμότερα αγαθά. Είναι κοινός τόπος σήμερα η εκτίμηση ότι το αγαθό της πληροφορίας είναι επιθυμητό απ’ όλους τους εργαζόμενους αλλά και τους εκπαιδευόμενους, ώστε να είναι πιο αποδοτικοί, ανταγωνιστικοί αλλά και παραγωγικοί στην εργασία τους.
Τα συστήματα βάσεων δεδομένων τα χρησιμοποιούμε για να μπορούμε να αποθηκεύσουμε, να επεξεργαστούμε αλλά και να εκμεταλλευτούμε αποδοτικά αυτόν τον τεράστιο όγκο των πληροφοριών που αυξάνονται με αλματώδεις ρυθμούς καθημερινά.
1.1.1 Τα
Δεδομένα και οι Πληροφορίες
Με τον όρο πληροφορία αναφερόμαστε συνήθως σε ειδήσεις, γεγονότα και έννοιες που αποκτάμε από την καθημερινή μας επικοινωνία και τα θεωρούμε ως αποκτηθείσα γνώση, ενώ τα δεδομένα μπορούν να είναι μη κατάλληλα επεξεργασμένα και μη ταξινομημένα σύνολα πληροφοριών. Ένας αυστηρός ορισμός για το τι είναι δεδομένα και τι είναι πληροφορία, σύμφωνα με την επιτροπή ANSI των ΗΠΑ, είναι ο εξής :
• Δεδομένα (data) είναι μια παράσταση, όπως γράμματα, αριθμοί, σύμβολα κ.ά. στα οποία μπορούμε να δώσουμε κάποια σημασία (έννοια).
• Πληροφορία (information) είναι η σημασία που δίνουμε σ’ ένα σύνολο από δεδομένα, τα οποία μπορούμε να επεξεργαστούμε βάσει προκαθορισμένων κανόνων και να βγάλουμε έτσι κάποια χρήσιμα συμπεράσματα. Με τις πληροφορίες περιορίζεται η αβεβαιότητα που έχουμε για διάφορα πράγματα και βοηθιόμαστε έτσι στο να λάβουμε σωστές αποφάσεις.
Τα δεδομένα μπορούν να θεωρηθούν ως τρόποι αναπαράστασης εννοιών και γεγονότων που μπορούν να υποστούν διαχείριση και επεξεργασία. Η συλλογή και αποθήκευση ενός τεράστιου όγκου δεδομένων όπως απαιτούν οι κοινωνικές συνθήκες σήμερα, δεν λύνει τελείως το πρόβλημα της σωστής οργάνωσης και ταξινόμησης των δεδομένων. Τα δεδομένα θα πρέπει να οργανωθούν με τέτοιο τρόπο έτσι ώστε να μπορούμε να τα εντοπίζουμε και να τα αξιοποιούμε εύκολα και γρήγορα και τη στιγμή που τα χρειαζόμαστε.
Ένα κλασικό παράδειγμα μη σωστής οργάνωσης δεδομένων θα ήταν για παράδειγμα ο τηλεφωνικός κατάλογος της πόλης Σερρών, όπου οι συνδρομητές δεν θα ήταν καταχωρημένοι αλφαβητικά σύμφωνα με το επώνυμο και το όνομά τους, αλλά εντελώς τυχαία. Ένας τέτοιος τηλεφωνικός κατάλογος θα περιείχε μια τεράστια ποσότητα δεδομένων αλλά θα ήταν ουσιαστικά άχρηστος.
Εκτός λοιπόν από τη μόνιμη αποθήκευση των δεδομένων, χρειαζόμαστε και κάποιους τρόπους ευέλικτης και αποδοτικής οργάνωσής τους.
1.1.2
Προβλήματα στην Οργάνωση Αρχείων
Στα αρχικά στάδια της οργάνωσης αρχείων, μια συνηθισμένη πρακτική ήταν η δημιουργία ξεχωριστών εφαρμογών (προγραμμάτων) και ξεχωριστών αρχείων, όπως για παράδειγμα η δημιουργία ενός αρχείου πελατών και ενός άλλου ανεξάρτητου αρχείου για τις παραγγελίες των πελατών. Τα προβλήματα που προέκυψαν από την πρακτική αυτή είναι τα εξής :
• Πλεονασμός των δεδομένων (data redundancy). Υπάρχει η περίπτωση να έχουμε επανάληψη των ίδιων δεδομένων σε αρχεία διαφορετικών εφαρμογών. Για παράδειγμα, αν έχουμε ένα αρχείο πελατών και ένα αρχείο παραγγελιών αυτών των πελατών, είναι σχεδόν σίγουρο ότι θα υπάρχουν κάποια στοιχεία των πελατών που θα υπάρχουν και στα δύο αρχεία.
• Ασυνέπεια των δεδομένων (data inconsistency). Αυτό μπορεί να συμβεί όταν υπάρχουν τα ίδια στοιχεία των πελατών (πλεονασμός) και στο αρχείο πελατών και στο αρχείο παραγγελιών και χρειασθεί να γίνει κάποια αλλαγή στη διεύθυνση ή στα τηλέφωνα κάποιου πελάτη, οπότε είναι πολύ πιθανό να γίνει η διόρθωση μόνο στο ένα αρχείο και όχι και στο άλλο.
• Αδυναμία μερισμού δεδομένων (data sharing). Μερισμός δεδομένων σημαίνει δυνατότητα για κοινή χρήση των στοιχείων κάποιων αρχείων. Για παράδειγμα, ο μερισμός δεδομένων θα ήταν χρήσιμος αν με την παραγγελία ενός πελάτη μπορούμε να έχουμε πρόσβαση την ίδια στιγμή στο αρχείο πελατών για να δούμε το υπόλοιπο του πελάτη και μετά στο αρχείο της αποθήκης για να δούμε αν είναι διαθέσιμα τα προϊόντα που παρήγγειλε ο συγκεκριμένος πελάτης. Η αδυναμία μερισμού δεδομένων δημιουργεί καθυστέρηση στη λήψη αποφάσεων και στην εξυπηρέτηση των χρηστών.
• Αδυναμία προτυποποίησης. Έχει να κάνει με την ανομοιομορφία και με την διαφορετική αναπαράσταση και οργάνωση των δεδομένων στα αρχεία των εφαρμογών. Η αδυναμία αυτή δημιουργεί προβλήματα προσαρμογής των χρηστών καθώς και προβλήματα στην ανταλλαγή δεδομένων μεταξύ διαφορετικών συστημάτων.
Συστήματα βάσης δεδομένων είναι ένα ηλεκτρονικό σύστημα τήρησης εγγραφών, δηλαδή, είναι ένα σύστημα για υπολογιστές, που ο γενικός σκοπός του είναι να τηρεί πληροφορίες και να δίνει αυτές τις πληροφορίες όταν του ζητούνται. Οι πληροφορίες που τηρούνται σε ένα τέτοιο σύστημα μπορεί να είναι οτιδήποτε έχει σημασία για το άτομο ή τον οργανισμό που εξυπηρετεί το συγκεκριμένο σύστημα, με άλλα λόγια οτιδήποτε χρειάζεται για την υποβοήθηση των εργασιών αυτού του ατόμου ή οργανισμού.
Η ίδια η βάση δεδομένων μπορεί να θεωρηθεί ένα είδος ηλεκτρονικής αρχειοθήκης, ένα χώρος για την αποθήκευση μιας συλλογής ηλεκτρονικών αρχείων δεδομένων.
Ο χρήστης του συστήματος έχει στη διάθεση του ορισμένα βοηθήματα για να εκτελεί στα αρχεία Β.Δ. διάφορες εργασίες, στις οποίες συγκαταλέγονται ,ανάμεσα σε άλλες, και οι εξής:
• Η προσθήκη νέων κενών αρχείων στη βάση δεδομένων .
• Η εισαγωγή νέων δεδομένων σε υπάρχοντα αρχεία.
• Η ανάκληση δεδομένων από υπάρχοντα αρχεία.
• Η ενημέρωση δεδομένων σε υπάρχοντα αρχεία.
• Η διαγραφή δεδομένων από υπάρχοντα αρχεία
• Η αφαίρεση υπαρχόντων αρχείων, κενών ή όχι, από τη βάση δεδομένων.
Ένα σύστημα βάσης δεδομένων απαρτίζεται από τέσσερα βασικά στοιχεία: τα δεδομένα, το υλικό, το λογισμικό και τους χρήστες.
Τα πλεονεκτήματα ενός συστήματος βάσης δεδομένων, σε σύγκριση με τις παραδοσιακές μεθόδους παρακολούθησης (χαρτί και μολύβι), αρχικά για μια μικρή βάση δεδομένων είναι πολλά
• Οικονομία χώρου (Καταργούνται τα ογκώδη παραδοσιακά αρχεία με φακέλους και έγγραφα).
• Ταχύτητα (το σύστημα μπορεί να ανακαλεί και να αλλάζει τα δεδομένα γρηγορότερα από τον άνθρωπο)
• Λιγότερος κόπος
• Άμεση πληροφόρηση (Ακριβείς και ενημερωμένες πληροφορίες είναι διαθέσιμες κάθε στιγμή).
Επιπλέον, σε ένα περιβάλλον πολλών χρηστών, το σύστημα βάσης δεδομένων παρέχει στην επιχείρηση κεντρικό έλεγχο των δεδομένων της ώστε να προκύπτουν τα εξής πλεονεκτήματα:
• Ο πλεονασμός μειώνεται στο ελάχιστο . Στα συμβατικά συστήματα (εκείνα που δεν είναι συστήματα βάσεων δεδομένων), η κάθε εφαρμογή έχει τα δικά της αρχεία. Αυτό το γεγονός οδηγεί πολύ συχνά σε υψηλό βαθμό πλεονασμού (επανάληψης) για τα αποθηκευμένα δεδομένα, με αποτέλεσμα τη σπατάλη αποθηκευτικού χώρου. Θα πρέπει εδώ να ξεκαθαρίσουμε ότι αυτό δε σημαίνει πως είναι πάντα δυνατό να εξαλειφθούν όλοι οι πλεονασμοί, ούτε πως είναι πάντα επιθυμητό. Μερικές φορές υπάρχουν σοβαροί επιχειρηματικοί ή τεχνικοί λόγοι που επιβάλλουν να τηρούνται ξεχωριστά αντίγραφα των ίδιων αποθηκευμένων δεδομένων.
• Η ασυνέπεια μπορεί να αποφευχθεί ( ως ένα βαθμό).Το DBMS θα μπορεί να εγγυηθεί ότι η βάση δεδομένων δε θα είναι ποτέ ασυνεπής στα μάτια του χρηστή ,εξασφαλίζοντας ότι κάθε αλλαγή που θα γίνεται σε οποιαδήποτε από δυο όμοιες καταχωρίσεις θα γίνεται αυτόματα και στην άλλη. Αυτή η διαδικασία είναι γνωστή με το όνομα διάδοση ενημερώσεων.
• Τα δεδομένα μπορούν να είναι κοινόχρηστα. Ο μερισμός δε σημαίνει μόνο ότι οι υπάρχουσες εφαρμογές μπορούν να μοιράζονται τα δεδομένα της βάσης δεδομένων αλλά και ότι είναι δυνατή η ανάπτυξη νέων εφαρμογών που θα μπορούν να χρησιμοποιούν τα ίδια αποθηκευμένα δεδομένα.
• Μπορούν να επιβάλλονται πρότυπα. Η τυποποίηση της αναπαράστασης των δεδομένων διευκολύνει ιδιαίτερα την ανταλλαγή δεδομένων. Τα πρότυπα ονομασίας και τεκμηρίωσης των δεδομένων είναι επίσης πολύ επιθυμητά για να διευκολύνεται ο μερισμός και η καλύτερη κατανόηση των δεδομένων.
• Μπορούν να εφαρμόζονται περιορισμοί ασφαλείας .Έχοντας πλήρη δικαιοδοσία πάνω στη βάση δεδομένων, ο DBA-Database Administrator (α) μπορεί να εξασφαλίσει ότι η πρόσβαση στη βάση δεδομένων θα μπορεί να γίνεται μόνο μέσω των κατάλληλων καναλιών και, κατά συνέπεια, (β) μπορεί να ορίσει κανόνες ασφαλείας με βάση τους οποίους θα γίνεται έλεγχος κάθε φορά που θα υπάρχει απόπειρα προσπέλασης εμπιστευτικών δεδομένων. Βέβαια ένα συστήματα βάσης δεδομένων απαιτεί την ύπαρξη ενός καλού συστήματος ασφαλείας.
• Μπορεί να διατηρείται η ακεραιότητα .Το πρόβλημα της ακεραιότητας είναι να εξασφαλίζεται ότι τα δεδομένα της βάσης δεδομένων είναι ακριβή. Η ασυμφωνία μεταξύ δυο καταχωρίσεων που υποτίθεται ότι αντιπροσωπεύουν το ίδιο “γεγονός” είναι ένα παράδειγμα έλλειψης ακεραιότητας φυσικά, αυτό το συγκεκριμένο πρόβλημα μπορεί να παρουσιαστεί μόνο αν υπάρχει πλεονασμός στα αποθηκευμένα δεδομένα. Ακόμη και αν δεν υπάρχει πλεονασμός όμως, πάλι υπάρχει περίπτωση να περιέχει η βάση δεδομένων λανθασμένες πληροφορίες. Αξίζει να επισημάνουμε ότι η ακεραιότητα των δεδομένων έχει πολύ μεγαλύτερη σημασία σε ένα σύστημα βάσης δεδομένων πολλών χρηστών από ότι σε ένα περιβάλλον “ιδιωτικών αρχείων “, ακριβώς επειδή η βάση δεδομένων είναι μεριζομενη. Αυτό συμβαίνει γιατί, χωρίς τους κατάλληλους ελέγχους, μπορεί ένας χρήστης να ενημερώσει τη βάση δεδομένων με εσφαλμένο τρόπο, δημιουργώντας με αυτό τον τρόπο λανθασμένα δεδομένα και “ μολύνοντας “ τους υπόλοιπους “
• Οι αντικρουόμενες απαιτήσεις μπορούν να εξισορροπούνται. Γνωρίζοντας τις συνολικές απαιτήσεις της επιχείρησης, σε αντιδιαστολή με τις απαιτήσεις των μεμονωμένων χρηστών, ο DBA (πάντα με τις οδηγίες του υπεύθυνου διαχείρισης δεδομένων) μπορεί να δομήσει το σύστημα με τέτοιον τρόπο ώστε να παρέχει γενικές υπηρεσίες που να είναι “ βέλτιστες για την επιχείρηση”. Για παράδειγμα μπορεί να επιλεχθεί μια αναπαράσταση των αποθηκευμένων δεδομένων που να παρέχει γρήγορη πρόσβαση στις σημαντικές εφαρμογές ίσως σε βάρος της απόστασης άλλων εφαρμογών.
1.2.1
Σύστημα Βάσης Δεδομένων (ΣΒΔ)
Ένα Σύστημα Βάσης Δεδομένων (ΣΒΔ) ή DBS (Data Base System) αποτελείται από το υλικό, το λογισμικό, τη βάση δεδομένων και τους χρήστες. Είναι δηλαδή ένα σύστημα με το οποίο μπορούμε να αποθηκεύσουμε και να αξιοποιήσουμε δεδομένα με τη βοήθεια ηλεκτρονικού υπολογιστή. Αναλυτικά :
• Το υλικό (hardware) αποτελείται όπως είναι γνωστό από τους ηλεκτρονικούς υπολογιστές, τα περιφερειακά, τους σκληρούς δίσκους, τις μαγνητικές ταινίες κ.ά., όπου είναι αποθηκευμένα τα αρχεία της βάσης δεδομένων αλλά και τα προγράμματα που χρησιμοποιούνται για την επεξεργασία τους.
• Το λογισμικό (software) είναι τα προγράμματα που χρησιμοποιούνται για την επεξεργασία των δεδομένων (στοιχείων) της βάσης δεδομένων.
• Η βάση δεδομένων (database) αποτελείται από το σύνολο των αρχείων όπου είναι αποθηκευμένα τα δεδομένα του συστήματος. Τα στοιχεία αυτά μπορεί να βρίσκονται αποθηκευμένα σ’ έναν φυσικό υπολογιστή αλλά και σε περισσότερους. Όμως, στον χρήστη δίνεται η εντύπωση ότι βρίσκονται συγκεντρωμένα στον ίδιο υπολογιστή. Τα δεδομένα των αρχείων αυτών είναι ενοποιημένα (data integration), δηλ. δεν υπάρχει πλεονασμός (άσκοπη επανάληψη) δεδομένων και μερισμένα (data sharing), δηλ. υπάρχει δυνατότητα ταυτόχρονης προσπέλασης των δεδομένων από πολλούς χρήστες. Ο κάθε χρήστης έχει διαφορετικά δικαιώματα και βλέπει διαφορετικό κομμάτι της βάσης δεδομένων, ανάλογα με τον σκοπό για τον οποίο συνδέεται.
• Οι χρήστες (users) μιας βάσης δεδομένων χωρίζονται στις εξής κατηγορίες :
• Τελικοί χρήστες (end users). Χρησιμοποιούν κάποια εφαρμογή για να παίρνουν στοιχεία από μια βάση δεδομένων, έχουν τις λιγότερες δυνατότητες επέμβασης στα στοιχεία της βάσης δεδομένων, χρησιμοποιούν ειδικούς κωδικούς πρόσβασης και το σύστημα τούς επιτρέπει ανάλογα πρόσβαση σε συγκεκριμένο κομμάτι της βάσης δεδομένων.
• Προγραμματιστές εφαρμογών (application programmers). Αναπτύσσουν τις εφαρμογές του ΣΒΔ σε κάποια από τις γνωστές γλώσσες προγραμματισμού.
• Διαχειριστής δεδομένων (data administrator – DA). Έχει τη διοικητική αρμοδιότητα και ευθύνη για την οργάνωση της βάσης δεδομένων και την απόδοση δικαιωμάτων πρόσβασης στους χρήστες.
• Διαχειριστής βάσης δεδομένων (database administrator – DBA). Λαμβάνει οδηγίες από τον διαχειριστή δεδομένων και είναι αυτός που διαθέτει τις τεχνικές γνώσεις και αρμοδιότητες για τη σωστή και αποδοτική λειτουργία του ΣΔΒΔ.
1.2.2 Ο υπεύθυνος διαχείρισης βάσεων δεδομένων
(DBA)
Ο υπεύθυνος διαχείρισης βάσεων δεδομένων (DBA) είναι το άτομο που παρέχει την απαιτούμενη τεχνική υποστήριξη για την υλοποίηση αυτών των αποφάσεων. Ο DBA είναι λοιπόν υπεύθυνος για το συνολικό έλεγχο του συστήματος σε τεχνικό επίπεδο. Γενικά ,αυτές οι λειτουργίες είναι οι εξής:
• Ορισμός του εννοιολογικού σχήματος. Αφού ο υπεύθυνος διαχείρισης δεδομένων καθορίσει τη λογική ή μερικές φορές εννοιολογική σχεδίαση της βάσης δεδομένων εντοπίζοντας τις σημαντικές οντότητες και άρα και τις σχετικές με αυτές πληροφορίες που θα τηρούνται, ο DBA δημιουργεί το αντίστοιχο εννοιολογικό σχήμα, χρησιμοποιώντας την εννοιολογική DDL(γλώσσα ορισμού δεδομένων).
• Ορισμός του εσωτερικού σχήματος. Αποφασίζει για τη φυσική σχεδίαση της βάσης δεδομένων, και δημιουργεί τον αντίστοιχο ορισμό αποθηκευτικής δομής, χρησιμοποιώντας την εσωτερική DDL. Ο DBA πρέπει επίσης να ορίσει και τη σχετική απεικόνιση μεταξύ του εσωτερικού και του εννοιολογικού σχήματος. Οι αντίστοιχες απεικονίσεις θα υπάρχουν και σε μορφή πηγαίου κώδικα και σε μορφή αντικειμένου κώδικα.
• Επαφή με τους χρήστες. Εξασφαλίζει ότι τα δεδομένα που χρειάζονται είναι διαθέσιμα. Γράφει τα απαραίτητα εξωτερικά σχήματα, χρησιμοποιώντας την κατάλληλη εξωτερική DDL ώστε να οριστεί η απεικόνιση ανάμεσα σε οποιοδήποτε δεδομένο εξωτερικό σχήμα και στο εννοιολογικό σχήμα. Συγχρόνως παρέχει συμβουλές για την σχεδίαση των εφαρμογών ,τεχνική εκπαίδευση, εντόπιση και επίλυση προβλημάτων.
• Ορισμός κανόνων ασφάλειας και ακεραιότηταςΟι κανόνες ασφάλειας και ακεραιότητας μπορούν να θεωρηθούν μέρος του εννοιολογικού σχήματος. Η εννοιολογική DDL θα πρέπει να διαθέτει λειτουργίες για τον καθορισμό τέτοιων κανόνων.
• Ορισμός διαδικασιών για τη λήψη εφεδρικών αντιγράφων και την ανάκαμψη Από τη στιγμή που μια επιχείρηση υιοθετεί ένα σύστημα βάσης δεδομένων, εξαρτάται σε κρίσιμο βαθμό από την επιτυχημένη λειτουργία αυτού του συστήματος. Σε περίπτωση που παρουσιαστεί μια αστοχία σε οποιοδήποτε μέρος της βάσης δεδομένων που μπορεί να οφείλεται είτε σε ανθρώπινο σφάλμα είτε σε κάποια αστοχία του υλικού ή του λειτουργικού συστήματος είναι απαραίτητο να μπορούν να αποκατασταθούν τα δεδομένα που επηρεάστηκαν, με ελάχιστη δυνατή καθυστέρηση και με τις ελάχιστες δυνατές επιπτώσεις στο υπόλοιπο σύστημα .Ο DBA θα πρέπει να ορίσει και να υλοποιήσει έναν κατάλληλο μηχανισμό ανάκαμψης.
Σύστημα διαχείρισης βάσεων δεδομένων (ΣΔΒΔ) (database management system - DBMS) είναι μια συλλογή από προγράμματα που επιτρέπουν στους χρήστες να δημιουργήσουν και να συντηρήσουν μία βάση δεδομένων. Επομένως, το ΣΔΒΔ είναι ένα γενικής χρήσης σύστημα λογισμικού που διευκολύνει τις διαδικασίες ορισμού, κατασκευής και χειρισμού βάσεων δεδομένων για διάφορες εφαρμογές.
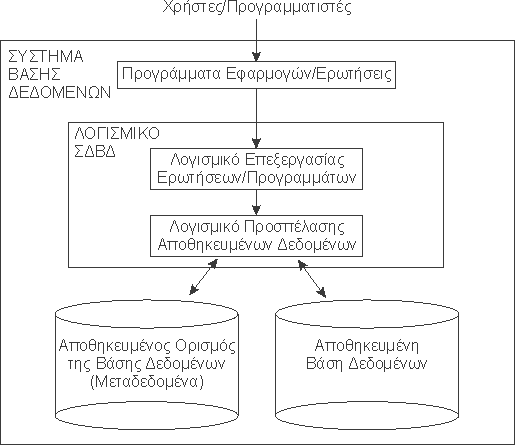
Εικόνα 1.1 : Σύστημα διαχείρισης βάσεων δεδομένων
Το ΣΔΒΔ παρέχει στους χρήστες και τις εφαρμογές που αναπτύσσουν οι προγραμματιστές ένα επίπεδο λογισμικού για την επεξεργασία ερωτήσεων και προγραμμάτων. Για την πρόσβαση στον ορισμό της βάσης και τα δεδομένα χρησιμοποιείται το επίπεδο προσπέλασης αποθηκευμένων δεδομένων.
Τα επιθυμητά χαρακτηριστικά ενός ΣΔΒΔ είναι τα ακόλουθα:
• μείωση πλεοναζόντων δεδομένων
• ευκολία στην ανάπτυξη νέων εφαρμογών
• μηχανισμοί ασφαλείας
• υποστήριξη δοσοληψιών (transactions)
• ανεξαρτησία δεδομένων από τις εφαρμογές τόσο στο φυσικό επίπεδο της αποθήκευσης, όσο και στις διαφορετικές παρεχόμενες όψεις
Η χρήση ΣΔΒΔ σε σχέση με αποθήκευση σε απλά αρχεία πλεονεκτεί:
• στην ασφάλεια δεδομένων
• στη διαφύλαξη της ακεραιότητας των δεδομένων
• στην ταυτόχρονη πρόσβαση από πολλούς χρήστες και εφαρμογές
• στην καταγραφή στοιχείων χρήσης
• στη ρύθμιση του τρόπου αποθήκευσης σε διαφορετικούς δίσκους και υπολογιστές
• στη ρύθμιση της οργάνωσης της αποθήκευσης των δεδομένων για την βελτιστοποίηση της απόδοσης (π.χ. χρήση δομών δέντρων)
• στη γρήγορη πρόσβαση στα δεδομένα
1.2.3 Οι
Πίνακες Βάσεων Δεδομένων (Database Tables)
Οι βάσεις δεδομένων (databases) περιέχουν αντικείμενα (objects) που ονομάζονται Πίνακες (Tables). Οι Εγγραφές (Records) των δεδομένων αποθηκεύονται σ’ αυτούς τους πίνακες. Οι Πίνακες αναγνωρίζονται με τα ονόματά τους, όπως "Persons", "Orders", "Suppliers" κ.ά.
Οι Πίνακες περιέχουν Στήλες (Columns) και Γραμμές (Rows) με δε-δομένα. Οι Γραμμές (Rows) περιέχουν εγγραφές (records), όπως μία εγγραφή για κάθε άτομο. Οι Στήλες (Columns) περιέχουν δεδομένα, όπως First Name, Last Name, Address και City.
1.2.3.1
Τα Στοιχεία ενός πίνακα
Τα δεδομένα μιας βάσης δεδομένων αποθηκεύονται (οργανώνονται) στις εξής στοιχειώδεις μορφές :
• Αρχείο (File), είναι ένα σύνολο από
πολλά παρόμοια στοιχεία (εγγραφές) της βάσης δεδομένων.
• Υπερ-Κλειδί (Super Key), είναι ένα πεδίο ή συνδυασμός περισσοτέρων πεδίων που χαρακτηρίζει μοναδικά μια εγγραφή.
• Υποψήφιο-Κλειδί (Candidate Key), είναι το υπερ-κλειδί με το λιγότερο αριθμό πεδίων που χαρακτηρίζουν μοναδικά μια εγγραφή.
1.3 Γενική Δομή Συστημάτων Βάσεων Δεδομένων
Τα συστατικά μέρη ενός συστήματος διαχείρισης βάσης δεδομένων (DBMS) είναι λειτουργικές μονάδες που συνεργάζονται μεταξύ τους όπως φαίνεται στην Εικόνα 2 και αναλαμβάνουν τον έλεγχο για την σωστή λειτουργία της βάσης.
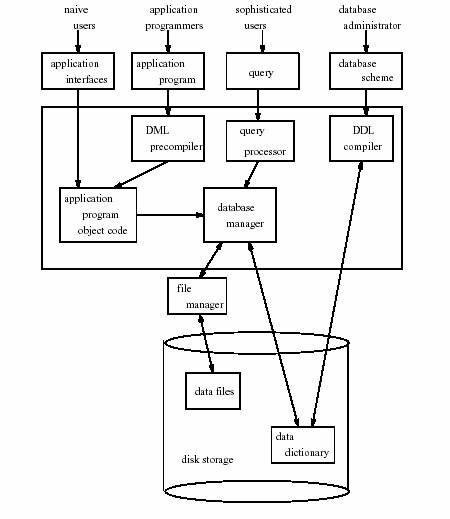
Εικόνα 1.2: Δομή συστημάτων βάσεων δεδομένων.
Για μερικές
λειτουργίες τους (π.χ. συστήματα αρχείων) μπορείτε
να ανατρέξετε και να ενημερωθείτε από τα
λειτουργικά συστήματα.
Τα λειτουργικά συστατικά μέρη ενός συστήματος Βάσεων Δεδομένων μπορούν να διαιρεθούν γενικά σε δύο μεγάλες κατηγορίες α. στα συστατικά του διαχειριστή αποθήκευσης και β. στα συστατικά του επεξεργαστή ερωτημάτων.
Α. Διαχειριστής Αποθήκευσης (Storage manager)
Είναι υπεύθυνος για την ανάκληση αποθήκευση,
ενημέρωση των δεδομένων της βάσης και παρέχει την διασύνδεση μεταξύ των
δεδομένων που έχουν αποθηκευθεί στον δίσκο και των ερωτημάτων που στέλνονται
στο σύστημα βάσης δεδομένων από την εκάστοτε εφαρμογή.
Ο διαχειριστής αρχείων (File manager): διαχειρίζεται την κατανομή του διαστήματος δίσκων και των δομών δεδομένων που χρησιμοποιούνται για να αντιπροσωπεύσουν τις πληροφορίες για δίσκος.
Διαχειριστής βάσεων δεδομένων (database manager): αποτελεί τη διεπαφή μεταξύ των προγραμμάτων χαμηλού επιπέδου δεδομένων και εφαρμογής καθώς και των ερωτήσεων.
Διαχειριστής
buffer (Buffer manager): είναι υπέυθυνος για την τροφοδοσία
των δεδομένων από τον δίσκο προς την κύρια μνήμη. Αποφασίζει για την
προτεραιότητα των δεδομένων που θα προσπελαστούν από την κύρια μνήμη. Αποτελεί
ένα από τα σημαντικότερα μέρη του συστήματος καθώς καλείται να διαχειριστεί
όγκο δεδομένων που τις περισσότερες φορές είναι πολύ μεγαλύτερος από το μέγεθος
της κύριας μνήμης.
Διαχειριστής συναλλαγών (transaction manager): είναι υπεύθυνος για την διατήρηση της βάσης σε συνεπή κατάσταση είναι μέτα από ακάκαψη από αστοχία του μέσου ή του συστήματος. Επίσης διατηρεί την συνέπεια της βάσης και κατά την διάρκεια ταυτόχρονων συναλλαγών από πολλαπλούς χρήστες χωρίς διενέξεις και προβλήματα.
Διαχειριστής ελέγχου ταυτότητας χρηστών και ακεραιότητας (Authorization and integrity control manager): είναι υπεύθυνος για τον έλεγχο της ακεραιότητας της βάσης δηλ. τα δεδομένα που εισάγονται στην βάση να είναι σωστά και σύμφωνα με τους αντίστοιχους κανόνες. Επίσης ελέγχει τους χρήστες εάν έχουν πρόσβαση στα δεδομένα.
Β.
Ο επεξεργαστής ερωτημάτων (query processor)
Μεταφράζει τις
δηλώσεις από μια γλώσσα διατύπωσης ερωτημάτων στις χαμηλού επιπέδου εντολές.
Ο προ-μεταγλωττιστής (precompiler
dml) μετατρέπει τις δηλώσεις
ορισμού δεδομένων που ενσωματώνονται σε ένα πρόγραμμα εφαρμογής στην κανονική
διαδικασία κλήσης σε μια γλώσσα οικοδεσποτών
(host). Ο
Precompiler αλληλεπιδρά με τον επεξεργαστή ερωτημάτων.
Ο μεταγλωττιστής ddl (ddl compiler) μετατρέπει τις δηλώσεις ddl σε ένα
σύνολο πινάκων που περιέχουν τα μεταδεδομένα και αποθηκεύονται σε ένα λεξικό δεδομένων.
Ο διαχειριστής αποθήκευσης χειρίζεται τις
διάφορες δομές δεδομένων ως μέρος του φυσικού χειρισμού των δεδομένων με
αποτέλεσμα την φυσική καταγραφή των δεδομένων σε μέσα αποθήκευσης.
Φυσική
αποθήκευση –Δίσκος (Physical storage)
Aρχεία
δεδομένων ( data files) αποθηκεύεται η ίδια τη βάση
δεδομένων σε μια περιοχή του δίσκου.
Λεξικό δεδομένων (data dictionary) πληροφορίες μεταδεδμένων σχετικές
με τη δομή της βάσης δεδομένων. Μεγάλη
έμφαση πρέπει να δοθεί στην ανάπτυξη ενός
καλού σχεδίου ώστε να υπαρχει αποδοτική εφαρμογή του λεξικού.
Ευρετήρια-Δείκτες (index) Ταξινομημένα πινακάκια των δεδομένων με την βοήθεια των ποίων επιτυγχάνεται η γρήγορη πρόσβαση στα δεδομένα της βάσης.
Συνοπτικά μπορούμε να παρουσιάσουμε την παρακάτω δεδνρική δομή των λειτουργικών μονάδων ενός συστήματος βάσεων δεδομένων και των συστατικών τους.
• Query processor
– DML compiler
– Embedded DML precompiler
– DDL interpreter
– Query processing unit
• Storage manager
– Authorization and integrity
control
– Transactions management
– File management
– Buffer management
• Physical storage
– Data files,
– Meta-data (data dictionary),
– Index, statistics
1.4
Εισαγωγή Στην Έννοια Client-Server
Computing
1.4.1
Client-server computing
Γενικά, το client-server computing αναφέρεται σε μια βασική αλλαγή στο στυλ των υπολογιστών, την αλλαγή από τα συστήματα που βασίζονται στα μηχανήματα στα συστήματα που βασίζονται στον χρήστη.
Ειδικότερα, ένα σύστημα client-server είναι ένα σύστημα στο οποίο το δίκτυο ενώνει διάφορους υπολογιστικούς πόρους, ώστε οι clients (ή αλλιώς front end) να μπορούν να ζητούν υπηρεσίες από έναν server (ή αλλιώς back end), ο οποίος προσφέρει πληροφορίες ή επιπρόσθετη υπολογιστική ισχύ.
Με άλλα λόγια, στο client-server μοντέλο, ο client θέτει μια αίτηση και ο server επιστρέφει μια ανταπόκριση ή κάνει μια σειρά από ενέργειες. Ο server μπορεί να ενεργοποιείται άμεσα για την αίτηση αυτή ή να προσθέτει την αίτηση σε μια ουρά. Η άμεση ενεργοποίηση για την αίτηση μπορεί, για παράδειγμα, να σημαίνει ότι ο server υπολογίζει έναν αριθμό και τον επιστρέφει αμέσως στον client. H τοποθέτηση της αίτησης σε μια ουρά μπορεί να σημαίνει ότι η αίτηση πρέπει να τεθεί σε αναμονή για να εξυπηρετηθεί. Ένα καλό παράδειγμα για αυτό είναι όταν εκτυπώνουμε ένα κείμενο σε ένα εκτυπωτή δικτύου. Ο server τοποθετεί την αίτηση σε μια ουρά μαζί με αιτήσεις εκτυπώσεων και από άλλους clients. Μετά επεξεργάζεται την αίτηση με βάση την σειρά προτεραιότητας, η οποία, σε αυτή την περίπτωση, καθορίζεται από τη σειρά με την οποία ο server παρέλαβε την απαίτηση.
Το client-server computing είναι πολύ σημαντικό, διότι επιτυγχάνει τα εξής:
• Αποτελεσματική χρήση της υπολογιστικής ισχύος.
• Μείωση του κόστους συντήρησης, δημιουργώντας συστήματα client-server που απαιτούν λιγότερη συντήρηση και κοστίζουν λιγότερο στην αναβάθμιση.
• Αύξηση της παραγωγικότητας, προσφέροντας στους χρήστες ξεκάθαρη πρόσβαση στις αναγκαίες πληροφορίες μέσω σταθερών και εύκολων στην χρήση διασυνδέσεων.
• Αύξηση της ευελιξίας και της δυνατότητας δημιουργίας συστημάτων που υποστηρίζουν πολλά περιβάλλοντα.
1.4.2
Server
Ο server απαντάει στις αιτήσεις που γίνονται από τους clients. Ένας client μπορεί να ενεργεί ως server εάν λαμβάνει, επεξεργάζεται αιτήσεις και τις στέλνει (για παράδειγμα, ένας σταθμός εργασίας που χρησιμοποιείται και ως server εκτυπώσεων από άλλους). Οι server δεν ξεκινάνε τις επικοινωνίες -περιμένουν τις αιτήσεις των clients.
Επιστρέφοντας στο παράδειγμα του server εκτυπώσεων ενός δικτύου, ο client ζητάει από τον server να εκτυπώσει ένα κείμενο σε έναν συγκεκριμένο εκτυπωτή και ο server προσθέτει την εκτύπωση σε μια ουρά και ενημερώνει τον client όταν το κείμενο εκτυπωθεί επιτυχημένα. Η διαδικασία του client μπορεί να ανήκει φυσικά στον ίδιο σταθμό εργασίας με την διαδικασία του server. Στο παράδειγμα εδώ, μια εντολή εκτύπωσης μπορεί να εκδίδεται στον server του σταθμού εργασίας του δικτύου, χρησιμοποιώντας την διαδικασία του server εκτυπώσεωνσε αυτόν τον σταθμό εργασίας.
Μια server μηχανή πρέπει να μπορεί να κάνει τα ακόλουθα :
• Να αποθηκεύει, να ανακτά και να προστατεύει πληροφορίες.
• Να επιθεωρεί τις αιτήσεις των clients.
• Να δημιουργεί εφαρμογές διαχείρισης πληροφοριών, όπως δημιουργία αντιγράφων, ασφάλεια κτλ.
• Να διαχειρίζεται πληροφορίες
1.4.2.1
Τύποι των Servers
Οι servers μπορούν να διαιρεθούν σε έξι τύπους:
• Server Εφαρμογών (Application servers).
• Server Πληροφοριών (Data servers).
• Server Υπολογισμών (Computing servers).
• Server Βάσεων Δεδομένων (Database servers).
• Server Πόρων ή Επικοινωνιών (Resource or Communications servers).
Ο τύπος του server που χρησιμοποιείται εξαρτάται από την απαιτούμενη εργασία. Επίσης, αυτοί οι έξι ρόλοι μπορούν να συνδυαστούν σε ένα σύστημα ή να διαιρεθούν σε περισσότερα. Για παράδειγμα, η ίδια μηχανή μπορεί να εξυπηρετήσει σαν ένας server εφαρμογών και ένας server βάσεων δεδομένων.
Οι περισσότεροι servers που χρησιμοποιούνται σήμερα στις επιχειρήσεις είναι servers αρχείων (file servers). Οι servers αρχείων επιτρέπουν στους clients να προσπελάσουν αρχεία και να μοιραστούν πληροφορίες και λογισμικό. Αυτοί οι servers είναι συνήθως ένας προσωπικός υπολογιστής ή ένα UNIX σύστημα με έναν επεξεργαστή. Πολλοί άνθρωποι μπορούν να προσπελάσουν τον server αρχείων την ίδια στιγμή, που σημαίνει ότι ο server έχει πολλαπλές μονάδες δίσκων και κάρτες προσαρμογής δικτύου, αλλά μόνο ένα άτομο μπορεί να προσπελάσει ένα συγκεκριμένο αρχείο εκείνη τη στιγμή.
Server Εφαρμογών (Application servers)
Οι servers εφαρμογών (application servers) τρέχουν λογισμικό εφαρμογών, που είναι πολύ σημαντικό όταν διανέμονται λογικές εφαρμογών μεταξύ του client και του server. H τοποθέτηση εφαρμογών στον server σημαίνει ότι αυτές οι εφαρμογές είναι διαθέσιμες σε πολλούς clients. Πολλοί clients μπορούν να χρησιμοποιήσουν τα RPCs( Remote Procedure Calls) για να θέσουν σε λειτουργία μια επεξεργασία στον server. Πολλοί servers εφαρμογών μπορούν ακόμα και να εργαστούν μαζί για να απαντήσουν στην απαίτηση του client. Κάθε server μπορεί να τρέξει ένα διαφορετικό λειτουργικό σύστημα σε μια διαφορετικήπλατφόρμα υλικού, αλλά αυτές οι λεπτομέρειες είναι ξεκάθαρες στον client -o client μπορεί να κάνει αιτήσεις χωρίς να υπολογίζει τον τύπο της μηχανής που θα ανταποκριθεί.
Server Πληροφοριών (Data servers)
Οι servers πληροφοριών (data severs) χρησιμοποιούνται μόνο για αποθήκευση και διαχείριση πληροφοριών και χρησιμοποιούνται σε συνδυασμό με servers υπολογισμών (compute servers). Αυτοί οι servers ερευνούν και ελέγχουν την αξιοπιστία των πληροφοριών, αλλά γενικά δεν μεταβιβάζουν μεγάλη ποσότητα πληροφοριών στο δίκτυο.
Server Υπολογισμών (Computing servers)
Οι servers υπολογισμών (compute servers) παίρνουν τις αιτήσεις των clients για πληροφορίες στον server πληροφοριών και μετά προωθούν τα αποτελέσματα των αιτήσεων πίσω στον client.
Server Βάσεων Δεδομένων (Database servers)
Οι servers βάσεων δεδομένων (database servers) είναι τυπικά client-server συστήματα, και έχουν να κάνουν την ίδια εργασία με αυτή που κάνουν οι servers πληροφοριών και υπολογισμών μαζί. Οι servers βάσεων δεδομένων τρέχουν DBMS (Database Management System) λογισμικό και πολύ πιθανό και κάποια λογική client-server εφαρμογή, που σημαίνει ότι αυτός ο τύπος του server χρειάζεται περισσότερη ισχύ. Τα DBMS προσφέρουν εξειδικευμένες υπηρεσίες: την δυνατότητα να ανακτά πληροφορίες και να διαχειρίζεται πληροφορίες. Οι servers που συνδυάζουν τις λειτουργίες του server βάσεων δεδομένων και του server εφαρμογών είναι επίσης γνωστοί ως server συναλλαγών (transaction servers).
Server Πόρων ή Επικοινωνιών (Resource or Communication servers)
Οι servers πόρων (resource servers), που περικλείουν τους servers επικοινωνιών (communications servers) επιτρέπουν σε πολλούς clients την προσπέλαση συγκεκριμένων πόρων, που είναι ουσιαστικά πολύ ακριβοί για να βρίσκονται σε έναν client. Για παράδειγμα, οι servers εκτυπώσεις (print servers) συνδέουν πολλούς clients με πολλούς εκτυπωτές. Οι servers επικοινωνιών συνδέουν απομακρυσμένα συστήματα. Άλλοι servers πόρων μπορούν να συνδέσουν clients με άλλες συσκευές, όπως πολυμέσα. Συνήθως από τη στιγμή που οι servers πόρων είναι συνδεδεμένοι σε μια συγκεκριμένη συσκευή, δεν απαιτείται τόσο πολύ ισχύ, όση αυτή των servers που προσφέρουν περισσότερο περιπλοκές υπηρεσίες.
Ένας εύκολος τρόπος για να ξεχωρίσουμε τους servers εφαρμογών, βάσεων δεδομένων και συναλλαγών είναι πώς ο client κάνει αιτήσεις στον server. Οι servers δέχονται τους παρακάτω τύπους απαιτήσεων από τους clients:
• Οι servers εφαρμογών ενεργούν κάπως πιο αποκεντρωμένα από τη βάση δεδομένων σε απάντηση του client.
• Οι servers βάσεων δεδομένων επιστρέφουν πληροφορία σαν απάντηση σε μια αίτηση του client, που γίνεται σε SQL.
• Οι servers συναλλαγών επιστρέφουν πληροφορία σαν απάντηση σε ένα μήνυμα που αποτελείται από ένα σύνολο εντολών SQL. Αυτό το σύνολο επιτυγχάνει ή αποτυγχάνει σαν μια μονάδα.
Από τους έξι τύπους, οι client-server εφαρμογές συνήθως χρησιμοποιούν πιο πολύ servers εφαρμογών, βάσεων δεδομένων και συναλλαγών ή κάποιο συνδυασμό αυτών των τριών.
1.4.2.2
Ο ρόλος του server
H client-server διαδικασία μπορεί να απλοποιηθεί στα παρακάτω βήματα:
1) Ο χρήστης στέλνει μια αίτηση ή ένα ερώτημα, μέσω του client, στον server.
2) server ακούει την αίτηση του client.
3) Από τη στιγμή που ο server ακούει την αίτηση, ελέγχει την δυνατότητα πρόσβασης του χρήστη.
4) Ο server επεξεργάζεται το ερώτημα.
5) Ο server επιστρέφει τα αποτελέσματα στον client.
6) client δέχεται τα αποτελέσματα και τα παρουσιάζει στον χρήστη.
Από αυτά τα έξι βήματα, ο server παίζει τέσσερις σημαντικούς ρόλους. Είναι φανερό ότι ο server είναι η καρδιά της client -server εφαρμογής. Ο server υπάρχει για να απαντήσει στις ανάγκες του client, και ο clientεξαρτάται από την αξιοπιστία και την έγκαιρη απάντηση του server.
Ο server πρέπει να εκτελέσει τις ακόλουθες λειτουργίες:
• Να ακούσει την αίτηση του client .
• Να ελέγξει την δυναμικότητα πρόσβασης του χρήστη.
• Να επεξεργαστεί την αίτηση.
• Να επιστρέψει τα αποτελέσματα.
Ο server δεν «εγκαινιάζει» καμιά ενέργεια. Αντίθετα, ο server περιμένει παθητικά να φτάσουν οι αιτήσεις του client μέσω του δικτύου. Ο server πρέπει πάντα να απαντάει στους clients, ακόμα και όταν πολλοί clients κάνουν ταυτόχρονες αιτήσεις.
Από την στιγμή που ο server δέχεται από τον client την απαίτηση, o server πρέπει να βεβαιωθεί ότι ο client είναι εξουσιοδοτημένος να λάβει την πληροφορία ή την απάντηση. Αν ο client δεν είναι εξουσιοδοτημένος, ο server απορρίπτει την αίτηση και στέλνει μήνυμα στον client. Εάν ο client είναι εξουσιοδοτημένος, ο server συνεχίζει και επεξεργάζεται την αίτηση.
Η επεξεργασία της αίτησης περιλαμβάνει την παραλαβή της αίτησης του client, την μετατροπή του σε μια μορφή που μπορεί ο server να χρησιμοποιήσει και την επεξεργασία της ίδιας της αίτησης.
Όταν η επεξεργασία ολοκληρώνεται, ο server στέλνει τα αποτελέσματα πίσω στον client. Μετά, ο client μπορεί να μεταφράσει και να χρησιμοποιήσει τις πληροφορίες.
Δεν υπάρχει προκαθορισμένος διαχωρισμός στις ευθύνες για τις client-server εφαρμογές. Ανάλογα με τις ανάγκες μας, μπορούμε και να διαχωρίσουμε την εφαρμογή. Το ισχυρό client μοντέλο δίνει περισσότερες λειτουργίες στον client, ενώ το ισχυρό server μοντέλο δίνει περισσότερες λειτουργίες στον server. Οι servers εφαρμογών και συναλλαγών τείνουν να είναι ισχυροί servers, ενώ οι servers βάσεων δεδομένων και αρχείων τείνουν να έχουν ισχυρούς clients.
Ανεξάρτητα του πώς διαχωρίζουμε την εφαρμογή, η βασική ευθύνη του server παραμένει η ίδια: να εξυπηρετεί τους clients που κάνουν αιτήσεις.
Ακούγοντας την αίτηση του client
Ο server δεν ξεκινάει καμιά αλληλεπίδραση με τον client, o server απλά περιμένει τον client για να κάνει την αίτηση του. Όταν ο client κάνει την αίτηση, ο server ανταποκρίνεται το συντομότερο δυνατό.
Η κάρτα προσαρμογής στο δίκτυο συνδέει φυσικά τον server, με το δίκτυο και καθορίζει εάν οι εισερχόμενες απαιτήσεις είναι κατανοητές για τον κόμβο του προσαρμογέα. Εάν ναι, το πρωτόκολλο τις αποδέχεται και τις αποκωδικοποιεί ώστε μετά ο server να μπορεί να τις επεξεργαστεί.
Ελέγχοντας την δυνατότητα πρόσβασης του χρήστη
Από την στιγμή που ο server δέχεται την αίτηση από τον client, o server πρέπει να βεβαιωθεί ότι ο χρήστης είναι εξουσιοδοτημένος να λάβει την πληροφορία ή την ανταπόκριση από το server. Εάν ο χρήστης δεν είναι εξουσιοδοτημένος, ο server απορρίπτει την αίτηση και στέλνει ένα μήνυμα στον client. Εάν ο χρήστης είναι εξουσιοδοτημένος, o server συνεχίζει και επεξεργάζεται την αίτηση.
Επεξεργάζοντας την αίτηση
Ο server πρέπει να είναι ικανός να ανταποκριθεί στην αίτηση του client αμέσως. Εάν πολλοί clients κάνουν αιτήσεις ταυτόχρονα, ο server πρέπει να είναι ικανός να βάζει σε προτεραιότητα τις αιτήσεις των clients, και να επεξεργάζεται πολλές αιτήσεις την στιγμή.
Από την στιγμή, που ο server επιβεβαιώνει ότι ο χρήστης είναι εξουσιοδοτημένος να κάνει αιτήσεις στον server, o server μπορεί να αποκαλύψει την απαίτηση και να την επεξεργαστεί.
Η αίτηση μπορεί να έχει μια από τις ακόλουθες τέσσερις μορφές:
• Μια απόμακρη αίτηση είναι μια απλή αίτηση για πληροφορίες από έναν απλό client.
• Μια απόμακρη συναλλαγή περιλαμβάνει πολλαπλές αιτήσεις για πληροφορίες από έναν απλό client.
• Μια κατανεμημένη συναλλαγή περιλαμβάνει πολλαπλές αιτήσεις για πληροφορίες από έναν απλό client, οι οποίες πληροφορίες ανήκουν σε πολλούς server.
• Μια κατανεμημένη αίτηση είναι μια συναλλαγή που σχηματίζεται από πολλαπλές αιτήσεις για πληροφορίες από πολλαπλούς clients, οι οποίες πληροφορίες ανήκουν σε πολλαπλούς servers.
Αυτές οι αιτήσεις πρέπει να περάσουν από το λεγόμενο ACID τεστ: Ατομικότητα (Atomicity), Συνέπεια (Consistency), Απομόνωση(Isolation) και Αντοχή (Durability). H ατομικότητα σημαίνει ότι ολόκληρη η συναλλαγή πρέπει να πετύχει ή να αποτύχει, δεν μπορεί να ολοκληρωθεί ως προς ένα κομμάτι της. Η συνέπεια σημαίνει ότι το σύστημα πάει από ένα σταθερό σημείο σε ένα άλλο σταθερό σημείο. Η απομόνωση σημαίνει ότι, από τη στιγμή που μια συναλλαγή ολοκληρώνεται με επιτυχία, τα αποτελέσματα της δεν είναι ορατά σε άλλες συναλλαγές. Η αντοχή σημαίνει ότι από τη στιγμή που η συναλλαγή ολοκληρώνεται με επιτυχία, δεσμεύεται μόνιμα από το σύστημα και επακόλουθες αποτυχίες δεν θα το επηρεάσουν. Εάν η συναλλαγή αποτύχει, το σύστημα οπισθοχωρεί στο σημείο που ήταν πριν προσπαθήσει να επεξεργαστεί την συναλλαγή.
Η διαχείριση της συναλλαγής ελέγχεται είτε από το DBMS είτε από το ΤΡΜ (Transaction Processing Manager). Οι διαχειριστές της συναλλαγής προστατεύουν την ακεραιότητα των πληροφοριών που είναι μια απόλυτη αξίωση. Ο server είναι υπεύθυνος για προστασία και την διατήρηση της ακρίβειας των πληροφοριών.
Όταν ο server τελειώνει την επεξεργασία των αποτελεσμάτων και είναι έτοιμος να επιστρέψει τα αποτελέσματα στον client, πρέπει να μορφοποιήσει τα αποτελέσματα και να τα στείλει με ένα τρόπο που μπορεί ο client να καταλάβει.
Ο server παραδίδει τις πληροφορίες στο πρωτόκολλο, που διευθύνει ένα πακέτο, μορφοποιεί τις πληροφορίες για να τις τοποθετήσει στο πακέτο και περνάει το πακέτο στο δίκτυο. Το δίκτυο μετά βεβαιώνεται ότι το πακέτο πηγαίνει στον client.
1.4.3
Client
Ο client είναι ο αιτών των υπηρεσιών. Ο client δεν μπορεί παρά να είναι ένας υπολογιστής. Οι υπηρεσίες που ζητούνται από τον client μπορεί να υπάρχουν στους ίδιους σταθμούς εργασίας ή σε απομακρυσμένους σταθμούς εργασίας που συνδέονται μεταξύ τους μέσω ενός δικτύου. Ο client ξεκινάει πάντα την επικοινωνία.
Τα συστατικά του client είναι πολύ απλά. Μια client μηχανή πρέπει να μπορεί να κάνει τα ακόλουθα:
• Να τρέχει το λογισμικό των γραφικών διεπαφών χρηστών (GUIs).
• Να δημιουργεί τις αιτήσεις για πληροφορίες και να τις στέλνει στον server.
• Να αποθηκεύει τις επιστρεφόμενες πληροφορίες.
Αυτές οι αιτήσεις καθορίζουν πόση μνήμη χρειάζεται, ποια ταχύτητα επεξεργασίας θα μπορούσε να βελτιώσει τον χρόνο ανταπόκρισης, και πόση χωρητικότητα αποθήκευσης απαιτείται.
Η διαδικασία client-server μπορεί να απλοποιηθεί στα ακόλουθα βήματα:
1) Ο χρήστης δημιουργεί μια αίτηση ή ένα ερώτημα.
2) Ο client μορφοποιεί το ερώτημα και το στέλνει στο server.
3) Ο server ελέγχει την δυνατότητα πρόσβασης του χρήστη.
4) Ο server επεξεργάζεται το ερώτημα και επιστρέφει τα αποτελέσματα.
5) Ο client λαμβάνει την ανταπόκριση και τη μορφοποιεί για τον χρήστη.
6) Ο χρήστης βλέπει και χειρίζεται την πληροφορία.
Πέρα από τα έξι αυτά βήματα, o client παίζει τέσσερις βασικούς ρόλους. Ο client είναι στην πραγματικότητα το κέντρο της client-server εφαρμογής. Ο χρήστης αλληλεπιδρά με τον client, o client ξεκινάει το μεγαλύτερο μέρος της ανάπτυξης της εφαρμογής, και ο server υπάρχει για να απαντάει στις ανάγκες του client.
Ο client εκτελεί τις ακόλουθες λειτουργίες :
• Προσφέρει μια εύκολη στη χρήση διασύνδεση χρηστών.
• Στέλνει απαιτήσεις.
• Δέχεται ανταποκρίσεις.
• Επιτρέπει στον χρήστη να βλέπει και να χειρίζεται τις πληροφορίες.
Για κάθε έναν από τους τέσσερις ρόλους, δηλαδή της παροχής μιας εύκολης στη χρήση διασύνδεσης, της αποστολής απαιτήσεων, της αποδοχής ανταποκρίσεων και της δυνατότητας στο χρήστη να παίρνει και να χειρίζεται πληροφορίες, ο client έχει συγκεκριμένες ευθύνες.
Η ανάπτυξη του client βασίζεται σε αρχές σχεδίασης εστιασμένες στον χρήστη. Αυτές οι αρχές είναι οι ακόλουθες:
• Διατηρεί τη διασύνδεση συνεπή, ώστε οι χρήστες να πάρουν μια οικεία όψη και αίσθηση από τις εφαρμογές και τις πλατφόρμες.
• Δεν ξεχνά ότι ο υπολογιστής εξυπηρετεί τον χρήστη. Ο χρήστης θα πρέπει να ελέγχει την σειρά των εργασιών. Ο υπολογιστής δεν θα πρέπει ποτέ να αγνοεί τον χρήστη, αλλά να διατηρεί τον χρήστη ενήμερο και να προσφέρει άμεσες απαντήσεις.
• Χρησιμοποιεί μεταφορές, τόσο φραστικές, όσο και οπτικές για να βοηθήσει τους χρήστες να αναπτύξουν θεμελιώδεις απεικονίσεις. Για παράδειγμα, η αποθήκευση αρχείων σε φακέλους στον υπολογιστή, ώστε ο χρήστης να μπορεί να συγκεντρωθεί στη δουλειά παρά να αποκαλύπτει πως λειτουργεί ο υπολογιστής.
• Δεν ζητάει από τον χρήστη να θυμάται εντολές. Οι εντολές μπορούν να είναι διαθέσιμες στον χρήστη για να τις επιλέγει, ώστε ο χρήστης να μπορεί να βασίζεται στην αναγνώριση, παρά στην απομνημόνευση.
• Επιτρέπει στην διασύνδεση να συγχωρεί τα λάθη του χρήστη. Οι καταστροφικές ενέργειες απαιτούν επιβεβαίωση, και οι χρήστες μπορούν να ανατρέψουν ή να ακυρώσουν την τελευταία ενέργεια.
Τα δίκτυα είναι τα πιο άγνωστα συστατικά στην εξίσωση των client-server. Γενικά οι άνθρωποι δεν ξέρουν πολλά για το πώς λειτουργούν τα δίκτυα στα συστήματα client-server, διότι τα συστήματα αυτά είναι σχεδιασμένα για να κάνουν τα δίκτυα διάφανα στον χρήστη. Επιπλέον, τα δίκτυα πρέπει να είναι αξιόπιστα. Πρέπει να μπορούν να υποστηρίζουν την επικοινωνία, να ελέγχουν σφάλματα και να ξεπερνούν αμέσως τις αποτυχίες.
Τα δίκτυα ελέγχονται από το λογισμικό λειτουργικών συστημάτων και διαχείρισης για να ελέγχουν τις υπηρεσίες επικοινωνίας του server και να προστατεύουν τα προγράμματα του client και του server από το να έχουν άμεση σύνδεση μεταξύ τους. Το λογισμικό διαχείρισης εστιάζεται στη παροχή αξιόπιστων υπηρεσιών, στην ελαχιστοποίηση των προβλημάτων στο δίκτυο και στην ελαχιστοποίηση των χρόνων «πτώσης» του δικτύου.
1.4.5
H Σύνδεση
Εκείνο που παίζει σημαντικό ρόλο στο client server computing είναι η σύνδεση του client με τον server, δηλαδή ουσιαστικά το δίκτυο στο οποίο εντάσσονται. Οι χρήστες θέλουν να αισθάνονται ότι οι υπηρεσίες που χρειάζονται οι ίδιοι, είναι διαθέσιμες και προσπελάσιμες στο δίκτυο, χωρίς να πρέπει να λαμβάνουν υπόψη μόνο την τεχνολογία. Όταν χρειάζεται να χρησιμοποιήσουν client-server εφαρμογές, είναι απαραίτητο να προσδιορίζεται το θέμα της σύνδεσης. Τα δίκτυα Lan προσφέρουν μεγαλύτερες ταχύτητες σε σχέση με το Internet γεγονός που είναι υψίστης σημασίας στον τρόπο σχεδιασμού των εφαρμογών .
1.4.5.1 Ισχυροί servers και ισχυροί
clients (fat servers και fat clients)
Εκτός από τον διαχωρισμό ανάλογα με τις υπηρεσίες που προσφέρουν, οι client-server εφαρμογές μπορούν να διακριθούν ανάλογα με το πώς η εφαρμογή κατανέμεται μεταξύ του client και του server. Το μοντέλο του ισχυρού server προσδίδει περισσότερες λειτουργίες στον server. To μοντέλο του ισχυρού client προσδίδει περισσότερες λειτουργίες στον client. Οι Web servers είναι παραδείγματα ισχυρών servers. Οι servers βάσεων δεδομένων και αρχείων είναι παραδείγματα ισχυρών clients.
Οι ισχυροί clients είναι οι πιο παραδοσιακοί τύποι των clients-servers. Το κύριο σώμα της εφαρμογής τρέχει στην πλευρά της εξίσωσης, που ανήκει στον client. Ταυτόχρονα στον server αρχείων και τον server βάσεων δεδομένων, οι clients γνωρίζουν το πώς είναι οργανωμένες και αποθηκευμένες οι πληροφορίες στην πλευρά του server. Προσφέρουν ευλυγισία και ευκαιρίες για δημιουργία εργαλείων που επιτρέπουν στους τελικούς χρήστες να δημιουργήσουν τις δικές τους εφαρμογές.
Οι εφαρμογές των ισχυρών servers είναι πιο εύκολο να διαχειρίζονται και να αναπτύσσονται στο δίκτυο διότι το μεγαλύτερο μέρος του κώδικα τρέχει στους servers. Οι ισχυροί servers προσπαθούν να ελαχιστοποιήσουν τις ανταλλαγές στο δίκτυο δημιουργώντας πιο ουσιώδη επίπεδα υπηρεσιών. Οι servers «συναλλαγών», για παράδειγμα, συμπυκνώνουν τη βάση δεδομένων. Αντί να εξάγουν ανεπεξέργαστες πληροφορίες, εξάγουν τις διαδικασίες που χειρίζονται αυτές τις πληροφορίες. Ο client στο μοντέλο του ισχυρού client προσφέρει το GUI και αλληλεπιδρά με τον server μέσω των RPCs (Remote Procedure Calls).
Κάθε client-server μοντέλο έχει την χρησιμότητά του. Σε πολλές περιπτώσεις, τα μοντέλα αλληλοσυμπληρώνονται και δεν είναι ασυνήθιστο να συνυπάρχουν σε μια εφαρμογή. Για παράδειγμα, μια εφαρμογή θα μπορούσε να απαιτεί έναν server, ο οποίος να συνδυάζει τους servers αρχείων, βάσεων δεδομένων και συναλλαγών.
1.4.5.2
Αρχιτεκτονικές Two-tier
(2-στρωμάτων) και Three-tier
(3-στρωμάτων) client-server
Πολλές φορές προτιμούνται να χρησιμοποιούνται όροι, όπως 2-tier, 3-tier client-server αρχιτεκτονικές αντί των όρων ισχυροί clients και ισχυροί servers. Αλλά ουσιαστικά αυτοί οι όροι βασίζονται στην ίδια βασική ιδέα. Έχουν να κάνουν με το πώς διαιρείται η client-server εφαρμογή σε λειτουργικές ενότητες, οι οποίες μετά μπορούν να ανατεθούν είτε στον client, είτε σε έναν ή περισσότερους servers.
Two-tier client-server computing
Οι client-server εφαρμογές πρώτης γενιάς εκτελούνταν γενικά με δυο λογικά στρώματα. Αυτό το μοντέλο έχει συχνά δυο στρώματα υλικού. Αυτή δεν είναι η περίπτωση όπου ο client και ο server τρέχουν ταυτόχρονα στον ίδιο υπολογιστή. Ο two-tier client-server διαιρεί την εφαρμογή σε δυο συγκεκριμένα τμήματα (τα tiers), όπου ένα τμήμα τρέχει στον client υπολογιστή και ένα ξεχωριστό τμήμα τρέχει στον server. Αξίζει να σημειωθεί ότι ο κώδικας του client και του server δεν ενημερώνει, ούτε καν γνωρίζει εάν αυτοί τρέχουν στον ίδιο υπολογιστή ή όχι. Επιπλέον, η εφαρμογή διαιρείται κατά μήκος του client και του server δηλαδή χωρίζεται σε 2 τμήματα που το καθένα τρέχει στον client και server αντίστοιχα.
Η ποσότητα της λογικής εφαρμογής που λειτουργεί στον client ή στον server καθορίζει εάν αυτό είναι αδύνατο ή ισχυρό. Το αδύνατο υποδηλώνει ότι παρουσιάζεται μικρή ανάπτυξη της εφαρμογής και το ισχυρό ότι παρουσιάζεται ένα μεγάλο τμήμα της λογικής της εφαρμογής. Υπάρχουν ποίκιλλες διαβαθμίσεις αδυνάτου και ισχυρού. Οι αδύνατοι client είναι ελκυστικοί όταν ο client υπολογιστής έχει περιορισμένη επίδοση. Οι two-tier clients-server εμφανίζονται να είναι πιο δύσκολο να αναπτυχθούν και να διατηρηθούν από ό,τι κανονικά προσδοκάται. Οι two-tier εφαρμογές δεν κλιμακώνουν καλά. Επίσης, τα εργαλεία των client-server πήραν χρόνο για να αναπτυχθούν.
Στην επόμενη σελίδα ακολουθεί ένα διάγραμμα όπου διαφαίνεται η διάρθωση μιας 2 tier εφαρμογής .
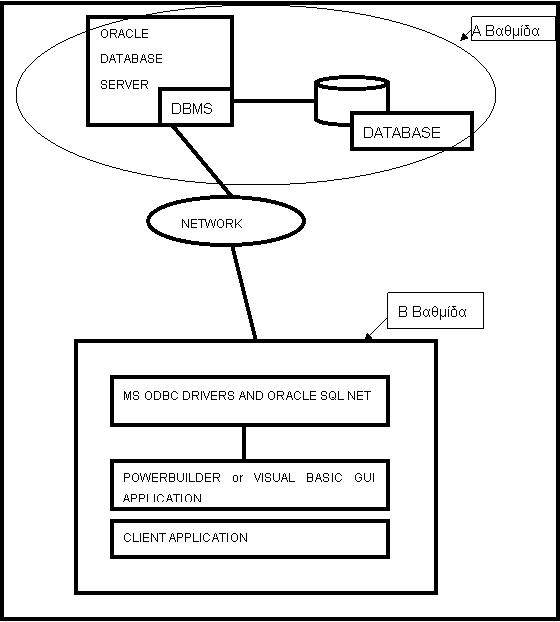
Εικόνα 1.3 : Αντιπροσωπευτικό παράδειγμα Client/Server(“TWO-TIER”) αρχιτεκτονικής
Three-tier Client Server Computing
Ο πιο πρόσφατος τύπος client-server computing που αναπτύσσεται είναι ο three-tier. Μερικοί άνθρωποι επίσης χρησιμοποιούν πολλαπλούς tier για να περιλάβουν οποιαδήποτε προσέγγιση που χρησιμοποιεί περισσότερους από δυο λογικούς tiers.
Μια πρωταρχική διαφορά μεταξύ two-tier και three-tier εφαρμογών είναι η επιπλέον επίστρωση λογισμικού στο server. Όπου οι two-tier εφαρμογές τείνουν να τοποθετούν την λογική στον client και να περνούν εγγραφές στη βάση δεδομένων (ισχυρό client μοντέλο) ή να περνούν δεδομένα στη βάση δεδομένων, όπου αποθηκευμένες διαδικασίες εκτελούν την λογική της εφαρμογής (αδύνατο client μοντέλο), οι three-tier εφαρμογές τείνουν να περνούν μήνυμα μεταξύ των client και των server τμημάτων του κώδικα της εφαρμογής. Το τμήμα του server εφαρμόζει τη λογική της εφαρμογής, κατόπιν την στέλνει στη βάση δεδομένων. Η λογική της εφαρμογής συνήθως καλείται «Business Rules» στη χώρο των client -server.
Το τμήμα του server της three-tier αρχιτεκτονικής προσθέτει κάτι σε όλη την πολυπλοκότητα της εφαρμογής. Ωστόσο υπάρχουν ορισμένα πλεονεκτήματα σε μια three-tier client-server προσέγγιση. Αυτά περιλαμβάνουν:
• Κλιμάκωση
• Γενικότερα πιο χαμηλά προβλήματα στα δίκτυα διανομής
• Ευλυγισία
Η κλιμάκωση βελτιώθηκε, διότι ο κώδικας του server και η βάση δεδομένων είναι χωρισμένα, μπορούν να ξεκινήσουν από ένα απλό «υπολογιστή-οικοδεσπότη» και αργότερα να χωριστούν. Πολλαπλές εφαρμογές server μπορούν να επικοινωνήσουν με μια κεντρική βάση δεδομένων ή μια εφαρμογή server μπορεί ακόμα να εξυπηρετήσει τους clients ενώ προσπελάζονται οι πολλαπλές βάσεις δεδομένων όσο το σύστημα αυξομειώνεται.
Τα χαμηλότερα προβλήματα στα δίκτυα απορρέουν από το πέρασμα μικρών μηνυμάτων στην εφαρμογή παρά από ολόκληρες εγγραφές πληροφοριών.
Η ευλυγισία κερδίζεται, διότι ο client, ο server και τα συστήματα βάσεων δεδομένων μπορούν το καθένα να αντικατασταθούν χωρίς να επηρεάζουν τα αλλά κομμάτια, δεδομένου ότι η διασύνδεση επίσης δεν αλλάζει. Για παράδειγμα, μετατρέποντας τη βάση δεδομένων από Sybase σε Oracle επηρεάζεται μόνο το τμήμα του server της εφαρμογής, όχι το client. Το να ξαναδιατυπώνεις έναν client από Visual Basic σε Delphi δεν έχει επίδραση στο υπόλοιπο τμήμα της εφαρμογής, δεδομένου ότι υπάρχει αλληλεπίδραση ανάμεσα στον κώδικα του client και τον κώδικα του server.
Πολλές από τις σημερινές εμπορικές εφαρμογές, που βασίζονται σε βάσεις δεδομένων,χρησιμοποιούν το three-tiered client-server μοντέλο για να κερδίσουν τη δυνατότητα αυξομείωσης και ευλυγισίας. Επίσης οι Web εφαρμογές είναι γενικά three-tier client-server εφαρμογές.
Δηλαδή τα 3 επίπεδα μια 3 tier εφαρμογής είναι συνήθως τα εξής :
1. Βάση Δεδομένων
2. Server
3. Client
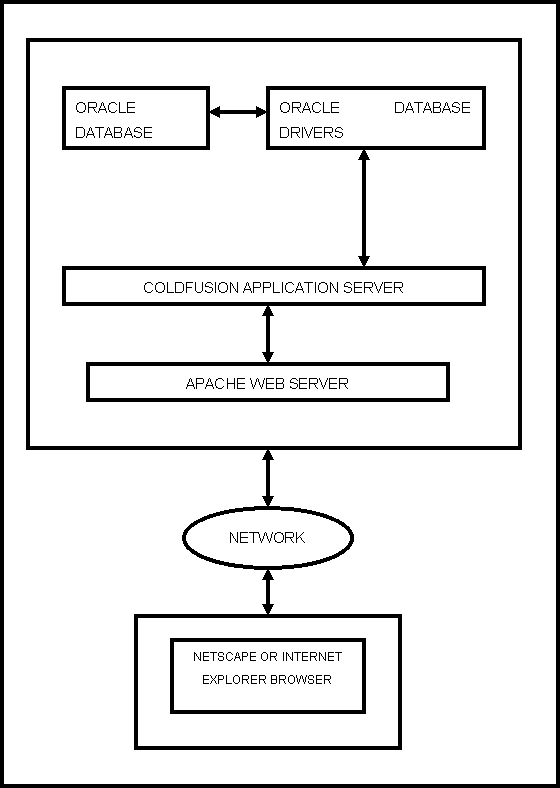
Εικόνα 1.4 :
Αντιπροσωπευτικό παράδειγμα Client/Server(“THREE-TIER”) αρχιτεκτονικής
Κεφάλαιο 2. Μοντέλο Οντοτήτων-Συσχετίσεων
2.1
ΕΙΣΑΓΩΓΗ
Το μοντέλο οντοτήτων-συσχετίσεων (entity-relationship model) προτάθηκε από τον P.P. Chen το 1976 για να περιγράψει με γραφικά σύμβολα τα δεδομένα ως οντότητες, συσχετίσεις και γνωρίσματα. Από τότε έχει αποτελέσει το αντικείμενο εκτεταμένων ερευνών με αποτέλεσμα τη διαρκή ανάπτυξή του. Σήμερα θεωρείται ένα από τα πιο σημαντικά εργαλεία κατασκευής εννοιολογικών μοντέλων βάσεων δεδομένων, σε περιβάλλοντα με ποικίλες απαιτήσεις, και αποτελεί βασική συνιστώσα μεθοδολογιών ανάπτυξης πληροφοριακών συστημάτων. Χρησιμοποιείται κατά το στάδιο του εννοιολογικού σχεδιασμού (conceptual design) και του λογικού σχεδιασμού της βάσης δεδομένων.
Ένα μοντέλο δεδομένων είναι ένα εργαλείο που επιτρέπει την αφαίρεση περιττών πληροφοριών από το σύνολο των πραγματικών δεδομένων. Κάθε μοντέλο βασίζεται σε ορισμένους κανόνες και διαδικασίες.
Ένα μοντέλο δεδομένων έχει τρεις βασικές συνιστώσες:
1.
Δομές (Structures): Είναι τα αντικείμενα του μικρόκοσμου.
- Πράξεις (operations): Είναι οι ενέργειες που γίνονται στις δομές
- Περιορισμοί (constraints): Είναι οι περιορισμοί που μπαίνουν πάνω στις δομές.
Άρα τα μοντέλα δεδομένων είναι μία συλλογή από εργαλεία για την περιγραφή δομών δεδομένων, τη σημασιολογία (semantics) δεδομένων και τους περιορισμούς δεδομένων. Υπάρχουν τρις διαφορετικές ομάδες που αντιστοιχούν στις αντίστοιχες φάσεις σχεδιασμού:
Ø Εννοιολογικά μοντέλα βασισμένα σε αντικείμενα
Ø
Λογικά
μοντέλα βασισμένα σε εγγραφές
Ø
Φυσικά
μοντέλα δεδομένων βασίζονται στις πραγματικές τιμές.
Παρακάτω, στην Εικόνα 2.1, φαίνονται σχηματικά οι τρις αυτές ομάδες.

Εικόνα 2.1 Βήματα σχεδιασμού μιας Εφαρμογής
Ένα από τα βασικότερα βήματα για την επίτευξη μιας σωστά σχεδιασμένης βάσης δεδομένων είναι η καταγραφή των απαιτήσεων και των περιορισμών της εφαρμογής. Αυτό επιτυγχάνεται με συνεντεύξεις από ομάδες ανθρώπων που είναι σχετικές με το αντικείμενο της εφαρμογής, με μελέτη του επιστημονικού υπόβαθρου της εφαρμογής και με σωστή ταξινόμηση και ομαδοποίηση όλων όσων συλλεχθούν. Το βήμα αυτό συχνά παραλείπεται λόγω βιασύνης και στο τέλος αντί για οικονομία χρόνου υπάρχει λανθασμένος σχεδιασμός με ελλιπή στοιχεία και χάσιμο πολύτιμου χρόνου στο τέλος για διορθώσεις και επανασχεδιασμό.
Αφού γίνει σωστά η συλλογή των απαιτήσεων και των απαραίτητων πληροφοριών υπάρχει η ανάγκη να μπουν όλες αυτές οι πληροφορίες σε μια τάξη, αφαιρώντας περιττές λεπτομέρειες και κρατώντας την ουσία. Την απαίτηση αυτή την καλύπτουν τα εννοιολογικά μοντέλα τα οποία με την βοήθεια σχηματικής αναπαράστασης βοηθούν τον αναλυτή να αποδώσει την σκέψη του με σύντομο και κατανοητό τρόπο. Τέτοιο μοντέλο είναι και μοντέλο Οντοτήτων και Συσχετίσεων που θα παρουσιάσουμε στις επόμενες παραγράφους.
Μετά τη σχηματική απόδοση που ολοκληρώνεται με τη χρήση των εννοιολογικών μοντέλων ακολουθεί η προσθήκη περισσότερων λεπτομερειών και η παρουσίαση των σχημάτων σε πιο λογικές δομές. Αυτό επιτυγχάνεται με τη χρήση των λογικών μοντέλων και στην περίπτωση των βάσεων δεδομένων, με το Σχεσιακό μοντέλο που θα επεξηγηθεί σε επόμενες παραγράφους. Το μοντέλο αυτό είναι επίσης αφαιρετικό αλλά περιέχει επιπλέον στοιχεία που βοηθούν στην κατανόηση του σχήματος της βάσης που θα αναπτυχθεί.
Τέλος πρέπει να γίνει σωστή επιλογή του συστήματος διαχείρισης βάσεων δεδομένων (RDBMS) στο οποίο θα γίνει ο φυσικός σχεδιασμός. Το βήμα αυτό είναι εξίσου σημαντικό όπως και τα προηγούμενα διότι εάν επιλεγεί λάθος RDBMS τα αποτελέσματα θα είναι δυσάρεστα με πολύ κόπο ανάπτυξης της εφαρμογής να πηγαίνει χαμένος. πχ. Να πρέπει έχουν πρόσβαση στην βάση πολλοί χρήστες ταυτόχρονα και η εφαρμογή να αναπτυχθεί σε ACCESS είναι λάθος.
2.2
Μοντέλο Ε-R
(Οντοτήτων Συσχετίσεων).
Το μοντέλο οντοτήτων-συσχετίσεων είναι βασισμένο στην αντίληψη ότι ο κάθε μικρόκοσμος που θα παρασταθεί με τη βάση δεδομένων αποτελείται από μια συλλογή από βασικά αντικείμενα τις οντότητες και συσχετίσεις μεταξύ αυτών των αντικειμένων.
μια οντότητα είναι
ένα διακριτό αντικείμενο.
κάθε οντότητα περιγράφεται από ένα σύνολο από ιδιότητες (γνωρίσματα)
μια συσχέτιση είναι
μία σύνδεση μεταξύ διάφορων οντοτήτων.
Το σύνολο των οντοτήτων ίδιου τύπου καλείται τύπος οντότητας και το σύνολο των
συσχετίσεων ίδιου τύπου καλείται τύπος
συσχέτισης.
Ένα άλλο απαραίτητο στοιχείο του διαγράμματος του ER είναι οι απεικονίσεις του πλήθους των οντοτήτων οι οποίες συμμετέχουν σε κάθε συσχέτιση.
Η εννοιολογική δομή μιας βάσης δεδομένων μπορεί να εκφραστεί γραφικά από ένα διάγραμμα οντοτήτων-συσχετίσεων το οποίο αποτελείται από :
- ορθογώνια: αντιπροσωπεύουν τους τύπους οντοτήτων.
- ρόμβοι: αντιπροσωπεύουν τους τύπους
συσχετίσεων μεταξύ των τύπων οντοτήτων.
- ελλείψεις: αντιπροσωπεύουν τις ιδιότητες.
- γραμμές: συνδέουν τους τύπους οντοτήτων με τα
γνωρίσματά τους και με τους τύπους συσχετίσεών τους.
Τόσο οι οντότητες
όσο και οι συσχετίσεις μπορούν να έχουν γνωρίσματα (attributes), τα οποία είναι ιδιότητες που τις
χαρακτηρίζουν. Τα είδη των γνωρισμάτων είναι τα απλά όπου η οντότητα έχει
ατομική τιμή για αυτό, τα σύνθετα όπου το γνώρισμα αποτελείται από περισσότερες
τιμές και τα πλειότιμα όπου οι πολλαπλές τιμές είναι το χαρακτηριστικό τους.
Βασικό
χαρακτηριστικό ενός τύπου οντοτήτων είναι το γνώρισμα κλειδί (key). Ένα γνώρισμα ή (σύνολο γνωρισμάτων) που
χαρακτηρίζει μοναδικά κάθε οντότητα (αντίστοιχα συσχέτιση) μέσα στον τύπο
οντοτήτων (συσχετίσεων) ονομάζεται υπέρ – κλειδί. Δεν μπορούν δηλαδή δύο
διαφορετικές οντότητες (συσχετίσεις) μέσα στον ίδιο τύπο να έχουν ίδια τιμή,
2.2.1
Γνωρίσματα
Τα γνωρίσματα περιγράφουν τις οντότητες και τις συσχετίσεις και μπορούν να παίρνουν τιμές. Ειδικότρα;
Απλά (Ατομικά) Γνωρίσματα
Τα γνωρίσματα αυτά (atomic attributes) όπως λέει και
το όνομά τους μπορούν να πάρουν ατομικές τιμές και συμβολίζονται με μία
έλλειψη.
Σύνθετα Γνωρίσματα (composite attributes) μπορούν να
χωριστούν σε μικρότερα τμήματα που αναπαριστάνουν
βασικότερα γνωρίσματα με τη δική του ανεξάρτητη σημασία το καθένα. Για
παράδειγμα, το γνώρισμα Διεύθυνση της οντότητας ΣΠΟΥΔΑΣΤΗΣ μπορεί να υποδιαιρεθεί σε Οδό, Αριθμό, Πόλη,
Νομό, και Ταχ_Κωδ . Γνωρίσματα που δεν
υποδιαιρούνται λέγονται απλά (simple)
ή ατομικά γνωρίσματα (atomic
attributes). Η τιμή ενός σύνθετου γνωρίσματος είναι η συνένωση των
τιμών των απλών γνωρισμάτων που το
αποτελούν.
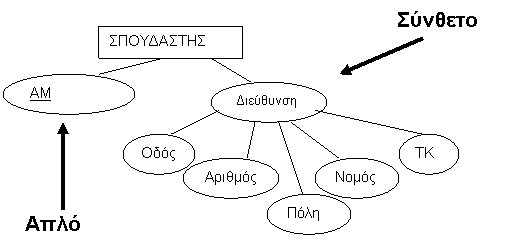
Εικόνα 2.2 . Σύνθετα και απλά γνωρίσματα.
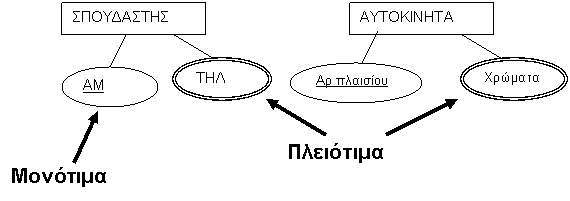
Μονότιμα έναντι
Πλειότιμων Γνωρισμάτων. Τα περισσότερα
γνωρίσματα έχουν μία και μόνο τιμή για μια συγκεκριμένη οντότητα· τέτοια
γνωρίσματα λέγονται μονότιμα (single-valued). Για παράδειγμα, ο Αριθμός Ταυτότητος και η
Ημερομηνία Γέννησης ενός ατόμου είναι μονότιμα γνωρίσματα. Σε μερικές περιπτώσεις ένα γνώρισμα μπορεί να
έχει ένα σύνολο από τιμές για την ίδια οντότητα -για παράδειγμα το γνώρισμα
Χρώματα για ένα αυτοκίνητο ή το
γνώρισμα ΤΗΛΕΦΩΝΟ για έναν άνθρωπο. Τα μονόχρωμα αυτοκίνητα έχουν μία
τιμή ενώ τα δίχρωμα αυτοκίνητα δύο τιμές για το γνώρισμα Χρώματα. Ομοίως, ένα άτομο μπορεί να μην έχει κανένα τηλέφωνο,
ένα άλλο άτομο να έχει έναν αριθμό τηλεφώνου
ενώ κάποιος άλλος να διαθέτει δύο
ή περισσότερα τηλέφωνα όπως
κινητό, τηλέφωνο οικίας, τηλέφωνο εργασίας, φαξ κλπ, Τέτοια γνωρίσματα
ονομάζονται πλειότιμα (multivalued) και συμβολίζονται με δύο ομόκεντρες ελλείψεις.
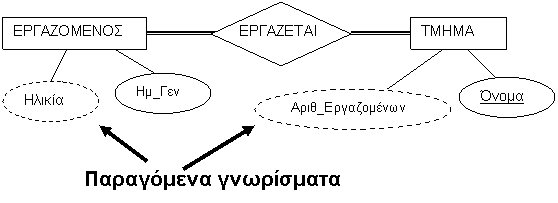
Παραγόμενα Γνωρίσματα. Σε η τιμή ενός γνωρίσματος
μπορέι να υπολογισθεί από την τη τιμή ενός άλλου γνωρίσματος. Π.χ Η τιμή
του γνωρίσματος Ηλικία μπορεί να υπολογιστεί από την τρέχουσα ημερομηνία και την τιμή του ΗμερομηνιαΓεννησης ενός
ατόμου. Επομένως το γνώρισμα Ηλικία λέγεται παραγόμενο γνώρισμα (derived
attribute). Οι τιμές μερικών
γνωρισμάτων μπορούν να υπολογιστούν από σχετιζόμενες οντότητες· για
παράδειγμα, ένα γνώρισμα Αριθμος_Υπαλληλων
ενός τμήματος μπορεί να παραχθεί μετρώντας τον αριθμό των υπαλλήλων που σχετίζονται με (εργάζονται στο)
τμήμα αυτό.
Γνωρίσματα-Κλειδιά
ενός Τύπου Οντοτήτων. Όπως θα
δούμε και παρακάτω ένας σημαντικός δομικός περιορισμός για τις οντότητες
ενός τύπου οντοτήτων είναι ο περιορισμός κλειδιού (key constraint) ή μοναδικότητας (uniqueness constraint) για τα
γνωρίσματα. Ένας τύπος οντοτήτων συνήθως
έχει κάποιο γνώρισμα του οποίου οι τιμές είναι μοναδικές για κάθε ξεχωριστή οντότητα. Ένα τέτοιο γνώρισμα
λέγεται γνώρισμα-κλειδί (key attribute) και οι τιμές του μπορούν να χρησιμοποιηθούν για να προσδιορίζεται κάθε οντότητα μονοσήμαντα. Για τους τύπους
οντοτήτων ΑΤΟΜΟ, ΕΡΓΑΖΟΜΕΝΟΣ ένα τυπικό γνώρισμα-κλειδί
είναι ο αριθμός ταυτότητας.

Μερικές φορές, διαφορετικά γνωρίσματα μαζί σχηματίζουν ένα κλειδί, με την έννοια ότι ο συνδυασμός των τιμών των γνωρισμάτων αυτών πρέπει να είναι διαφορετικός για κάθε ατομική οντότητα. Ένα σύνολο από γνωρίσματα που έχει αυτή την ιδιότητα μπορεί να ομαδοποιηθεί σε ένα σύνθετο γνώρισμα, το οποίο γίνεται γνώρισμα-κλειδί του τύπου οντοτήτων. Στο συμβολισμό των διαγραμμάτων ΟΣ, κάθε γνώρισμα-κλειδί έχει το όνομα του υπογραμμισμένο μέσα στην έλλειψη.
Μερικοί τύποι οντοτήτων έχουν περισσότερα από ένα γνωρίσματα-κλειδιά.
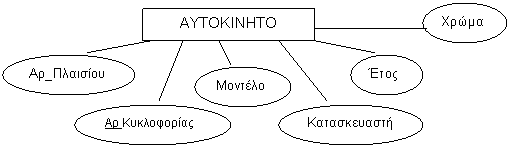
Για παράδειγμα, στον τύπο οντοτήτων
ΑΥΤΟΚΙΝΗΤΟ, τόσο ο Αριθμός_ Πλαισίου όσο και ο Αριθμός_Κυκλοφορίας
είναι από μόνος του ο καθένας κλειδί.
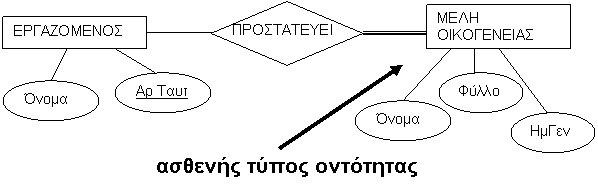
Από την άλλη πλευρά ένας τύπος οντότητας μπορεί να μην έχει κανένα κλειδί και σ' αυτή την περίπτωση ονομάζεται μη ισχυρός τύπος οντότητας (ασθενής τύπος). Για παράδειγμα σε μία εταιρεία θέλουμε για ασφαλιστικούς λόγους να τηρούμε στοιχεία για τα ΜΕΛΗ_ΟΙΚΟΓΕΝΕΙΑΣ ενός ΕΡΓΑΖΟΜΕΝΟΥ, για να υπολογίζουμε τα επιδόματα μισθού. Είναι προφανές ότι αν δεν υπάρχει εργαζόμενος δεν υπάρχουν και μέλη οικογένειας (δεν είναι ανεξάρτητη οντότητα) γι' αυτό και λέγεται μη ισχυρός τύπος οντότητας.
Σύνολα Τιμών (Πεδία ορισμού) των Γνωρισμάτων. Τα σύνολα τιμών δεν παρουσιάζονται στα διαγράμματα ΟΣ. Κάθε απλό γνώρισμα ενός τύπου οντοτήτων συνδέεται βέβαια με ένα σύνολο τιμών ή πεδίο ορισμού (domain), που προσδιορίζει τις επιτρεπτές τιμές που μπορεί να πάρει το γνώρισμα αυτό.
Null τιμές. Σε μερικές περιπτώσεις μια συγκεκριμένη οντότητα μπορεί να μην έχει καμιά δυνατή τιμή για ένα γνώρισμα. Για παράδειγμα, το γνώρισμα Αριθμος_Διαμερισματος μιας διεύθυνσης υφίσταται μόνον για διευθύνσεις κτιρίων με διαμερίσματα και όχι για άλλους τύπους οικιών όπως οι μονοκατοικίες. Παρόμοια, το γνώρισμα Τηλέφωνο πιθανόν να μην είναι γνωστό για κάποιο άτομο και να μην έχουμε προσωρινά την τιμή του τηλεφώνου του. Για τέτοιες περιπτώσεις δημιουργείται μια ειδική τιμή που λέγεται null. Η διεύθυνση μιας μονοκατοικίας θα είχε την τιμή null για το γνώρισμα Αριθμος_Διαμερισματος και ένα άτομο χωρίς τηλεφωνο θα είχε την τιμή null για το γνώρισμα τηλέφωνο.
2.2.2 Τύποι Συσχετίσεων
Ένας τύπος συσχέτισης (relationship
type) μεταξύ δύο τύπων οντοτήτων ορίζει
ένα σύνολο συνδέσεων -ή ένα σύνολο συσχετίσεων- μεταξύ αυτών των τύπων
οντοτήτων. Στα διαγράμματα ΟΣ οι τύποι συσχετίσεων παρουσιάζονται ως
ρόμβοι οι οποίοι συνδέονται με ευθείες γραμμές με τα παραλληλόγραμμα
που παριστάνουν τους συμμετέχοντες τύπους οντοτήτων. Το όνομα μιας συσχέτισης
γράφεται μέσα στον αντίστοιχο ρόμβο.

– Μεταξύ των ιδίων τύπων οντοτήτων πιθανόν να υπάρχουν
περισσότεροι του ενός τύποι συσχετίσεων (multiple relationships).
π,χ., Εργαζομενος-Εργαζεται-Τμήμα, Εργαζόμενος-Διευθύνει-Τμήμα.
–Μια συσχέτιση μπορεί να συνδέει δύο οντότητες που ανήκουν στον ίδιο τύπο οντοτήτων (αποκαλείται, ένας αναδρομικός τύπος συσχετίσεων - recursive relationship type)
π.χ., ο ΕΠΙΒΛΕΠΕΙ τύπος συσχετίσεων συνδέει ΕΡΓΑΖΟΜΕΝΟ (στον ρόλο αυτού που επιβλέπεται) με κάποιο άλλο ΕΡΓΑΖΟΜΕΝΟ (στον ρόλο του επιβλέποντα)


2.3
Δομικοί Περιορισμοί Στο Μοντέλο E-R.
Υπάρχουν δομικοί περιορισμοί (α) στους τύπους συσχετίσεων και (β) στα γνωρίσματα των τύπων οντοτήτων ή τύπων συσχετίσεων.
2.3.1
Βαθμός τύπου συσχετίσεων (relationship
degree)
Βαθμός (degree)
ενός τύπου συσχέτισης είναι το πλήθος των τύπων οντοτήτων που συμμετέχουν.
Άρα υπάρχουν τύποι συσχετίσεων μεταξύ 2 τύπων οντοτήτων, μεταξύ 3 τύπων
οντοτήτων, γενικά μεταξύ Ν τύπων οντοτήτων (N-ary relationship). Επομένως, ο
τύπος συσχέτισης. Ένας τύπος συσχέτισης βαθμού δύο λέγεται δυαδικός (binary), ένας βαθμού τρία τριαδικός
(ternary) και ένας βαθμού
τέσσερα τετραδικός.
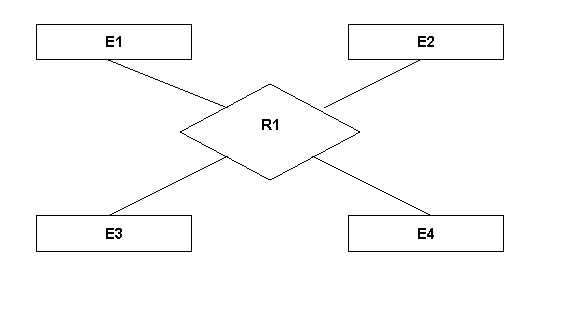
Εικόνα 2.3 : Τύπος συσχέτισης με βαθμό 4 όπου συμμετέχουν οι οντότητες Ε1..Ε4 στην συσχέτιση R1.
Οι συσχετίσεις μπορεί να είναι οποιουδήποτε βαθμού αλλά αυτές που εμφανίζονται πιο συχνά θα πρέπει να επιδιώκουμε είναι οι δυαδικές συσχετίσεις.
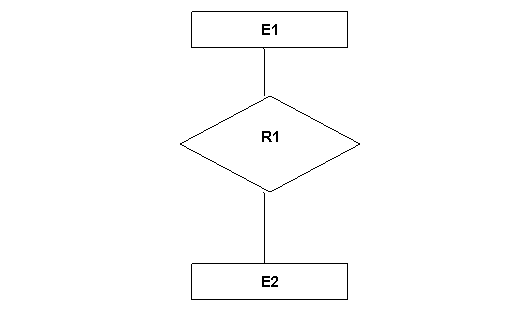
Εικόνα 2.4 : Δυαδική συσχέτιση μεταξύ των οντοτήτων Ε1και Ε2 στην συσχέτιση R1.
2.3.2
Περιορισμός Συμμετοχής και
Εξαρτήσεις Ύπαρξης.
Ο περιορισμός Συμμετοχής ορίζει αν η συμμετοχή μιας
οντότητας στον τύπο συσχέτισης είναι ολική (total) ή μερική (partial). Με άλλα
λόγια, αν όλες οι οντότητες του συγκεκριμένου τύπου οντοτήτων συμμετέχουν υποχρεωτικά
σ' ένα τύπο συσχετίσεων ή όχι. Για παράδειγμα, όλοι οι υπάλληλοι του τύπου
οντοτήτων ΕΡΓΑΖΟΜΕΝΟΣ
εργάζονται υποχρεωτικά σ' ένα ΤΜΗΜΑ, άρα έχουν ολική συμμετοχή στον τύπο
συσχετίσεων ΕΡΓΑΖΕΤΑΙ. Αντίθετα, δεν είναι όλοι διευθυντές τμημάτων, οπότε η συμμετοχή
του τύπου οντοτήτων ΕΡΓΑΖΟΜΕΝΟΣ στον τύπο συσχετίσεων ΔΙΕΥΘΥΝΕΙ είναι μερική. Η ολική συμμετοχή μερικές φορές λέγεται εξάρτηση
ύπαρξης (existence
dependency).
Η ολική συμμετοχή αναπαριστάται ως διπλή γραμμή που ενώνει το συμμετέχοντα τύπο οντοτήτων με την συσχέτιση, ενώ η μερική συμμετοχή ως απλή γραμμή.
Ένας εύκολος τρόπος για να διαπιστώσετε αν η συμμετοχή μιας οντότητας στην συσχέτιση είναι μερική ή ολική είναι η εξής:
Να ξεκινάτε την ερώτηση πάντα με τη λέξη ΟΛΕΣ οι οντότητες
που μελετάτε συμμετέχουν στην συσχέτιση; Αν ΝΑΙ είναι ΟΛΙΚΗ συμμετοχή αν ΟΧΙ
είναι ΜΕΡΙΚΗ συμμετοχή.
2.3.3
Λόγος πληθικότητας (cardinality)
Ο Λόγος πληθικότητας ενός τύπου συσχετίσεων ορίζει πόσες φορές μια οντότητα από έναν τύπο οντοτήτων μπορεί να εμπλακεί στο συγκεκριμένο τύπο συσχετίσεων.
Αποτελεί ένα από τα σημαντικότερα σημεία που πρέπει να δωθεί προσοχή κατά τον σχεδιασμό του διαγράμματος E-R, διότι ο λανθασμένος ορισμός του λόγου πληθικότητας μεταξύ δύο τύπων οντοτήτων θα έχει λανθασμένη συνέχεια κατά την μεταφορά του μοντέλου αυτού στο επόμενο βήμα που είναι το σχεσιακό μοντέλο.
Έχουμε τις εξής περιπτώσεις:
1:1 : μια οντότητα από τη μια πλευρά συνδέεται το πολύ με μια οντότητα από την άλλη πλευρά (συσχέτιση ένα-με-ένα)
1:Ν : μια οντότητα από την πρώτη πλευρά μπορεί να συνδέεται με περισσότερες από μια οντότητες από τη δεύτερη πλευρά Ν ενώ μια οντότητα από τη δεύτερη πλευρά συνδέεται το πολύ με μια οντότητα από την πρώτη πλευρά 1 (συσχέτιση ένα-με-πολλά). Ακριβώς το ανάποδο ισχύει στο λόγο πληθικότητας Ν:1.
Ν: Μ : μια οντότητα από τη μια πλευρά μπορεί να συνδέεται με περισσότερες από μια οντότητες από την άλλη πλευρά. (συσχέτιση πολλά-με-πολλά)
Οι λόγοι πληθικότητας για τις δυαδικές σχέσεις
παρουσιάζονται στα διαγράμματα ΟΣ με χρήση
των συμβόλων 1, Μ και Ν στους ρόμβους
Όπως στο παρακάτω παράδειγμα ο δυαδικός τύπος συσχέτισης
ΕΡΓΑΖΕΤΑΙ μεταξύ των ΤΜΗΜΑ και ΕΡΓΑΖΟΜΕΝΟΣ έχει λόγο πληθικότητας 1 :Ν
(ένα-με-πολλά), που σημαίνει ότι κάθε τμήμα μπορεί να σχετίζεται με πολλούς εργαζόμενους, αλλά ένας εργαζόμενος μπορεί
να σχετίζεται με (να εργάζεται σε)
ένα μόνο τμήμα.

Παράδειγμα ενός 1:1
δυαδικού τύπου συσχέτισης είναι ο ΔΙΕΥΘΥΝΕΙ που σχετίζει μια οντότητα
τμήματος με τον εργαζόμενο που διευθύνει το τμήμα
αυτό. Ο αντίστοιχος περιορισμός λόγου πληθικότητας αναπαριστά τον περιορισμό του μικρόκοσμου ότι ένας εργαζόμενος
μπορεί να διευθύνει μόνο ένα τμήμα
και ένα τμήμα έχει έναν και μόνο διευθυντή.

 Ο
τύπος συσχέτισης ΑΠΑΣΧΟΛΕΙΤΑΙ έχει λόγο
πληθικότητας Μ:Ν, επειδή ένας εργαζόμενος μπορεί να εργάζεται σε διαφορετικά
έργα και ένα έργο μπορεί να έχει πολλούς εργαζόμενους.
Ο
τύπος συσχέτισης ΑΠΑΣΧΟΛΕΙΤΑΙ έχει λόγο
πληθικότητας Μ:Ν, επειδή ένας εργαζόμενος μπορεί να εργάζεται σε διαφορετικά
έργα και ένα έργο μπορεί να έχει πολλούς εργαζόμενους.
Ένας εύκολος τρόπος για να κατανοήσετε τον λόγο πληθικότητας σε μια δυαδική συσχέτιση είναι ο εξής, να ξεκινάτε πάντα με τις παρακάτω ερωτήσεις:
ΜΙΑ οντότητα από την δεξιά πλευρά συσχετίζεται με πολλές οντότητες από την αριστερή πλευρά της συσχέτισης;
ΜΙΑ οντότητα από την αριστερή πλευρά συσχετίζεται με πολλές οντότητες από την δεξιά πλευρά της συσχέτισης;
![]() Αν η ερώτηση ισχύει μόνο από την μία πλευρά τότε
ο λόγος πληθικότητας είναι 1:Ν από την
πλευρά που ισχύει η ερώτηση.
Αν η ερώτηση ισχύει μόνο από την μία πλευρά τότε
ο λόγος πληθικότητας είναι 1:Ν από την
πλευρά που ισχύει η ερώτηση.
![]() Αν η ερώτηση ισχύει και από τις δύο πλευρές
τότε ο λόγος πληθικότητας είναι Ν:Μ .
Αν η ερώτηση ισχύει και από τις δύο πλευρές
τότε ο λόγος πληθικότητας είναι Ν:Μ .
![]() Αν η ερώτηση δεν ισχύει σε καμία από τις δύο
πλευρές τότε ο λόγος πληθικότητας είναι
1:1
Αν η ερώτηση δεν ισχύει σε καμία από τις δύο
πλευρές τότε ο λόγος πληθικότητας είναι
1:1
2.3.4
Δομικοί Περιορισμοί στα Γνωρίσματα
Βασικό χαρακτηριστικό ενός τύπου οντοτήτων ή συσχετίσεων είναι τα γνωρίσματα κλειδιά ή απλά κλειδιά (keys): Ένα γνώρισμα (ή σύνολο γνωρισμάτων) που χαρακτηρίζει μοναδικά κάθε οντότητα (αντίστοιχα, συσχέτιση) μέσα στον τύπο οντοτήτων (συσχετίσεων), δεν επιτρέπει δηλαδή δυο διαφορετικές οντότητες (συσχετίσεις) μέσα στον ίδιο τύπο να έχουν ίδια τιμή, ονομάζεται υπερ-κλειδί (super-key).
Κάθε γνώρισμα κλειδί θα φαίνεται υπογραμμισμένο στο Διάγραμμα Ο-Σ

Ορισμοί:
Ένα γνώρισμα (ή σύνολο γνωρισμάτων) ενός τύπου οντοτήτων/συσχετίσεων
για το οποίο κάθε οντότητα/συσχέτιση στο σύνολο πρέπει να έχει μοναδική τιμή
ονομάζεται υπερ-κλειδί (super-key).
Ένα
ελάχιστο υπερ-κλειδί (σύνολο γνωρισμάτων) που μπορεί να χαρακτηρίσει μοναδικά
τις εγγραφές ονομάζεται υποψήφιο κλειδί
(candidate key).
Μεταξύ των κλειδιών επιλέγουμε και ορίζουμε ένα υποψήφιο κλειδί ως τον προσδιοριστή του τύπου οντοτήτων και το ονομάζουμε πρωτεύον κλειδί (primary key)
Οι τύποι συσχετίσεων μπορεί επίσης να έχουν γνωρίσματα
παρόμοια με αυτά των τύπων οντοτήτων. Για
παράδειγμα, για να καταγράψουμε τις εβδομαδιαίες ώρες απασχόλησης ενός εργαζομένου σ' ένα έργο μπορούμε
να περιλάβουμε ένα γνώρισμα Ώρες στον τύπο συσχέτισης ΑΠΑΣΧΟΛΕΙΤΑΙ.
2.4
Μη Ισχυροί Τύποι Οντοτήτων
Οι τύποι οντοτήτων που δεν έχουν γνωρίσματα-κλειδιά από μόνοι τους λέγονται μη ισχυροί ή ασθενής τύποι οντοτήτων (weak entity types).
Σε αντίθεση, οι κανονικοί τύποι οντοτήτων που έχουν ένα γνώρισμα κλειδί ονομάζονται ισχυροί τύποι οντοτήτων. Οι οντότητες (π.χ. τα μέλη οικογένειας κάθε εργαζομένου) που ανήκουν σε κάποιον μη ισχυρό τύπο οντοτήτων προσδιορίζονται από τη σχέση τους με συγκεκριμένες οντότητες (π.χ. οι εργαζόμενοι) από έναν άλλο τύπο οντοτήτων, σε συνδυασμό με τις τιμές κάποιων γνωρισμάτων τους. Ονομάζουμε αυτόν τον άλλο τύπο οντοτήτων προσδιορίζοντα ή ιδιοκτήτη τύπο οντότητας (owner entity type) και τον τύπο συσχέτισης που συνδέει ένα μη ισχυρό τύπο οντοτήτων με τον ιδιοκτήτη του προσδιορίζουσα συσχέτιση (identifying relationship).
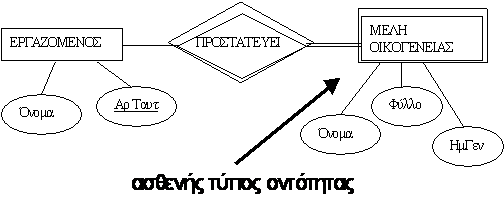
Ένας μη ισχυρός τύπος οντοτήτων έχει πάντα περιορισμό ολικής
συμμετοχής (εξάρτηση ύπαρξης) ως προς την προσδιορίζουσα του συσχέτιση, διότι μια μη ισχυρή οντότητα δεν μπορεί να
προσδιοριστεί χωρίς μια οντότητα-ιδιοκτήτη.
![]() ΤΥΠΟΣ
ΟΝΤΟΤΗΤΩΝ
ΤΥΠΟΣ
ΟΝΤΟΤΗΤΩΝ
![]() ΜΗ
ΙΣΧΥΡΟΣ ΤΥΠΟΣ ΟΝΤΟΤΗΤΩΝ
ΜΗ
ΙΣΧΥΡΟΣ ΤΥΠΟΣ ΟΝΤΟΤΗΤΩΝ

ΤΥΠΟΣ ΣΥΣΧΕΤΙΣΕΩΝ

ΤΥΠΟΣ ΠΡΟΣΔΙΟΡΙΖΟΥΣΑΣ ΣΥΣΧΕΤΙΣΗΣ
![]() ΓΝΩΡΙΣΜΑ
ΓΝΩΡΙΣΜΑ
![]()
ΓΝΩΡΙΣΜΑ-ΚΛΕΙΔΙ
![]()
ΠΛΕΙΟΤΙΜΟ ΓΝΩΡΙΣΜΑ

ΣΥΝΘΕΤΟ ΓΝΩΡΙΣΜΑ
![]()
ΠΑΡΑΓΟΜΕΝΟ ΓΝΩΡΙΣΜΑ

ΟΛΙΚΗ ΣΥΜΜΕΤΟΧΗ ΤΗΣ Ε2 ΣΤΗΝ R

ΛΟΓΟΣ ΠΛΗΘΙΚΟΤΗΤΑΣ 1:Ν
Εικόνα2.5 Σύνοψη του συμβολισμού των διαγραμμάτων
Οντοτήτων-Συσχετίσεων
Τα λογικά μοντέλα βασισμένα σε εγγραφές χρησιμοποιούνται για να περιγράψουν τα δεδομένα από τον εννοιολογικό σχεδιασμό στον λογικό σχεδιασμό. Αντίθετα από τα εννοιολογικά μοντέλα, τα λογικά μοντέλα καθορίζουν τη γενική λογική δομή της Βάσης Δεδομένων και παρέχουν μία υψηλότερου επιπέδου περιγραφή της υλοποίησης της.
Ονομάζονται έτσι επειδή η Βάση Δεδομένων είναι δομημένη σε εγγραφές διάφορων τύπων. Κάθε τύπος εγγραφής καθορίζει έναν σταθερό αριθμό πεδίων (γνωρίσματα - ιδιότητες). Κάθε πεδίο είναι συνήθως σταθερού μήκους (αυτό απλοποιεί την εφαρμογή).
Στο σχεσιακό μοντέλο
οι οντότητες και οι συσχετίσεις αντιπροσωπεύονται από μία συλλογή από
κανονικοποιημένους πίνακες (σχέσεις). Κάθε κανονικοποιημένος πίνακας έχει
διάφορες στήλες με μοναδικά ονόματα.
Οι σημαντικότεροι
από τους όρους που χρησιμοποιούνται με τα “αντικείμενα του σχεσιακού μοντέλου”
είναι η σχέση (relation) που
αντιστοιχεί σε εκείνο που μέχρι τώρα ονομαζόταν πίνακας, μία συστοιχία ή πλειάδα (tuple) αντιστοιχεί σε
μία γραμμή ενός τέτοιου πίνακα και ένα γνώρισμα (attribute) αντιστοιχεί σε μία στήλη-γνώρισμα. Το πλήθος των συστοιχιών ονομάζεται πληθικότητα (cardinality) και το πλήθος των γνωρισμάτων ονομάζεται βαθμός
(degree).
Το πρωτεύον κλειδί (primary key) είναι ένα μοναδικό αναγνωριστικό για τον
πίνακα. Δηλαδή, μία στήλη ή συνδυασμός στηλών που έχει την ιδιότητα οι τιμές
του να είναι μοναδικές.
Τέλος, ένα πεδίο ορισμού (domain) είναι μία δεξαμενή τιμών από την οποία τα
συγκεκριμένα γνωρίσματα των συγκεκριμένων σχέσεων αντλούν τις συγκεκριμένες
τιμές τους.
3.1
Μετατροπή Μοντέλου E–R Στο Σχεσιακό Μοντέλο
Από τη μία πλευρά, το μοντέλο ER διακρίνει τύπους οντοτήτων και τύπους συσχετίσεων (με τα γνωρίσματα τους) ενώ, από την άλλη, το Σχεσιακό μοντέλο υποστηρίζει μία δομή μόνο, τις σχέσεις (που έχουν και αυτές γνωρίσματα). Άρα η διαδικασία μετατροπής ενός διαγράμματος ER σε σχεσιακό σχήμα αφορά στη μετατροπή των τύπων οντοτήτων και συσχετίσεων (και των γνωρισμάτων τους) σε σχέσεις (πίνακες).
Υπάρχει ο γενικός κανόνας ότι για κάθε τύπο οντοτήτων δημιουργείται μία σχέση που παίρνει το όνομα του αντίστοιχου τύπου. Πέρα από αυτόν το γενικό κανόνα, παρακάτω αναλύονται οι περιπτώσεις για τους τύπους οντοτήτων, τους τύπους συσχετίσεων και τα γνωρίσματα.
3.1.1 Μετατροπή Τύπων Οντοτήτων.
Για κάθε ισχυρό τύπο οντοτήτων δημιουργεί ο χρήστης μία σχέση R με τα ίδια γνωρίσματα, ένα για κάθε απλό γνώρισμα της οντότητας. Αν η οντότητα έχει σύνθετα γνωρίσματα, στη σχέση R υπάρχει ένα γνώρισμα για κάθε απλό γνώρισμα που απαρτίζει το σύνθετο.
Για κάθε αδύνατο τύπο οντοτήτων Α που εξαρτάται από τον ισχυρό τύπο οντοτήτων Β δημιουργείται ένα σχήμα σχέσης R με τα εξής γνωρίσματα
(α) τα γνωρίσματα του Α, και
(β) τα γνωρίσματα του πρωτεύοντος κλειδιού του Β.
3.1.2 Μετατροπή Τύπων Συσχετίσεων.
Με βάση το λόγο
πληθικότητας, διακρίνονται τρεις περιπτώσεις:
Μ:Ν πολλά προς πολλά συσχετίσεις,
1:1 ένα προς ένα δυαδικές συσχετίσεις και
1:Ν ένα προς πολλά δυαδικές συσχετίσεις.
Για κάθε 1:Ν δυαδική (μη αδύναμη) συσχέτιση R μεταξύ δύο τύπων οντοτήτων που αντιστοιχούν στις σχέσεις Τ και S, δεν
δημιουργούμε νέα σχέση R. Στα ήδη υπάρχοντα γνωρίσματα της S προστίθενται: (α) τα γνωρίσματα της R, αν υπάρχουν, και (β) το πρωτεύον κλειδί της
T, το οποίο συμμετέχει ως
ξένο κλειδί στη σχέση S όπως
φαίνεται στην Εικόνα 3.1.

Εικόνα 3.1 Μετατροπή από Ε-R σε σχεσιακό για 1:N
Για κάθε Μ:Ν συσχέτιση R μεταξύ τύπων οντοτήτων
που αντιστοιχούν στις σχέσεις Τ, S, ο χρήστης δημιουργεί μία νέα σχέση (πίνακα) R με γνωρίσματα: (α) τα γνωρίσματα της R, αν υπάρχουν, και (β) τα γνωρίσματα του
πρωτεύοντος κλειδιού κάθε συμμετέχουσας σχέσης S και Τ,
τα οποία συμμετέχουν ως ξένα κλειδιά στη σχέση R όπως φαίνεται στην Εικόνα 3.2.

Εικόνα 3.2
Μετατροπή από Ε-R σε
σχεσιακό για M:N
Για κάθε 1:1 δυαδική (μη αδύναμη) συσχέτιση R μεταξύ δύο τύπων οντοτήτων που αντιστοιχούν στις σχέσεις T και S, δεν δημιουργείται νέα σχέση R αλλά επιλέγεται μία εκ των Τ και S, έστω την S. Στα ήδη υπάρχοντα γνωρίσματα της S προσθέτουμε: (α) τα γνωρίσματα της R, αν υπάρχουν, και (β) το πρωτεύον κλειδί της
T, το οποίο συμμετέχει ως
ξένο κλειδί στη σχέση S όπως
στην περίπτωση 1:Ν. Για την επιλογή T και S, κριτήριο είναι η ολική
συμμετοχή του ενός ή του άλλου τύπου οντοτήτων στη συσχέτιση. H σχέση που αντιστοιχεί στον τύπο οντοτήτων
που συμμετέχει ολικά στη συσχέτιση, είναι αυτή (η σχέση S παραπάνω) που επιλέγεται να “φιλοξενήσει” ως
ξένο κλειδί το πρωτεύον κλειδί της άλλης (S). Αν δε υπάρχει ολική συμμετοχή από μία
πλευρά, τότε προσπαθούμε να μην έχουμε πολλές null τιμές, οπότε επιλέγουμε να προσθέτουμε ξένο
κλειδί στη σχέση που αντιστοιχεί στον τύπο οντοτήτων με τη μεγαλύτερη συμμετοχή
στη συσχέτιση.
Για τις 1:1, 1:Ν και
Ν:1 δυαδικές (μη αδύναμες) μπορούμε, εναλλακτικά, να ακολουθήσουμε το γενικό
κανόνα (δημιουργία νέας σχέσης με ξένα κλειδιά, τα πρωτεύοντα κλειδιά των
εμπλεκομένων σχέσεων), ειδικά όταν δε υπάρχει ολική συμμετοχή από καμία πλευρά.
Στην περίπτωση αυτή, κερδίζουμε ως προς την εννοιολογική καθαρότητα και
πληρότητα αλλά χάνουμε ως προς την αποδοτικότητα χώρου και τη επίδοση. Συνήθως
δε επιλέγεται αυτός ο τρόπος αλλά η ειδική αντιμετώπιση τους, όπως
παρουσιάστηκε παραπάνω.
Η μετατροπή που
γίνεται στα γνωρίσματα από μοντέλο οντοτήτων και συσχετίσεων στο σχεσιακό
μοντέλο είναι η εξής
Ένα απλό γνώρισμα Α
γίνεται γνώρισμα της αντίστοιχης σχέσης,
ένα σύνθετο γνώρισμα
μετατρέπεται σε μία ομάδα γνωρισμάτων για την καινούρια σχέση που αποτελείται
από τα επί μέρους απλά γνωρίσματα.
Στα πλειότιμα
γνωρίσματα κατασκευάζεται μία σχέση R με γνωρίσματα το πρωτεύον κλειδί της αρχικής σχέσης καθώς και το
γνώρισμα του πλειότιμου πεδίου
Στη συνέχεια παρουσιάζεται ένα παράδειγμα , η μετατροπής ενός διαγράμματος ER σε σχεσιακό σχήμα.
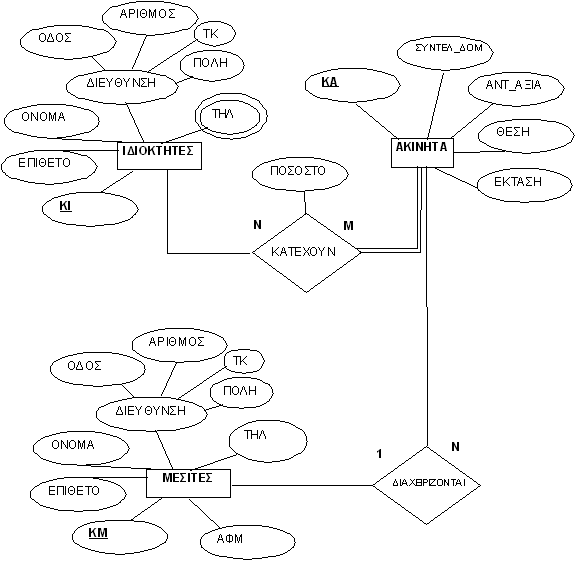
Μετατρέψτε το παρακάτω διάγραμμα E-R σε σχεσιακό σχήμα. Το διάγραμμα αναφέρεται σε Ιδιοκτήτες που κατέχουν ακίνητα σε διαφορετικό ποσοστό τα οποία ακίνητα τα διαχειρίζονται μεσίτες.
Λύση
Κάθε οντότητα θα γίνει πίνακας δηλ. σε πρώτο βήμα θα δημιουργηθούν οι πίνακες ΙΔΙΟΚΤΗΤΕΣ, ΑΚΙΝΗΤΑ, ΜΕΣΙΤΕΣ.
Στη συνέχεια οι συσχετίσεις που είναι Ν:Μ θα γίνουν νέοι πίνακες, δηλ. θα δημιουργηθεί ο πίνακας ΚΑΤΕΧΟΥΝ που έχει το ίδιο όνομα με την συσχέτιση.
Ακολουθεί η μετατροπή της συσχέτισης ΔΙΑΧΕΙΡΙΖΟΝΤΑΙ που είναι 1:Ν. Σε αυτή την περίπτωση το πρωτεύον κλειδί του πίνακα ΜΕΣΙΤΕΣ θα γίνει ξένο κλειδί στον πίνακα ΑΚΙΝΗΤΑ.
Τέλος για τα πλειότιμα γνωρίσματα θα δημιουργηθούν νέοι πίνακες όπως για το πεδίο ΤΗΛ ιδιοκτήτη θα γίνει νέος πίνακας με ξένο κλειδί το πρωτεύον κλειδί του πίνακα ΙΔΙΟΚΤΗΤΕΣ.
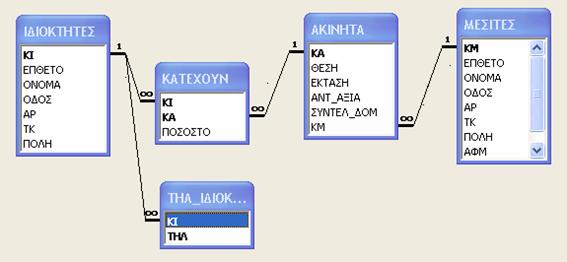
Οι ολικές συμμετοχές προαναγγέλλουν ότι τα ξένα κλειδιά που συμμετέχουν στη συσχέτιση θα παίρνουν υποχρεωτικά τιμές. Δηλ. αν δεν καταχωρηθεί τιμή σε αυτό το πεδίο δεν πρόκειται να προχωρήσει σε επόμενο πεδίο για καταχώριση τιμής. Τέτοια πεδία θα είναι το ΚΑ στον πίνακα ΚΑΤΕΧΟΥΝ.
Κεφάλαιο 4. Θεωρία Κανονικοποίησης
Είδαμε στα προηγούμενα κεφάλαια ότι το σχεσιακό μοντέλο αποτελείται από σχέσεις που δημιουργούνται από γνωρίσματα. Μία σχέση είναι ένα σύνολο από γνωρίσματα με τιμές για κάθε γνώρισμα τέτοιες ώστε να ισχύουν οι παρακάτω ιδιότητες
- Κάθε όνομα γνωρίσματος είναι μοναδικό.
- Όλες οι τιμές κάθε γνωρίσματος είναι ίδιου τύπου (ή πεδίου ορισμού).
- Κάθε τιμή γνωρίσματος είναι ατομική (μία τιμή και όχι ομάδα πολλών τιμών).
- Τα γνωρίσματα δεν έχουν διάταξη από τα αριστερά προς τα δεξιά..
- Οι συστοιχίες (σειρές) δεν έχουν διάταξη από επάνω προς τα κάτω.
- Δεν υπάρχουν δύο ίδιες σειρές (συστοιχίες) σε μία σχέση.
Από τη συζήτηση της μοντελοποίησης με το μοντέλο οντοτήτων-συσχετίσεων είδαμε ότι μία οντότητα τυπικά αντιστοιχεί σε μία σχέση και ότι τα γνωρίσματα της οντότητας γίνονται γνωρίσματα της σχέσης.
Η διαδικασία που ακολουθούμε είναι η ακόλουθη:
1 Συγκεντρώνουμε τις απαιτήσεις της επιχείρησης και των χρηστών.
2 Σχεδιάζουμε το μοντέλο οντοτήτων-συσχετίσεων βασιζόμενο στις παραπάνω απαιτήσεις
3 Μετατρέπουμε το διάγραμμα οντοτήτων-συσχετίσεων της επιχείρησης σε ένα σύνολο από σχέσεις (πίνακες) με το σχεσιακό μοντέλο.
4 Κανονικοποιούμε τις σχέσεις για να απομακρύνουμε τυχόν ανωμαλίες ενημέρωσης-διαγραφής-εισαγωγής στοιχείων.
5 Υλοποιούμε τη βάση δεδομένων δημιουργώντας ένα πίνακα για κάθε κανονικοποιημένη σχέση.
Προβλήματα Τροποποιήσεων
Μόλις το μοντέλο οντοτήτων-συσχετίσεων μετατραπεί σε σχέσεις μπορεί να ανακαλύψουμε ότι μερικές σχέσεις δεν καθορίζονται σωστά. Έτσι μπορεί να εμφανιστούν κάποια προβλήματα όπως:
Ανωμαλίες διαγραφής: διαγράφοντας μία σχέση κάποιες πληροφορίες που συνδέονται με μία άλλη σχέση χάνονται και αυτές.
Ανωμαλίες Εισαγωγής: Για να εισάγουμε μία καινούργια σχέση απαιτείται να έχουμε πληροφορίες από δύο ή περισσότερες οντότητες-αυτή η κατάσταση μπορεί να μην είναι εφαρμόσιμη.
Οι παραπάνω ανωμαλίες εισαγωγής ή διαγραφής σχέσεων προκύπτουν επειδή σε μία σχεσιακή βάση δεδομένων δεν μπορεί να υπάρχει σχέση που δεν σχετίζεται με καμία άλλη.
4.1
Συναρτησιακές Εξαρτήσεις
Έστω R μια σχέση και έστω ότι τα Χ και Υ είναι τυχαία υποσύνολα του συνόλου των γνωρισμάτων της R. Τότε, λέμε ότι το Υ είναι συναρτησιακά εξαρτημένο από το Χ, ή συμβολικά (διαβάζεται "το Χ καθορίζει συναρτησιακά το Υ, ή απλώς Χ à Υ), εάν και μόνο εάν η κάθε τιμή Χ της σχέσης R αντιστοιχεί σε μία ακριβώς τιμή Υ της R
Μία συναρτησιακή εξάρτηση περιγράφει τη συσχέτιση (ΧàΥ) μεταξύ γνωρισμάτων της ίδιας σχέσης. Ένας δεύτερος ορισμός μπορεί να διατυπωθεί ως εξής:
Ένα γνώρισμα Υ είναι συναρτησιακά εξαρτώμενο από ένα γνώρισμα Χ αν και μόνο αν κάθε τιμή του Χ σχετίζεται με μία και μόνο μία τιμή του Υ. Δηλαδή ένα γνώρισμα είναι συναρτησιακά εξαρτώμενο από ένα άλλο αν μπορούμε να χρησιμοποιήσουμε την τιμή του ενός για να προσδιορίσουμε την τιμή του άλλου (να βρούμε την τιμή του μέσα στη σχέση).
Με άλλα λόγια, δύο οποιεσδήποτε συστοιχίες της R που συμφωνούν στην τιμή Χ, συμφωνούν επίσης στην τιμή Υ
Οι συναρτησιακές εξαρτήσεις διαθέτουν πλούσιο σύνολο από ενδιαφέρουσες τυπικές ιδιότητες. Με την χρήση αυτών των ιδιοτήτων γίνεται αντιμετώπιση των προβλημάτων με τυπικό και αυστηρό τρόπο
Με τον όρο εξάρτηση, αποδίδονται δύο διαφορετικοί όροι, οι όροι dependence και dependency ο 1ος όρος θα έπρεπε να σημαίνει εξάρτηση και ο 2ος το εξαρτημένο αντικείμενο για μας και οι δύο αγγλικοί όροι θα σημαίνουν εξάρτηση.
Αν το Χ είναι υποψήφιο κλειδί της σχέσης R — και ειδικότερα, αν είναι το πρωτεύον κλειδί — τότε όλα τα γνωρίσματα Υ της σχέσης R πρέπει κατ’ ανάγκη να είναι συναρτησιακά εξαρτημένα από το Χ.
Μάλιστα, αν η σχέση R ικανοποιεί τη συναρτησιακή εξάρτηση Α à Β και το Α δεν είναι υποψήφιο κλειδί, τότε η R θα έχει κάποιον πλεονασμό (redundancy).
Για παράδειγμα στη σχέση ΕΡΓΑΖΟΜΕΝΟΙ το Όνομα-Εργαζομένου είναι συναρτησιακά εξαρτώμενο από τον Αριθμό-Ταυτότητας επειδή ο Αριθμό-Ταυτότητας μπορεί να χρησιμοποιηθεί για να προσδιορισθεί μοναδικά η τιμή του Ονόματος του Εργαζομένου. Τότε ο Αριθμό-Ταυτότητας ονομάζεται προσδιοριστικό (ή ορίζουσα).
Εδώ θα χρησιμοποιήσουμε λοιπόν το σύμβολο à για να δείχνουμε μερικές τέτοιες συναρτησιακές
εξαρτήσεις (το σύμβολο à
διαβάζεται "προσδιορίζει
συναρτησιακά")
ΚωδΦοιτητή à Κατεύθυνση-σπουδών
ΚωδΦοιτητή, Μάθημα, Εξάμηνο à Βαθμός
ΚωδΜαθήματος, Τμήμα à Καθηγητής, Αίθουσα, Αριθμός-φοιτητών
Μοντέλο, Τρόπος-Πληρωμής,
φόρος à Τιμή
αυτοκινήτου
Τα γνωρίσματα στα αριστερά
ονομάζονται προσδιοριστικά. Αν γενικά ΧàΑ σημαίνει ότι το Χ προσδιορίζει το Α.
4.1.2 Μεταβατική συναρτησιακή εξάρτηση
Υποθέστε ότι έχουμε μια σχέση R με τρία γνωρίσματα, Α, Β, και C, τέτοια ώστε οι συναρτησιακές εξαρτήσεις Α à Β και Β àC να ισχύουν και οι δύο στην R.
Τότε ισχύει επίσης η συναρτησιακή εξάρτηση A àC στην R.
Εδώ, η συναρτησιακή εξάρτηση Α àC είναι ένα παράδειγμα μεταβατικής συναρτησιακής εξάρτησης
Λέμε ότι η C εξαρτάται από την Α μεταβατικά, μέσω της Β.
Κλειδιά και μοναδικότητα
Όπως εξηγήσαμε και σο Κεφ.1 με τη λέξη κλειδί ονομάζουμε ένα ή περισσότερα γνωρίσματα που προσδιορίζουν μοναδικά μία συστοιχία (πλειάδα ή ολοκληρωμένη εγγραφή)
Η επιλογή των κλειδιών εξαρτάται πάντα από τη συγκεκριμένη εφαρμογή. Οι χρήστες της εφαρμογής μπορούν να προσφέρουν οδηγίες ως προς το ποια γνωρίσματα θα δημιουργήσουν ένα κατάλληλο κλειδί. Επειδή δεν είναι δυνατόν δύο σχέσεις να έχουν ακριβώς τις ίδιες τιμές, ένα υποψήφιο κλειδί μπορεί αν αποτελείται από όλα τα γνωρίσματα μίας σχέσης. Ένα κλειδί προσδιορίζει συναρτησιακά μία συστοιχία και δεν είναι όλα τα προσδιοριστικά να είναι κλειδιά.
4.1.3 Κανόνες συναγωγής –αξιώματα- του Armstrong
Έστω ότι Α, Β, και C είναι τυχαία υποσύνολα του συνόλου των γνωρισμάτων της δεδομένης σχέσης R, και έστω ο συμβολισμός ΑΒ σημαίνει την ένωση των Α και Β. Τότε:
Ανακλαστικότητα (reflexivity): αν το Β είναι υποσύνολο του Α, τότε Α à Β.
Επαύξηση (augmentation): αν Α àΒ, τότε AC àBC.
Μεταβατικότητα (transitivity): αν Α àΒ και Β àC, τότε Α àC.
Μερικοί ακόμα κανόνες μπορούν να προκύψουν από τους τρεις προηγούμενους :
Αυτοκαθορισμός (self-determination): A àA.
Ανάλυση (decomposition): αν Α àBC, τότε Α àΒ και Α àC.
Ένωση (union): αν Α àΒ και Α àC, τότε Α àBC.
Σύνθεση (composition): αν Α àΒ και C àD, τότε AC àBD.
4.2 Κανονικοποίηση-Κανονικές Μορφές
Για τον καλύτερο σχεδιασμό μιας βάσης δεδομένων, οι πίνακες που απαρτίζουν μια βάση πρέπει να ελέγχονται σύμφωνα με κάποιους γενικούς κανόνες ώστε να υπάρχει μια ενιαία αντιμετώπιση στον σχεδιασμό για όλους τους προγραμματιστές. Για τον λόγο αυτό οι σχέσεις/ πίνακες μπορούν να υπάγονται σε μία ή περισσότερες κατηγορίες (ή κλάσεις) που ονομάζονται Κανονικές Μορφές (ΚΜ-normal forms-NF).
Κανονική Μορφή: Ονομάζεται μία κλάση σχέσεων απαλλαγμένων από συγκεκριμένα προβλήματα τροποποιήσεων.
Οι κανονικές Μορφές που θα εξηγήσουμε παρακάτω έχουν ονόματα όπως:
- Πρώτη κανονική μορφή (1NF-1ΚΜ)
- Δεύτερη κανονική μορφή (2NF-2ΚΜ)
- Τρίτη κανονική μορφή (3NF-3ΚΜ)
- Boyce-Codd κανονική μορφή (BC NF-ΚΜ)
- Τέταρτη κανονική μορφή (4NF-4ΚΜ)
- Πέμπτη κανονική μορφή (5NF-5ΚΜ)
- Κανονική μορφή πεδίου ορισμού- κλειδιού (Domain-Key/NF)
Αυτές οι κανονικές μορφές είναι αθροιστικές. Μία σχέση που βρίσκεται σε Τρίτη κανονική μορφή είναι επίσης και σε δεύτερη και σε πρώτη.
Οι τρεις πρώτες κανονικές μορφές (1ΚΜ, 2ΚΜ, 3ΚΜ) ορίστηκαν από τον Codd. Όλες οι κανονικοποιημένες σχέσεις είναι σε 1ΚΜ. Με άλλα λόγια, "κανονικοποιημένη" και "σε 1ΚΜ" σημαίνει ακριβώς το ίδιο πράγμα. Μερικές σχέσεις 1ΚΜ είναι επίσης σε 2ΚΜ, και μερικές σχέσεις 2ΚΜ είναι επίσης σε 3ΚΜ. Το σκεπτικό των ορισμών του Codd ήταν ότι η 2ΚΜ είναι "πιο επιθυμητή" από την 1ΚΜ, και ότι η 3ΚΜ είναι με τη σειρά της πιο επιθυμητή από την 2ΚΜ. Αυτό σημαίνει ότι σχεδιαστής της βάσης δεδομένων θα πρέπει γενικά να στοχεύει σε μια σχεδίαση που να έχει σχέσης σε 3ΚΜ, και όχι απλώς σε 2ΚΜ ή σε 1ΚΜ.
Ο Fagin όρισε την τέταρτη κανονική μορφή. Μετέπειτα και πάλι ο Fagin όρισε άλλη μία κανονική μορφή, την κανονική μορφή προβολής–σύζευξης (projection join), που αργότερα έγινε γνωστή και ως πέμπτη κανονική μορφή (5ΚΜ). 'Όπως φαίνεται μερικές σχέσεις που είναι σε ΚΜ-BC είναι επίσης σε 4ΚΜ, και μερικές σχέσεις που είναι σε 4ΚΜ είναι επίσης σε 5ΚΜ.
4.2.1
Πρώτη κανονική
μορφή (1NF-1ΚΜ)
Η Πρώτη κανονική μορφή θεωρείται γενικώς να είναι μέρος του ορισμού μιας σχέσης.
Μία σχέση βρίσκεται σε πρώτη κανονική μορφή αν ικανοποιεί όλες τις ιδιότητες του ορισμού της σχέσης:
![]() Κάθε όνομα γνωρίσματος (στήλης) είναι μοναδικό.
Κάθε όνομα γνωρίσματος (στήλης) είναι μοναδικό.
![]() Όλες οι τιμές κάθε γνωρίσματος είναι ίδιου τύπου
(ή πεδίου ορισμού).
Όλες οι τιμές κάθε γνωρίσματος είναι ίδιου τύπου
(ή πεδίου ορισμού).
![]() Κάθε τιμή γνωρίσματος είναι ατομική (μία τιμή
και όχι ομάδα πολλών τιμών).
Κάθε τιμή γνωρίσματος είναι ατομική (μία τιμή
και όχι ομάδα πολλών τιμών).
![]() Τα γνωρίσματα δεν έχουν διάταξη από τα αριστερά
προς τα δεξιά..
Τα γνωρίσματα δεν έχουν διάταξη από τα αριστερά
προς τα δεξιά..
![]() Οι συστοιχίες (σειρές) δεν έχουν διάταξη από
επάνω προς τα κάτω.
Οι συστοιχίες (σειρές) δεν έχουν διάταξη από
επάνω προς τα κάτω.
![]() Δεν υπάρχουν δύο ίδιες σειρές (συστοιχίες) σε
μία σχέση.
Δεν υπάρχουν δύο ίδιες σειρές (συστοιχίες) σε
μία σχέση.
Εάν υπάρχει καθορισμένο κλειδί για τη σχέση τότε ικανοποιείται η απαίτηση της μοναδικότητας των συστοιχιών (σειρών).
Ένας πίνακας σε πρώτη κανονική μορφή λέγεται κανονικοποιημένος πίνακας και τότε και μόνο τότε αντιστοιχεί σε μία σχέση (οι σχέσεις του σχεσιακού μοντέλου είναι στην 1η κανονική μορφή ). Μια γενικότερη συμβουλή για να καταλάβει κάποιος πότε ένας πίνακας δεν βρίσκεται σε πρώτη κανονική μορφή, θα πρέπει να προσέξει ώστε να μην υπάρχουν επαναλαμβανόμενα πεδία.
Τα βήματα που πρέπει να ακολουθηθούν ώστε να επέλθει ένας πίνακας με επαναλαμβανόμενα πεδία σε 1ΚΜ, είναι το σπάσιμο του αρχικού πίνακα σε δύο επί μέρους πίνακες. Ο ένας θα περιλαμβάνει τα βασικά στοιχεία του πίνακα και ο δεύτερος τα ονόματα των πεδίων που επαναλαμβάνονται μαζί με το πρωτεύον κλειδί του πρώτου πίνακα.
Ο παρακάτω πίνακας βρίσκεται σε 1ΚΜ;
ΣΠΟΥΔΑΣΤΕΣ (ΑΜ, ΕΠΙΘΕΤΟ, ΟΝΟΜΑ, ΤΗΛ, ΟΔΟΣ, ΑΡ, ΤΚ, ΠΟΛΗ, ΚΩΔ_ΜΑΘ1,ΜΑΘΗΜΑ1, ΒΙΒΛΙΟ1, ΒΑΘΜΟΣ1…, ΚΩΔ_ΜΑΘν, ΜΑΘΗΜΑν, ΒΙΒΛΙΟν ΒΑΘΜΟΣν)
Τι θα κάνανε ώστε να επέλθει σε 1ΚΜ;
Λύση
Ο πίνακας δεν είναι σε 1ΚΜ διότι έχει μια ομάδα επαναλαμβανόμενων πεδίων και έρχεται σε αντίθεση με τον πρώτο όρο που πρέπει να έχει ένας πίνακας για να είναι σε 1ΚΜ που λέει ότι το όνομα κάθε γνωρίσματος είναι μοναδικό.
Τα βήματα που θα ακολουθηθούν για να επέλθει σε 1ΚΜ είναι να τον σπάσουμε σε δύο επί μέρους πίνακες ως εξής :
ΣΠΟΥΔΑΣΤΕΣ (ΑΜ, ΕΠΙΘΕΤΟ, ΟΝΟΜΑ, ΤΗΛ, ΟΔΟΣ, ΑΡ, ΤΚ, ΠΟΛΗ)
ΜΑΘΗΜΑΤΑ_ΒΑΘΜΟΙ (ΚΩΔ_ΜΑΘ, ΑΜ, ΜΑΘΗΜΑ, ΒΙΒΛΙΟ ΒΑΘΜΟΣ)
4.2.2
Δεύτερη κανονική
μορφή (2NF-2ΚΜ)
Μία σχέση βρίσκεται σε δεύτερη κανονική μορφή εάν κάθε ένα από τα γνωρίσματά της που δεν είναι κλειδιά προσδιορίζονται από ολόκληρο το πρωτεύων κλειδί και όχι μόνο από ένα τμήμα του.
Οι σχέσεις που έχουν μόνο ένα γνώρισμα σαν πρωτεύων κλειδί βρίσκονται αυτόματα και στη δεύτερη κανονική μορφή.
Αυτός είναι ένας λόγος για τον οποίο χρησιμοποιούμε συχνά τεχνητά αναγνωριστικά σαν κλειδιά.
Η λύση που ακολουθείται όπως και σε όλες τις περιπτώσεις που ένας πίνακας δεν είναι κανονικοποιημένος, είναι το σπάσιμο του πίνακα σε επιμέρους πίνακες.
Στον έναν πίνακα πελιλαμβάνονται τα πεδία του κλειδιού και τα πεδία που εξαρτώνται και περιγράφουν όλο το σύνθετο κλειδί.
Στον άλλο πίνακα μπαίνουν τα πεδία που εξαρτώνται και περιγράφουν μέρος από το σύνθετο κλειδί καθώς και το μέρος του σύνθετου κλειδιού.
Ελέγξτε τους πίνακες που προέκυψαν από το Παράδειγμα 1. αν είναι σε 2ΚΜ.
ΣΠΟΥΔΑΣΤΕΣ (ΑΜ, ΕΠΙΘΕΤΟ, ΟΝΟΜΑ, ΤΗΛ, ΟΔΟΣ, ΑΡ, ΤΚ, ΠΟΛΗ)
ΜΑΘΗΜΑΤΑ_ΒΑΘΜΟΙ (ΚΩΔ_ΜΑΘ, ΑΜ, ΜΑΘΗΜΑ, ΒΙΒΛΙΟ, ΒΑΘΜΟΣ)
Λύση
Κατ’ αρχήν εξετάζουμε το πρώτο πίνακα ΣΠΟΥΔΑΣΤΕΣ. Αυτός ο πίνακας είναι σε 2ΚΜ γιατί έχει ένα πεδίο ως πρωτεύον κλειδί. Οπότε όλα τα υπόλοιπα πεδία που δεν είναι κλειδιά προσδιορίζονται από ολόκληρο το πρωτεύον κλειδί.
Στον δεύτερο πίνακα όμως ΜΑΘΗΜΑΤΑ_ΒΑΘΜΟΙ παρατηρούμε ότι το πρωτεύον κλειδί είναι σύνθετο και αποτελείται από δύο πεδία τον Κωδικό μαθήματος και τον Αριθμό μητρώου του σπουδαστή ( ΚΩΔ_ΜΑΘ, ΑΜ). Οι συναρτησιακές εξαρτήσεις που προκύπτουν είναι οι παρακάτω:
ΚΩΔ_ΜΑΘ, ΑΜ à ΒΑΘΜΟΣ
ΚΩΔ_ΜΑΘ à ΜΑΘΗΜΑ
ΚΩΔ_ΜΑΘ à ΒΙΒΛΙΟ
Παρατηρούμε ότι οι δύο τελευταίες συναρτησιακές εξαρτήσεις παραβιάζουν τον κανόνα για τη δεύτερη κανονική μορφή.
Το επόμενο βήμα είναι ο διαχωρισμός του πίνακα ΜΑΘΗΜΑΤΑ_ΒΑΘΜΟΙ σε δύο πίνακες:
Οπότε προκύπτουν οι παρακάτω σχέσεις.
ΣΠΟΥΔΑΣΤΕΣ (ΑΜ, ΕΠΙΘΕΤΟ, ΟΝΟΜΑ, ΤΗΛ, ΟΔΟΣ, ΑΡ, ΤΚ, ΠΟΛΗ)
ΜΑΘΗΜΑΤΑ_ΒΑΘΜΟΙ (ΚΩΔ_ΜΑΘ, ΑΜ, ΒΑΘΜΟΣ)
ΜΑΘΗΜΑΤΑ (ΚΩΔ_ΜΑΘ, ΜΑΘΗΜΑ, ΒΙΒΛΙΟ)
4.2.3
Τρίτη κανονική
μορφή (3NF-3ΚΜ)
Μία σχέση βρίσκεται σε Τρίτη κανονική μορφή εάν είναι σε
δεύτερη και δεν περιέχει μεταβατικές εξαρτήσεις.
Θεωρήστε για παράδειγμα τη σχέση R που έχει γνωρίσματα τα Α, Β και Γ. Εάν
ΑàΒ
και ΒàΓ
τότε θα ισχύει και ΑàΓ. Αν το πεδίο Α προσδιορίζει συναρτησιακά το
πεδίο Β. Το πεδίο Β προσδιορίζει συναρτησιακά το πεδίο Γ. Τότε το πεδίο Α
προσδιορίζει συναρτησιακά και το πεδίο Γ. Δεν θέλουμε τέτοιες εξαρτήσεις σε μία
σχέση.
Για να λύσουμε το πρόβλημα σε περιπτωση που υπάρχει μεταβατική συναρτησιακή εξάρτηση σε έναν πίνακα σπάμε τον πίνακα σε δύο άλλους πίνακες. Ο ένας πίνακας περιέχει τα σταθερά στοιχεία και ο άλλος περιλαμβάνει τα πεδία με την συναρτησιακές εξαρτήσεις συν το πεδίο κλειδί του αρχικού πίνακα.
Ο παρακάτω πίνακας είναι κανονικοποιημένος ως προς την 3ΚΜ; Εξηγήστε αν υπάρχουν μεταβατικές εξαρτήσεις και σε ποια πεδία. Δώστε λύση ώστε να εξαλειφτεί το πρόβλημα.
ΣΠΟΥΔΑΣΤΕΣ (ΑΜ, ΕΠΙΘΕΤΟ, ΟΝΟΜΑ, ΤΗΛ, ΕΠΙΘΕΤΟ_ΚΗΔΕΜΟΝΑ ΟΝ_ ΚΗΔΕΜΟΝΑ, ΕΠΑΓΓΕΛΜΑ_ ΚΗΔΕΜΟΝΑ, ΤΗΛ_ ΚΗΔΕΜΟΝΑ, ΟΔΟΣ, ΑΡ, ΤΚ, ΠΟΛΗ …..)
Λύση:
Ο πίνακας ΣΠΟΥΑΔΣΤΕΣ δεν είναι κανονικοποιημένος ως προς 3ΚΜ διότι περιέχει μεταβατικές εξαρτήσεις στα παρακάτω πεδία:
ΑΜ à ΕΠΙΘΕΤΟ_ ΚΗΔΕΜΟΝΑ, ΟΝ_ ΚΗΔΕΜΟΝΑ
ΕΠΙΘΕΤΟ_ ΚΗΔΕΜΟΝΑ, ΟΝ_ ΚΗΔΕΜΟΝΑ à ΕΠΑΓΓΕΛΜΑ_ ΚΗΔΕΜΟΝΑ
ΕΠΙΘΕΤΟ_ ΚΗΔΕΜΟΝΑ, ΟΝ_ ΚΗΔΕΜΟΝΑ à ΤΗΛ_ ΚΗΔΕΜΟΝΑ
ΑΜ à ΕΠΑΓΓΕΛΜΑ_ ΚΗΔΕΜΟΝΑ
ΑΜ à ΤΗΛ_ ΚΗΔΕΜΟΝΑ
Για να εξαληφθεί η μεταβατική συνατρησιακή εξάρτηση των παραπάνω πεδίων διαιρούμε τον πίνακα σε δύο επι μέρους πίνακες.
ΣΠΟΥΔΑΣΤΕΣ (ΑΜ, ΕΠΙΘΕΤΟ, ΟΝΟΜΑ, ΤΗΛ, ΕΠΙΘΕΤΟ_ΚΗΔΕΜΟΝΑ ΟΝ_ ΚΗΔΕΜΟΝΑ, ΟΔΟΣ, ΑΡ, ΤΚ, ΠΟΛΗ)
ΚΗΔΕΜΟΝΕΣ (ΕΠΙΘΕΤΟ_ΚΗΔΕΜΟΝΑ, ΟΝ_ΚΗΔΕΜΟΝΑ, ΕΠΑΓΓΕΛΜΑ_ ΚΗΔΕΜΟΝΑ, ΤΗΛ_ ΚΗΔΕΜΟΝΑ , ΑΜ, ……)
Το πρωτεύον κλειδί του αρχικού πίνακα γίνεται ξένο κλειδί στον νέο πίνακα που προκύπτει από τον διαμελισμό του αρχικού πίνακα.
4.2.4
Boyce-Codd κανονική μορφή (BCNF)
Η Boyce-Codd Κανονική Μορφή είναι μια πιο περιοριστική μορφή της 3ΚΜ, με την έννοια ότι κάθε σχέση στην BCNF είναι επίσης στην 3ΚΜ, αλλά δεν ισχύει πάντα το αντίστροφο.
Η 3ΚΜ δεν αντιμετωπίζει τις παρακάτω περιπτώσεις:
1. Μία σχέση να έχει δύο ή περισσότερα υποψήφια κλειδιά
2. Τα δύο υποψήφια κλειδιά να είναι σύνθετα
3. Να επικαλύπτονται (να έχουν τουλάχιστον ένα γνώρισμα κοινό)
Μία σχέση βρίσκεται σε κανονική μορφή Boyce-Codd εάν κάθε προσδιοριστικό της σχέσης είναι ένα υποψήφιο κλειδί. Δηλαδή τα μόνα βέλη εξαρτήσεων που εμφανίζονται στο διάγραμμα εξαρτήσεων είναι βέλη που ξεκινούν από υποψήφια κλειδιά.
Θυμηθείτε ότι δεν είναι κλειδιά όλα τα προσδιοριστικά. Αυτά τα προσδιοριστικά που μπορούν να είναι κλειδιά τα καλούμε υποψήφια κλειδιά. Τελικά επιλέγουμε ένα υποψήφιο κλειδί για το πρωτεύον κλειδί μιας σχέσης. Στην πραγματικότητα, οι περισσότερες σχέσεις οι οποίες είναι στην 3NF είναι επίσης στην BCNF. Οποιαδήποτε σχέση που έχει μόνο δύο γνωρίσματα είναι σε BCNF.
Τα βήματα που ακολουθούνται ώστε να επιτευχθεί κανονικοποίηση μία σχέση ως προς ΚΜ BC είναι τα ακόλουθα:
1 Δημιουργία μίας λίστας με όλα τα γνωρίσματα
2 Έλεγχος εάν κάθε προσδιοριστικό γνώρισμα μπορεί να είναι υποψήφιο κλειδί
3 Για τα προσδιοριστικά γνωρίσματα που δεν είναι κλειδιά δημιουργείται μία σχέση για την κάθε συναρτησιακή εξάρτηση.
4 Γίνεται συσχέτιση των γνωρισμάτων που δεν είναι κλειδιά με την αρχική σχέση
Στο παρακάτω παράδειγμα η σχέση βρίσκεται σε Τρίτη κανονική μορφή αλλά όχι σε κανονική μορφή Boyce-Codd. Θεωρείστε ότι ισχύουν οι εξής περιορισμούς.
1 Οι Χρηματιστηριακές Συναλλαγές γίνονται σε πολλούς Τύπους Μετοχών
2 Οι Συναλλαγές διαχειρίζονται από έναν ή περισσότερους Χρηματιστές
3 Οι Τύποι Μετοχών μπορούν έχουν έναν ή πολλούς Χρηματιστές
4 Οι Χρηματιστές μπορούν να συναλλάσσονται σε έναν Τύπο Μετοχών
ΠΙΝΑΚΑΣ_Α
:

Οι συναρτησιακές εξαρτήσεις που προκύπτουν σύμφωνα με τα παραπάνω είναι:
ΚωδΣυναλλαγής, ΤύποςΜετοχής à
Χρηματιστής
ΚωδΣυναλλαγής,
Χρηματιστής à ΤύποςΜετοχής
Χρηματιστής à
ΤύποςΜετοχής
Τι θα συνέβαινε εάν διαγραφόταν η εγγραφή με ΚωδΣυναλλαγής 2-234.
Κανονικοποιήστε τον παραπάνω πίνακα ως προς ΚΜ-BC.
Λύση
Εάν διαγραφόταν η εγγραφή με ΚωδΣυναλλαγής 2-234 θα χανόταν και το γεγονός ότι ο Δήμου διαχειρίζεται τις Προνομιακές Μετοχές.
Ο συνδυασμός ΚωδΣυναλλαγής, και ΤύποςΜετοχής συνθέτουν ένα υποψήφιο κλειδί γιατί χρησιμοποιώντας τον συνδυασμό αυτό μπορούμε να αναγνωρίσουμε με μοναδικό τρόπο μια πλειάδα μέσα στη σχέση.
Όμοια ο συνδυασμός ΚωδΣυναλλαγής, και Χρηματιστής συνθέτουν ένα υποψήφιο κλειδί για τι χρησιμοποιώντας τον συνδυασμό αυτό μπορούμε να αναγνωρίσουμε με μοναδικό τρόπο μια πλειάδα μέσα στη σχέση
Το πεδίο χρηματιστής μόνο του δεν είναι υποψήφιο κλειδί διότι με αυτό δεν μπορούμε να αναγνωρίσουμε με μοναδικό τρόπο μια πλειάδα μέσα στη σχέση
Εξετάζουμε εάν η σχέση ΠΙΝΑΚΑΣ_Α(ΚωδΣυναλλαγής, Τύπος Μετοχής, Χρηματιστής) βρίσκετε σε 1ΚΜ, 2ΚΜ ή 3 ΚΜ.
Εάν ορίσουμε ώς πρωτεύον κλειδί το ζεύγος γνωρισμάτων ΚωδΣυναλλαγής, Τύπος Μετοχής τότε σίγουρα είναι σε 1ΚΜ. Είναι και σε 2ΚΜ επειδή τα υπόλοιπα γνωρίσματα εξαρτώνται από το σύνολο του προτεύοντος κλειδίού και όχι μόνο από τμήμα του. Είναι και σε 3ΚΜ επειδή δεν υπάρχουν μεταβατικές εξαρτήσεις.
Στο προηγούμενο παράδειγμα ποια είναι η λύση:
ΠινακαςΑ (ΚωδΣυναλλαγής, Τύπος Μετοχής, Χρηματιστής)
Τα προσδιοριστικά γνωρίσματα είναι:
ΚωδΣυναλλαγής, Τύπος Μετοχής
ΚωδΣυναλλαγής, Χρηματιστής
Χρηματιστής
Ποια προσδιοριστικά γνωρίσματα μπορούν να λειτουργήσουν
σαν υποψήφια κλειδιά;
ΚωδΣυναλλαγής, Τύπος Μετοχής ΝΑΙ
ΚωδΣυναλλαγής, Χρηματιστής ΝΑΙ
Χρηματιστής ΟΧΙ
Δημιουργήστε μία νέα σχέση για κάθε συναρτησιακή
εξάρτηση:
ΠΙΝΑΚΑΣ_Α(Χρηματιστής, Τύπος Μετοχής)
ΠΙΝΑΚΑΣ_Β(ΚωδΣυναλλαγής, Χρηματιστής)
Σε αυτό το τελευταίο βήμα κρατήσαμε το προσδιοριστικό γνώρισμα " Χρηματιστής " στην αρχική σχέση ΠινακαςΑ.
4.2.5
Τέταρτη κανονική
μορφή (4NF)
Μία σχέση είναι σε 4ΚΜ εάν είναι σε BC-NF και δεν περιέχει εξαρτήσεις πολλαπλών τιμών (multivalued dependencies).
Με άλλα λόγια μια σχέση είναι σε 4ΚΜ εάν και μόνο εάν οι εξαρτήσεις πολλαπλών τιμών που ικανοποιεί είναι στην πραγματικότητα συναρτησιακές εξαρτήσεις που ξεκινούν από υποψήφια κλειδιά. Για να γίνει κατανοητό αυτό θα πρέπει πρώτα να δώσουμε τον ορισμό της εξάρτησης πολλαπλών τιμών.
Εξάρτηση Πολλαπλών Τιμών (Multivalued Dependency):
Έστω R μία σχέση, και Α, Β, C, τυχαία υποσύνολα του συνόλου των γνωρισμάτων της R. τότε το πεδίο B είναι πολλαπλά εξαρτημένο με το Α ή Βà>Α ή αλλιώς το Α καθορίζει πολλαπλά το Β, εάν το σύνολο τιμών του Β που αντιστοιχούν σε δεδομένο ζεύγος (Α,C) στη σχέση R, εξαρτάται μόνο από την τιμή Α και είναι ανεξάρτητο από την τιμή C
Μπορούμε να πούμε ότι υπάρχουν τρία κριτήρια που πρέπει να προσεχθούν
1 Θα πρέπει να υπάρχουν τουλάχιστον 3 πεδία σε μια σχέση. Πχ Α, Β, και Γ
2 Γνωρίζοντας το Α μπορεί κάποιος να καθορίσει πολλές τιμές για το Β και γνωρίζοντας το Α μπορεί κάποιος να καθορίσει πολλές τιμές για το Γ
3 Το Β και το Γ είναι ανεξάρτητα μεταξύ τους
Στον παρακάτω πίνακα υπάρχουν εξαρτήσεις πολλαπλών τιμών. Ποιες είναι αυτές οι εξαρτήσεις και τι λύση θα δίνατε;
|
ΕΡΓΑΖΟΜΕΝΟΣ |
ΕΡΓΟ |
ΕΞΑΡΤΩΜΕΝΟΣ |
|
ΠΑΠΑΣ |
Α |
ΓΙΑΝΝΗΣ |
|
ΠΑΠΑΣ |
Β |
ΣΟΦΙΑ |
|
ΠΑΠΑΣ |
Α |
ΣΟΦΙΑ |
|
ΠΑΠΑΣ |
Β |
ΓΙΑΝΝΗΣ |
|
ΔΗΜΟΥ |
Β |
ΚΩΣΤΑΣ |
Λύση
Οι περιορισμοί που διαπιστώνονται στον παραπάνω πίνακα είναι:
Ο εργαζόμενος συμμετέχει σε πολλά έργα.
Ο εργαζόμενος επιβλέπει περισσότερους του ενός εργαζομένους.
Άρα οι συναρτησιακές εξαρτήσεις που προκύπτουν είναι:
ΕΡΓΑΖΟΜΕΝΟΣ à ΕΡΓΟ
ΕΡΓΑΖΟΜΕΝΟΣ à ΕΞΑΡΤΩΜΕΝΟΣ
Δηλαδή παρατηρούμε ότι :
1. Υπάρχουν τουλάχιστον 3 πεδία στην σχέση. ΕΡΓΑΖΟΜΕΝΟΣ, ΕΡΓΟ, ΕΞΑΡΤΩΜΕΝΟΣ
2. Ο ΕΡΓΑΖΟΜΕΝΟΣ μπορεί να καθορίσει πολλές τιμές για το ΕΡΓΟ επίσης ΕΡΓΑΖΟΜΕΝΟΣ μπορεί να καθορίσει πολλές τιμές για το πεδίου ΕΞΑΡΤΩΜΕΝΟΣ.
3. Ο ΕΞΑΡΤΩΜΕΝΟΣ και το ΕΡΓΟ είναι ανεξάρτητα μεταξύ τους.
Η λύση που προβλέπεται είναι δύο πίνακες που συσχετίζονται μεταξύ τους
|
ΕΡΓΑΖΟΜΕΝΟΣ |
ΕΡΓΟ |
|
|
|
ΕΡΓΑΖΟΜΕΝΟΣ |
ΕΞΑΡΤΩΜΕΝΟΣ |
|
ΠΑΠΑΣ |
Α |
|
|
|
ΠΑΠΑΣ |
ΓΙΑΝΝΗΣ |
|
ΠΑΠΑΣ |
Β |
|
|
|
ΠΑΠΑΣ |
ΣΟΦΙΑ |
|
ΔΗΜΟΥ |
Δ |
|
|
|
ΔΗΜΟΥ |
ΚΩΣΤΑΣ |
|
ΔΗΜΟΥ |
Α |
|
|
|
ΔΗΜΟΥ |
ΝΙΚΗ |
|
ΔΗΜΟΥ |
Β |
|
|
|
ΔΗΜΟΥ |
ΣΤΕΛΛΑ |
4.2.6
Πέμπτη κανονική
μορφή (5NF)
Μία σχέση είναι σε πέμπτη κανονική μορφή (5ΚΜ) εάν και μόνο εάν οι μόνες εξαρτήσεις σύζευξης που ικανοποιεί είναι στην πραγματικότητα συναρτησιακές εξαρτήσεις που ξεκινούν από υποψήφια κλειδιά
Εξάρτηση Σύζευξης: Έστω R μια σχέση, και Α,Β,..Ζ, τυχαία υποσύνολα του συνόλου των γνωρισμάτων της R. τότε η R ικανοποιεί εξάρτηση σύζευξης *(Α,Β,…Ζ) εάν και μόνο εάν η R είναι ίση με τη σύζευξη των προβολών της πάνω στα Α ,Β…Ζ
Επίσης η πέμπτη κανονική μορφή απομακρύνει εξαρτήσεις σύζευξης.
Στον παρακάτω πίνακα υπάρχουν εξαρτήσεις σύζευξης που ξεκινούν από το υποψήφια κλειδί Α . Ποιες είναι αυτές οι εξαρτήσεις και τι λύση θα δίνατε;
ΠΙΝΑΚΑΣ_A (Α,Β,Γ,Δ,Ε,Ζ,Η)
Λύση
Οι προβολές πάνω στα πεδία του πίνακα είναι. ΑΒ, ΑΓ, ΑΔ ….
Οι πίνακες που προκείπτουν είναι:
R1(A,B), R2(A,Γ), R31(A,Δ), R4(A,Ε), R5(A,Ζ), R6(A,Η)
Η σύζευξη των πινάκων R1, R2,R3,R4,R5,R6 δίνει το ίδιο αποτέλεσμα με τον ΠΙΝΑΚΑ_Α. Δηλ. με την εντολη
SELECT R1.A, B,Γ,Δ,Ε,Ζ,Η
FROM R1,R2,R3,R4,R5,R6
WHERE R1.A=R2.A AND R1.A=R3.A AND
R1.A=R4.A AND R1.A=R5.A AND
R1.A=R6.A
4.2.7
Κανονική μορφή
Πεδίου ορισμού/ Κλειδιού (ΚΜ ΠΟ/Κ )
Κανονική μορφή Πεδίου ορισμού : Μια δέσμευση που λέει ότι οι τιμές ενός δεδομένου γνωρίσματος παίρνονται από ένα καθορισμένο πεδίο ορισμού
Κανονική μορφή Κλειδιού: Μια δέσμευση που ορίζει ότι κάποιο γνώρισμα ή συνδυασμός γνωρισμάτων είναι υποψήφιο κλειδί
Δέσμευση: Είναι ένας κανόνας που αναγκάζει τις στατικές τιμές ενός γνωρίσματος έτσι ώστε ο καθορισμός της τιμής να γίνεται μόνο όταν αυτός ο κανόνας είναι αληθής.

Εικόνα4.1 . Οι κανονικές μορφές
Κανονική Μορφή
Περιορισμού- Ένωσης
Δίνει απαντήσεις σε ερωτήσεις όπου η θεωρία της κανονικοποίησης δεν δίνει απαντήσεις. Το αποτέλεσμα είναι κακοί σχεδιασμοί σχέσεων.
4.3
Απο-Κανονικοποίηση (De-Normalization)
Υπάρχουν περιπτώσεις όπου μπορεί γίνει να από-κανονικοποίηση των σχέσεων ώστε να επιτευχθεί καλύτερη απόδοση της βάσης
Θεωρήστε την παρακάτω σχέση:ΠΕΛΑΤΕΣ (ΚΜ, Επίθετο, Όνομα, Διεύθυνση, Πόλη, , ΤΚ)
Η σχέση αυτή περιέχει συναρτησιακές εξαρτήσεις ΤΚ à Πόλη
Μπορούμε να κάνουμε κανονικοποίηση ΚΜ ΠΟ/Κ χωρίζοντας την σχέση ΠΕΛΑΤΕΣ στα δύο
ΠΕΛΑΤΕΣ (ΚΜ, Επίθετο, Όνομα, Διεύθυνση, ΤΚ) και
ΤαχΚΩΔΙΚΟΙ (ΤΚ, Πόλη)
Αυτό θεωρείτε λάθος γιατί όταν θελήσουμε την διεύθυνση ενός πελάτη θα ψάχνουμε σε δύο σχέσεις (πίνακες).
Το ίδιο ισχύει και στις περιπτώσεις των πεδίων ΤΗΛΕΦΏΝΟ. Είναι προτιμότερο να έχουμε στον ίδιο πίνακα 2 και 3 πεδία τηλεφώνου (ΤΗΛ_ΚΙΝ, ΤΗΛ_ΕΡΓΑΣΙΑΣ, ΤΗΛ_ΟΙΚΙΑΣ, ΤΗΛ_ΦΑΞ), γεγονός που έρχεται σε αντίθεση με 1ΚΜ, παρά να ψάχνουμε σε δύο πίνακες για να βρούμε το τηλέφωνο ενός ατόμου.
Σε τέτοιες περιπτώσεις η από-κανονικοποίηση αποφέρει μεγαλύτερη απόδοση τη βάσης.
Κεφάλαιο 5. SQL
Για να μπορέσουμε να
δημιουργήσουμε και να διαχειριστούμε μια βάση δεδομένων, μπορούμε να
χρησιμοποιήσουμε ειδικές γλώσσες προγραμματισμού, τις λεγόμενες γλώσσες ερωταπαντήσεων (query languages).
Είναι γλώσσες μη διαδικαστικές, τέταρτης γενιάς (4th generation languages).
Εμείς απλά διατυπώνουμε με απλές και κατανοητές εντολές το τι πληροφορίες
ζητάμε και το ΣΔΒΔ (Σύστημα Διαχείρισης Βάσεων Δεδομένων) αναλαμβάνει να μας
απαντήσει. Η SQL (Structured Query
Language, δηλ. Δομημένη Γλώσσα Ερωτημάτων)
είναι σήμερα η πιο δημοφιλής και πιο διαδεδομένη γλώσσα ανάπτυξης και
διαχείρισης σχεσιακών βάσεων δεδομένων.
·
Η SQL μάς δίνει τη δυνατότητα να
έχουμε πρόσβαση σε μια βάση δεδομένων (database).
·
Η SQL αποτελεί μια στάνταρτ γλώσσα
του ANSI (ANSI standard language).
·
Η SQL μπορεί να εκτελέσει
ερωτήματα (queries) και να αναζητήσει πληροφορίες σε μια βάση δεδομένων.
·
Η SQL μπορεί να ανακτήσει δεδομένα
από μια βάση δεδομένων.
·
Η SQL μπορεί να εισαγάγει νέες
εγγραφές σε μια βάση δεδομένων.
·
Η SQL μπορεί να διαγράψει εγγραφές
από μια βάση δεδομένων.
·
Η SQL μπορεί να ενημερώσει
εγγραφές σε μια βάση δεδομένων.
·
Η SQL είναι πολύ εύκολη στην
εκμάθηση.
Η SQL
αποτελείται από εντολές με τα ορίσματά τους, τις οποίες μπορούμε να
χρησιμοποιήσουμε με συγκεκριμένους κανόνες σύνταξης για να πάρουμε τα
αποτελέσματα που θέλουμε. Με την SQL
μπορούμε να δημιουργήσουμε μια βάση δεδομένων και τους πίνακές της με τα
αντίστοιχα πεδία, να καταχωρήσουμε δεδομένα στους πίνακες, να τροποποιήσουμε
και να διαγράψουμε τα δεδομένα αυτά, να αλλάξουμε τη δομή των πινάκων με
προσθήκη και διαγραφή πεδίων και να εμφανίσουμε πληροφορίες (συνδυασμούς από
δεδομένα).
Η SQL
έχει διάφορα τμήματα, τα πιο βασικά είναι τα παρακάτω :
·
Τη Γλώσσα Ορισμού Δεδομένων (DDL, Data Definition Language),
η οποία περιέχει τις απαραίτητες εντολές για τον ορισμό και την τροποποίηση του
σχεσιακού σχήματος καθώς και για τη δημιουργία, την τροποποίηση και τη διαγραφή
σχέσεων. Περιέχει ακόμη τις εντολές δημιουργίας και επεξεργασίας όψεων και
ορισμού περιορισμών ακεραιότητας.
·
Τη Γλώσσα Χειρισμού Δεδομένων (DML, Data Manipulation Language),
η οποία περιέχει τις απαραίτητες εντολές για την εμφάνιση (αναζήτηση) δεδομένων
καθώς και για την καταχώρηση, τροποποίηση και διαγραφή των εγγραφών (πλειάδων)
μιας σχέσης.
·
Τέλος, περιέχει εντολές για τον
ορισμό και την επεξεργασία συναλλαγών
(transactions)
και εντολές για την ασφάλεια (authentication).
Τα διάφορα τμήματα της SQL
παρουσιάζονται συνοπτικά στον παρακάτω πίνακα:
|
Γλώσσα Ορισμού Δεδομένων
(DDL) |
CREATE |
DROP | ALTER
TABLE (base table) CREATE |
DROP | ALTER
VIEW (virtual table) CREATE |
DROP | ALTER
INDEX (index table) |
|
Γλώσσα Χειρισμού
Δεδομένων (DML) |
SELECT αναζήτηση INSERT εισαγωγή εγγραφής DELETE διαγραφή εγγραφής UPDATE τροποποίηση εγγραφής |
|
Ενσωματωμένη Γλώσσα Χειρισμού Δεδομένων (Static SQL) (Dynamic SQL) |
EXEC SQL DECLARE Sinfo CURSOR FOR SELECT S_name, S_sity FROM
SUPPLIERS ORDER BY S_name; do { …… EXEC SQL FETCH sinfo INTO : sname, : ssity; ……………….. EXEC SQL CLOSE sinfo; CString CDataSourceSet::GetDefaultConnect() {return ODBC;DSN=DataSource;"; } CString CDataSourceSet::GetDefaultSQL() {return "SELECT * FROM SUPPLIERS ORDER BY S_Name"; } |
|
Ορισμό Όψεων |
CREATE VIEW ATHENS_SUPPLIERS |
|
Εξουσιοδότηση (authentication) |
CREATE |
DROP | ALTER
User CREATE USER John
IDENTIFIED BY Johns-password; GRANT CONNECT TO John; GRANT SELECT, UPDATE ON
SUPPLIERS TO John; REVOKE SELECT ON
SUPPLIERS FROM John; |
|
Ακεραιότητα |
CREATE DOMAIN S_No AS
INTEGER CONSTRAINT Έλεγχος-Αριθμού-Προμηθευτή CHECK (S_No >0); CREATE ASSERTION <Όνομα-δήλωσης> CHECK <Κατηγόρημα>; DEFINE TRIGGER <όνομα> ON UPDATE OF SUPPLIERS (…) |
|
Έλεγχο Συναλλαγών |
SQL> SET TRANSACTION; INSERT INTO CUSTOMERS VALUES
('SMITH', 'JOHN'); SQL> COMMIT; |
5.1 Χειρισμός Δεδομένων της SQL (Data Manipulation Language)
Όπως δηλώνει και το
όνομά της, η SQL είναι μια σύνταξη για την εκτέλεση ερωτημάτων (queries). Αλλά
η γλώσσα της SQL περιλαμβάνει επίσης μια σύνταξη για την ενημέρωση εγγραφών,
την εισαγωγή νέων εγγραφών και τη διαγραφή υπαρχόντων εγγραφών.
Η Γλώσσα Χειρισμού Δεδομένων (Data Manipulation
Language, DML) που
αποτελεί κομμάτι της SQL χρησιμοποιεί τις παρακάτω εντολές :
· SELECT
-
προβάλει τα δεδομένα αναζήτησης από μια βάση δεδομένων.
· INSERT
- εισάγει
νέα δεδομένα σε μια βάση δεδομένων.
· UPDATE
-
ενημερώνει δεδομένα σε μια βάση δεδομένων.
· DELETE
-
διαγράφει δεδομένα από μια βάση δεδομένων.
Στη συνέχεια θα δοθεί μη σύνταξη
των παραπάνω εντολών. Στις εντολές αυτές
θα αναφερθούμε συνοπτικά και θα δώσουμε μεγαλύτερη έμφαση σε ερωτήματα
περίπλοκα και εμφωλιασμένα.
Η εντολή SELECT
προβάλει δεδομένα από τις στήλες (columns) ενός πίνακα της βάσης δεδομένων. Το
αποτέλεσμα προβάλλεται σε μορφή πίνακα και αποκαλείται result set. Η σύνταξη
της εντολής είναι η εξής:

 select Α1, Α2, .., Αn
select Α1, Α2, .., Αn
from R1, R2, … Rm
 where P1
where P1
Συνθήκη 2 σε
συνάρτηση
group by Α1
![]() having P2
having P2
order
by Α1 asc
/ desc
Αi:
αναπαριστά γνωρίσματα, Ri:
αναπαριστά σχέσεις(πίνακες), P:
είναι συνθήκη
Αυτό το ερώτημα είναι ισοδύναμο με
την έκφραση της σχεσιακής άλγεβρας
π A1, A2, .., An (σ P (R1 x R2 x … Rm))
select
αντιστοιχεί στην πράξη της
προβολής της σχεσιακής άλγεβρας. Τα γνωρίσματα που θέλουμε να υπάρχουν στο
αποτέλεσμα της ερώτησης.
from
αντιστοιχεί στην πράξη του καρτεσιανού γινομένου της σχεσιακής άλγεβρας. Ποιες σχέσεις(πίνακες) θα χρησιμοποιηθούν για τον υπολογισμό του
αποτελέσματος.
where
αντιστοιχεί στη συνθήκη της
πράξης της επιλογής στη σχεσιακή άλγεβρα. Το κριτήριο P
έχει γνωρίσματα των σχέσεων που εμφανίζονται στο from.
group
by ο όρος χρησιμοποιείται στις περιπτώσεις
ομαδοποίησης αποτελεσμάτων σύμφωνα με ένα γνώρισμα. Συνήθως χρησιμοποιείται
όταν υπάρχουν συναθροιστικές συναρτήσεις (sum, avg, count, min,max) στο select.
having
η πρόταση αυτή περιορίζει τις
γραμμές που επιστρέφονται από μία πρόταση group by με τον ίδιο τρόπο που
η πρόταση where
περιορίζει τις γραμμές που επιστέφονται από την πρόταση select.
Τόσο η where
όσο και η having
μπορούν να συμπεριληφθούν στην ίδια πρόταση select.
Η where
εφαρμόζεται πριν την ομαδοποίηση και η having εφαρμόζεται αφού
σχηματιστούν οι ομάδες (group by) και υπολογιστούν οι συναθροιστικές
συναρτήσεις.
order by
χρησιμοποιείται ώστε οι εγγραφές/ γραμμές/ πλειάδες/ συστοιχίες να είναι
ταξινομημένες με βάση το αντίστοιχο γνώρισμα κατά αύξουσα σειρά asc
ή κατά φθίνουσα σειρά desc.
ΠΡΟΣΟΧΗ: Δε γίνεται απαλοιφή των διπλών εμφανίσεων
(διπλότυπα).
Η SQL επιτρέπει και πολλαπλές εμφανίσεις
της ίδιας συστοιχίας σε μια σχέση. Μια σχέση στην SQL είναι ένα πολυσύνολο
(multiset)
Η σημασιολογία των διπλότυπων στην
SQL:
select Α1, Α2, .., Αn
from R1, R2, … Rm
where P
είναι ισότιμο με την εκδοχή
πολλαπλών συνόλων της έκφρασης:
π A1, A2, .., An (σ P (R1 x R2 x … Rm))
Για την Απαλοιφή διπλών εμφανίσεων
(διπλότυπα) χρησιμοποιούμε το distinct . Π.χ.
select
distinct Α1, Α2, .., Αn
from R1, R2,
… Rm
5.1.2 Insert
Για να εισάγουμε δεδομένα σε μια σχέση
μπορούμε να το υλοποιήσουμε με την εντολή insert into,
εισάγοντας (α) μεμονωμένες τιμές είτε (β) πλήθος τιμών από έναν άλλο πίνακα
(α)
Insert into R(A1, …, An) values (v1, …, vn)
(β)
Insert
into R(A1, …, An) select-from-where
5.1.3 Update
Η γενική σύνταξη είναι
Update
όνομα-πίνακα Set
όνομα-στήλης = νέα-τιμή
Where P
Η ενημέρωση γίνετε σε όλες τις
γραμμές του πίνακα που ικανοποιούν την συνθήκη Ρ
5.1.4 Delete
Με την
εντολή αυτή γίνετε η διαγραφή των εγγραφών από έναν πίνακα
Delete
from R where P
Σβήνει όλες τις γραμμές της R για
τις οποίες ισχύει η συνθήκη P.
Όταν λείπει το where σβήνονται όλες οι εγγραφές ενός
πίνακα
.
5.2 Ορισμός Δεδομένων της SQL (Data Definition Language)
Με τις εντολές αυτές της SQL
ορίζουμε το σχήμα της βάσης δεδομένων, μπορούμε να το τροποποιήσουμε αλλά και
να το διαγράψουμε.
Οι βασικότερες
εντολές που χρησιμοποιεί η DDL είναι οι εξής :
· CREATE TABLE
-
δημιουργεί έναν πίνακα.
· ALTER TABLE
- Τροποποιεί
την δομή ενός πίνακα.
· DROP TABLE
-
διαγράφει ολόκληρο πίνακα
5.2.1 Create Table
Η
σύνταξη της εντολής για την δημιουργία ενός νέου πίνακα είναι :
Create table R( A1 D1, A2 D2, …..., An Dn ),
<περιορισμός-ακεραιότητας1>,
…,
<περιορισμός-ακεραιότηταςk>
όπου R είναι το όνομα του πίνακα, Ai
τα ονόματα των γνωρισμάτων, και Di
οι τύποι των αντίστοιχων πεδίων ορισμού.
Τύποι Πεδίων Ορισμού
Για τον ορισμό του πεδίου ορισμού,
οι διαθέσιμοι built-in τύποι περιλαμβάνουν:
char(n).
Αλφαριθμητικό σταθερού μήκους n που
ορίζεται από τον χρήστη.
varchar(n).
Αλφαριθμητικό μεταβλητού μήκους, με μέγιστο μήκος n
οριζόμενο από τον χρήστη.
int.
Ακέραιος (υποσύνολο που εξαρτάται από τη μηχανή)
smallint.
Μικρός ακέραιος (υποσύνολο που εξαρτάται από τη μηχανή)
numeric(p,d). Αριθμός
σταθερής υποδιαστολής, με ακρίβεια p
ψηφίων όπου τα d
είναι στα δεξιά της υποδιαστολής.
real,
double precision.
Πραγματικοί αριθμοί, διπλής ακρίβειας, όπου η ακρίβεια εξαρτάται από τη μηχανή.
float(n).
Πραγματικοί αριθμοί κινητής υποδιαστολής, με ακρίβεια τουλάχιστον n
ψηφίων οριζόμενη από τον χρήστη.
date.
Ημερομηνία της μορφής Π.χ. date
‘2002-10-22’
time.
Ώρα της ημέρας σε ώρες, λεπτά, δευτερόλεπτα. Π.χ. time ’09:
timestamp. Η
ημέρα συν την ώρα. Π.χ. timestamp ‘2002-10-22 09:05:32.75’
interval. Χρονικό
διάστημα. Π.χ. διάστημα ‘1’ ημέρας
Οι τιμές null
επιτρέπονται στα πεδία ορισμού. Δηλώνοντας ένα πεδίο ως not null
απαγορεύει οι τιμές του πεδίου να είναι κενές και προϋποθέτει την υποχρεωτική
καταχώριση τιμής σε αυτό το πεδίο..
Περιορισμοί Ακεραιότητας
Επιτρεπτοί περιορισμοί
ακεραιότητας είναι της μορφής:
·
primary key Aj1, Aj2,
..., Ajn, (δεν επιτρέπονται διπλόεγγραφές και NULL τιμές), ορίζει το
πρωτεύον κλειδί του πίνακα.
·
unique Aj1, Aj2,
..., Ajn, (δεν επιτρέπονται διπλοεγγραφές; NULL τιμές επιτρέπονται)
·
check P έλεγχος μιας
συνθήκης σε ένα πεδίο
·
foreign key (Ai) references Ai ορισμός ενός
πεδίου ως ξένο κλειδί.
5.2.2
Alter Table
Η σύνταξη της εντολής αυτής μπορεί
να γίνει με ένα από του παρακάτω τρεις τρόπους ανάλογα με τις αντίστοιχες απαιτήσεις
alter
table R ADD
όνομα_στήλης τύπος
δεδομένων
alter
table R DROP COLUMN όνομα_στήλης
alter
table R MODIFY
(όνομα_στήλης νέος τύπος
δεδομένων)
ADD
- προσθέτει καινούργια στήλη
DROP
- διαγράφει μια στήλη
MODIFY
- τροποποιεί μια στήλη
Η εντολή
modify μπορεί
να τροποποιήσει μόνο τον τύπο δεδομένων, όχι το όνομα της στήλης. Μερικά
RDBMS
δεν επιτρέπουν τη διαγραφή (DROP) στήλης σε έναν πίνακα της βάσης
5.2.3
Drop Table
.Για να σβηστεί ένας πίνακας R η
σύνταξη της εντολής είναι η παρακάτω:
drop table R
Δεν πρέπει να την συγχέουμε με την
εντολή delete from R
η οποία διαγράφει μόνο τις εγγραφές από τον πίνακα. Η εντολή Drop Table
διαγράφει και εξαφανίζει οριστικά ολόκληρο τον πίνακα.
5.3 Ορισμός Όψεων της SQL (View Definition Language)
Με τις εντολές αυτές της SQL
ορίζουμε όψεις της βάσης δεδομένων, όπου μπορούμε να εκτελέσουμε ερωτήματα και
τα αποτελέσματα τους να τα χρησιμοποιήσουμε με τον ίδιο τρόπο που
χρησιμοποιούμε τους πίνακες μιας βάσης. Τις όψεις αυτές μπορούμε να τις
τροποποιήσουμε αλλά και να τις διαγράψουμε. Οι όψεις αποτελούν ένα σημαντικό
εργαλείο των βάσεων δεδομένων όσων αφορά την ασφάλεια των δεδομένων.
Χρησιμοποιώντας όψεις αντί για πίνακες μειώνεται οι πιθανότητα να αλλοιωθούν τα
δεδομένα ενός πίνακα μιας και ο τελικός χρήστης δεν θα έχει απευθείας πρόσβαση
στον πίνακα και σε όλα τα στοιχεία του, αλλά θα βλέπει και θα επεξεργάζεται τα
στοιχεία που θα προβάλλει η όψη.
Οι βασικότερες
εντολές που χρησιμοποιεί η VDL είναι οι εξής :
· CREATE VIEW
-
δημιουργεί μία όψη.
· ALTER VIEW
- Τροποποιεί
τη δομή μιας όψεις.
· DROP VIEW
-
διαγράφει ολόκληρη την όψη
5.3.1 Create View
Η
σύνταξη της εντολής για την δημιουργία μιας όψης είναι :
Create View V As
Select …..
From
……
Where ……
…..,
όπου V
είναι το όνομα της όψης, και ακολουθεί η σύνταξη ενός ερωτήματος που ξεκινά με
την εντολή select.
5.3.2
Alter View
Η σύνταξη της εντολής αυτής μπορεί
να γίνει με ένα από του παρακάτω τρεις τρόπους ανάλογα με τις αντίστοιχες
απαιτήσεις
Αlter View V As
Select
……
Όπου V
είναι το όνομα της όψης που πρόκειται να τροποποιηθεί.
5.3.3
Drop View
.Για να διαγραφεί μία όψη V,
η σύνταξη της εντολής είναι η παρακάτω:
Drop View V
5.4 Εμφωλευμένα
Υπο-ερωτήματα
Ένα
υποερώτημα είναι μια έκφραση select
– from –
where
που είναι εμφωλευμένη (ένθετη) μέσα σε μια άλλη έκφραση. Τότε το πρώτο
ονομάζεται εξωτερικό ερώτημα και το δεύτερο εσωτερικό υποερώτημα.
Υπολογίζεται
πρώτα το εσωτερικό υποερώτημα και κατόπιν το εξωτερικό εφαρμόζοντας σε αυτό το
αποτέλεσμα του εσωτερικού ερωτήματος. Εξαίρεση αποτελεί η περίπτωση των
συσχετιζόμενων υποερωτημάτων όπου το εσωτερικό υποερώτημα θα υπολογιστεί για
κάθε γραμμή (συστοιχία) του εξωτερικού ερωτήματος.
Η
γενική σύνταξη των εμφωλευμένων υποερωτημάτων είναι η
![]() select *
select *
from πινακας1
where πινακας1.πεδίο1 ΤΕΛΕΣΤΗΣ ΣΥΓΚΡΙΣΗΣ
![]() (select πεδίο2
(select πεδίο2
from πινακας2
where πεδίο3 = τιμή1)
Σαν
τελεστές σύγκρισης χρησιμοποιούνται οι <
<= > >= =
<>
Τα
εμφωλευμένα υποερωτήματα χρησιμοποιούνται όταν δεν γνωρίζουμε την τιμή
σύγκρισης στη συνθήκη που υπάρχει σε προτάσεις where ή having.
Στις
περιπτώσεις όπου το εσωτερικό υποερώτημα θα έχει ως αποτέλεσμα την επιστροφή
δύο ή περισσοτέρων τιμών χρησιμοποιούνται οι τελεστές in, not in, some, all, exists, unique.
Ο τελεστής in (not in)
ελέγχει αν μια πλειάδα ανήκει ( ή δεν ανήκει) σε ένα σύνολο από πλειάδες
που έχουν προκύψει από μια έκφραση
select-from-where.
Ο τελεστής some έχει τη σημασία του τουλάχιστον
ένα από ένα σύνολο
Επίσης ισχύει (= some) ισοδύναμο. του in
Ωστόσο (¹some) όχι ισοδύναμο του not in
Ο τελεστής any
έχει τη σημασία του το πολύ ένα από ένα σύνολο
Ο τελεστής all έχει τη σημασία από όλα τα
στοιχεία ενός συνόλου.
Επίσης ισχύει (¹ all) ισοδύναμο του not
in
Το (= all)
ελέγχει αν το υποερώτημα έχει μόνο μία τιμή, δεν είναι ισοδύναμο του in.
Ο τελεστής exists χρησιμοποιείται στον έλεγχο
για κενά σύνολα (κενές σχέσεις) και
επιστρέφει true αν η υποερώτηση δεν είναι κενή
Ο τελεστής not exists:
επιστρέφει true αν η υποερώτηση είναι κενή
Ο τελεστής unique (not unique) ελέγχει
αν ένα υποερώτημα περιέχει διπλότυπες πλειάδες στο αποτέλεσμά του (έλεγχος για
διπλότυπα).
Ο τελεστής unique: επιστρέφει true αν
η υποερώτηση δεν έχει διπλότυπες πλειάδες.
Ο τελεστής not unique:
επιστρέφει true αν η υποερώτηση έχει διπλότυπα.
Ο πιο συχνά χρησιμοποιούμενος τελεστής από τους
παραπάνω είναι ο in
(not in).
5.5 Πράξεις Συνόλων
Οι πράξεις δύο συνόλων Α
και Β είναι η ένωση η τομή και διαφορά τους όπως φαίνεται στην παρακάτω εικόνα:
ένωση
τομή διαφορά
Εικόνα 5.1 Πράξεις συνόλων.
Οι πράξεις συνόλων
εφαρμόζονται σε πίνακες που έχουν
τον ίδιο αριθμό στηλών και ίδιο τύπο
δεδομένων.
Γενική σύνταξη:
Πίνακας Α
<Πράξη>
Πίνακας Β
Οι τελεστές που μπορούν να
χρησιμοποιηθούν για τις πράξεις συνόλων είναι
union ένωση
intersect τομή
except διαφορά
Καθένας από τους παραπάνω
τελεστές αυτόματα διαγράφει τα διπλότυπα (απαλοιφή διπλών εμφανίσεων). Για την
τήρηση των διπλοτύπων χρησιμοποιείται η αντίστοιχη εκδοχή πολλαπλών συνόλων union all, intersect all , except all.
ο τελεστής union υποστηρίζεται από τα περισσότερα
σχεσιακά συστήματα διαχείρισης βάσεων δεδομένων.
5.6 Τύποι Σύζευξης
Ο κλασικός τρόπος εκτέλεσης ενός ερωτήματος από την
στιγμή που καλούνται πάνω από ένας πίνακες που συσχετίζονται μεταξύ τους σε
κάποια πεδία είναι να χρησιμοποιήσουμε μια συνθήκη στο where του ερωτήματος όπου θα ελέγχουμε
τις τιμές από τα κοινά πεδία των πινάκων που μετέχουν στην έκφραση from ναι είναι ίσες μεταξύ τους. Σε
περίπτωση που δεν κάνουμε τον παραπάνω έλεγχο, θα παρουσιάσουμε το καρτεσιανό
γινόμενο όλων των εγγραφών από όλους τους πίνακες και το αποτέλεσμα θα είναι
λάθος.
select R1.A1, A2, A3, A4
from R1,R2
where R1.A1=R2.A1
Αντί για τον παραπάνω τρόπο χρησιμοποιούμε καλύτερα
τους παρακάτω τύπους σύζευξης πινάκων.
|
Inner join: |
σημαίνει τις
εγγραφές από τους δύο πίνακες όπου οι τιμές του κοινού πεδίου είναι ίδιες |
|
left outer join:
|
σημαίνει όλες
τις εγγραφές του αριστερού πίνακα και τις εγγραφές του δεξιού όπου οι τιμές
του κοινού πεδίου είναι ίδιες |
|
right outer join:
|
σημαίνει όλες τις
εγγραφές του δεξιού πίνακα και τις εγγραφές του αριστερού όπου οι τιμές του
κοινού πεδίου είναι ίδιες |
|
full outer join:
|
Η ένωση (union) των δύο παραπάνω |
(Η λέξη OUTER
προαιρετική):
Σε
περίπτωση δύο πινάκων που συσχετίζονται μεταξύ τους με το πεδίο Α1
select R1.A1, A2, A3, A4
from R1 ΣΥΖΕΥΞΗ R2 on
R1.A1=R2.A2
Σε
περίπτωση τριών πινάκων που συσχετίζονται μεταξύ τους ο R1 και R2 με το πεδίο Α1 και ο R2, R3 με το πεδίο Α2
select R1.A1, R2.A2, A3, A4
from R1 ΣΥΖΕΥΞΗ (R2 ΣΥΖΕΥΞΗ R3 on
R2.A2=R3.A2)
on R1.A1=R2.A1
Ο τρόπος σύζευξης που χρησιμοποιείται συχνότερα
είναι η εσωτερική (φυσική) σύζευξη inner
join.
5.7 Παραγόμενες Σχέσεις
Η SQL-92 δίνει τη δυνατότητα μια υποερώτηση να
χρησιμοποιηθεί στο from αντί
για το όνομα ενός πίνακα.
Τότε πρέπει να τις δοθεί ένα όνομα στα αποτελέσματα
της υποερώτησης και τα γνωρίσματα της να μετονομαστούν
Αυτό γίνεται χρησιμοποιώντας το as και δίνεται έτσι
ένα προσωρινό όνομα στην προσωρινή σχέση που προκύπτει από την υποερώτηση.
Στην παρακάτω σύνταξη μιας παραγόμενης σχέσης
παρατηρούμε ότι το R2
είναι το όνομα του πίνακα που προκύπτει από την εκτέλεση ενός υποερωτήματος που
υπολογίζει την μέση τιμή του πεδίου Α2
από τον πίνακα R1,
και την ονομάζει Α3, ομαδοποιώντας τα αποτελέσματα κατά το πεδίο Α1. Στο τέλος
συγκρίνουμε το πεδίο Α3 της παραγόμενης σχέσης με μία τιμή Χ.
select Α1, Α3
from (select
Α1, avg(Α2) as
A3
from R1
group by A1 )
as R2(A1, A3)
where A3 > X
Να σημειώσουμε ότι Οι παραγόμενες σχέσεις δεν
υποστηρίζονται από όλα τα RDBMS.
Το ίδιο αποτέλεσμα θα δινόταν εάν δημιουργούσαμε
πρώτα μια όψη με όνομα R2
και στη συνέχεια την χρησιμοποιούσαμε σε ένα επόμενο ερώτημα μιας άλλης όψης.
Create
View R2 As
select Α1, avg(Α2) as
A3
from R1
group by A1
Create
View V1 As
select Α1, Α3
from R2
where A3
> X
Στη συνέχεια θα παραθέσουμε παραδείγματα SQL για όλες τις παραπάνω
περιπτώσεις.
Δημιουργήστε με εντολές SQL τον πίνακα ΑΤΖΕΝΤΑ με τα παρακάτω
πεδία.
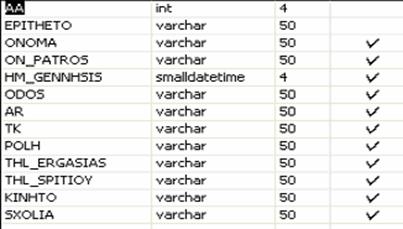
Λύση
CREATE TABLE ATZENTA (
AA INT NOT NULL,
EPITHETO
VARCHAR(50),
ONOMA VARCHAR(50),
ON_PATROS VARCHAR(50),
HM_GENNHSIS SMALLDATETIME,
ODOS VARCHAR(50),
AR VARCHAR(50),
TK VARCHAR(50),
…………………………
…………………………..
,
PRIMARY KEY (AA))
Εμφανίστε όλα τα στοιχεία του πίνακα ΑΤΖΕΝΤΑ που το
επίθετό αρχίζει από Κ.
ΑΤΖΕΝΤΑ(ΑΑ, ΕPΙΤΗΕΤΟ, ΟΝΟΜΑ, ΟΝ_PΑΤRΟΣ , ΗΜ_GΕΝΝΗSIS, ΟDΟΣ, AR, TK, POLH, THL)
Λύση
SELECT *
FROM ATZENTA
WHERE EPITHETO LIKE ‘K%’
Εμφανίστε Επίθετο, Όνομα και Τηλέφωνο των ατόμων
του πίνακα ΑΤΖΕΝΤΑ που γεννήθηκαν μετά το
1997 και είναι από την πόλη Σέρρες.
ΑΤΖΕΝΤΑ(ΑΑ, ΕPΙΤΗΕΤΟ, ΟΝΟΜΑ, ΟΝ_PΑΤRΟΣ , ΗΜ_GΕΝΝΗSIS, ΟDΟΣ, AR, TK, POLH, THL)
Λύση
SELECT ΕPΙΤΗΕΤΟ,
ΟΝΟΜΑ,THL
FROM
ATZENTA
WHERE ΗΜ_GΕΝΝΗSIS
>’1-1-
Ομαδοποιήστε τα άτομα του πίνακα ΑΤΖΕΝΤΑ ανά πόλη
και μετρήστε πόσοι είναι από κάθε πόλη.
ΑΤΖΕΝΤΑ(ΑΑ, ΕPΙΤΗΕΤΟ, ΟΝΟΜΑ, ΟΝ_PΑΤRΟΣ , ΗΜ_GΕΝΝΗSIS, ΟDΟΣ, AR, TK, POLH, THL)
Λύση
SELECT POLH,
COUNT(AA) AS PLHTHOS
FROM ΑΤΖΕΝΤΑ
GROUP BY POLH
Προβάλετε τις καταχωρήσεις του πίνακα ΑΤΖΕΝΤΑ που
κατάγονται από την ίδια πόλη που κατάγεται ο Γεωργίου (φωλιασμένο ερώτημα)
ΑΤΖΕΝΤΑ(ΑΑ, ΕPΙΤΗΕΤΟ, ΟΝΟΜΑ, ΟΝ_PΑΤRΟΣ , ΗΜ_GΕΝΝΗSIS, ΟDΟΣ, AR, TK, POLH, THL)
Λύση
SELECT *
FROM AZENTA
WHERE POLH = (SELCET POLH
FROM ATZENTA
WHERE EPITHETO=’Γεωργίου’)
Προβάλετε σε ένα ερώτημα τις καταχωρήσεις του πίνακα
ΑΤΖΕΝΤΑ που κατάγονται από Αθήνα και αυτές από Θεσσαλονίκη.
ΑΤΖΕΝΤΑ(ΑΑ, ΕPΙΤΗΕΤΟ, ΟΝΟΜΑ, ΟΝ_PΑΤRΟΣ , ΗΜ_GΕΝΝΗSIS, ΟDΟΣ, AR, TK, POLH, THL)
Λύση
SELECT *
FROM AZENTA
WHERE POLH ‘Αθήνα’ OR
POLH ‘Θεσσαλονίκη
Εισάγετε στον
πίνακα ΑΤΖΕΝΤΑ μια εγγραφή με τα παρακάτω στοιχεία
123, ΔΗΜΗΤΡΙΟΥ, ΙΩΑΝΝΗΣ, ΓΕΩΡΓΙΟΣ, 7-7-1974, ΕΡΜΟΥ,
12, 62122, ΣΕΡΡΕΣ.
ΑΤΖΕΝΤΑ(ΑΑ, ΕPΙΤΗΕΤΟ, ΟΝΟΜΑ, ΟΝ_PΑΤRΟΣ , ΗΜ_GΕΝΝΗSIS, ΟDΟΣ, AR, TK, POLH, THL)
Λύση
INSERT INTO ATZENTA
VALUES(123, ‘ΔΗΜΗΤΡΙΟΥ’, ‘ΙΩΑΝΝΗΣ’, ‘ΓΕΩΡΓΙΟΣ’, #7-7-1974#, ‘ΕΡΜΟΥ’, 12, ‘62122’, ‘ΣΕΡΡΕΣ’, ‘23210-
Διορθώστε στον
πίνακα ΑΤΖΕΝΤΑ το τηλέφωνο της εγγραφής με ΑΑ ίσο με 1234 και δώστε στο
τηλέφωνο την τιμή 2321-55532
ΑΤΖΕΝΤΑ(ΑΑ, ΕPΙΤΗΕΤΟ, ΟΝΟΜΑ, ΟΝ_PΑΤRΟΣ , ΗΜ_GΕΝΝΗSIS, ΟDΟΣ, AR, TK, POLH, THL)
Λύση
UPDATE ATZENTA
SET THL=
‘23210-
WHERE AA=1234
Διορθώστε την δομή του πίνακα ΑΤΖΕΝΤΑ και προσθέστε ακόμη ένα πεδίο
με όνομα EMAIL
που θα έχει τύπο δεδομένων VARCHAR(20).
Λύση
ALTER TABLE ATZENTA ADD EMAIL VARCHAR(20)
Διορθώστε την δομή του πίνακα ΑΤΖΕΝΤΑ και τροποποιήστε τον τύπο
δεδομένων του πεδίου EMAIL
ώστε να έχει τύπο δεδομένων VARCHAR(50).
Λύση
ALTER TABLE ATZENTA MODIFY EMAIL VARCHAR(50)
Διορθώστε την δομή του πίνακα ΑΤΖΕΝΤΑ και διαγράψτε το πεδίο EMAIL
Λύση
ALTER TABLE ATZENTA DROP EMAIL
Διαγράψτε όλες τις εγγραφές από τον πίνακα ΑΤΖΕΝΤΑ.
Λύση
DELETE FROM ATZENTA
Διαγράψτε τον
πίνακα ΑΤΖΕΝΤΑ.
Λύση
DROP TABLE
ATZENTA
Α. Δημιουργήστε
με SQL τον
πίνακα KATEXOYN
από το παρακάτω σχήμα βάσης.
Β. Δημιουργήστε
με SQL
ένα ερώτημα που θα προβάλει αναλυτικά όλα τα απαραίτητα πεδία σχετικά με τα
ακίνητα που κατέχει ο κάθε ιδιοκτήτης, και την έκταση ακριβώς που κατέχει σε
κάθε ακίνητο.
Γ. Δημιουργήστε με SQL ένα ερώτημα που θα προβάλει τον
κωδικό του ιδιοκτήτη και την συνολική έκταση που κατέχει ο κάθε ιδιοκτήτης.
Δ. Δημιουργήστε
με SQL
ένα ερώτημα που θα προβάλει τον κωδικό του ιδιοκτήτη και την συνολική έκταση
που κατέχει ο κάθε ιδιοκτήτης για τους
ιδιοκτήτες που κατέχουν συνολικά πάνω από 10.000 τμ.
Ε. Δημιουργήστε με SQL ένα ερώτημα που θα προβάλει
κωδικό του μεσίτη και την συνολική αντικειμενική αξία που έχουν όλα τα ακίνητα
που διαχειρίζεται η οποία ξεπερνά το 1.000.000 ευρώ .
Στ. Δημιουργήστε
με SQL
ένα ερώτημα που θα προβάλει τις θέσεις των ακινήτων με τον μεγαλύτερο
συντελεστή δόμησης.
Ζ. Προβάλετε
με SQL τα
στοιχεία του μεσίτη που διαχειρίζεται τα περισσότερα ακίνητα.
Η. Προβάλετε
με SQL τα
στοιχεία του Ιδιοκτήτη που κατέχει τα περισσότερα ακίνητα.
Θ. Προβάλετε
με SQL τα
στοιχεία των Ιδιοκτητών με τον αριθμό των ακινήτων που κατέχουν ταξινομημένα
κατά φθίνουσα σειρά. Δηλ από τα περισσότερα ακίνητα προς τα λιγότερα.
Ι. Επαναλάβετε
το παραπάνω ερώτημα Θ χρησιμοποιώντας παραγόμενες σχέσεις και όχι όψεις.
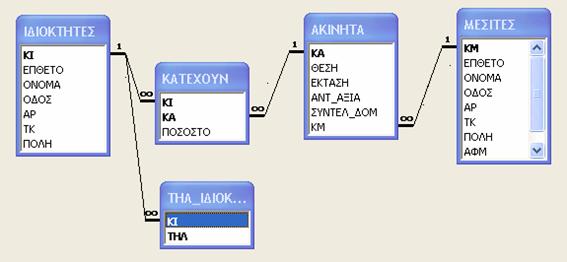
Λύση
Α.
CREATE TABLE KATEXOYN (
KI INT NOT NULL,
KA INT NOT NULL,
ΠΟΣΟΣΤΟ REAL ,
PRIMARY KEY (KI,KA),
FOREIGN KEY KI REFERENCES ΙΔΙΟΚΤΗΤΕΣ(ΚΙ),
FOREIGN KEY KΑ REFERENCES ΑΚΙΝΗΤΑ(ΚΑ) )
Β.
SELECT ΚΑΤΕΧΟΥΝ.KI,
ΕΠΙΘΕΤΟ, ΟΝΟΜΑ, ΤΗΛ, ΚΑΤΕΧΟΥΝ. ΚΑ, ΘΕΣΗ, ΑΝΤ_ΑΞΙΑ, ΣΥΝΤΕΛ_ΔΟΜ, (ΕΚΤΑΣΗ *
ΠΟΣΟΣΤΟ) AS ΙΔΙΟΚΤΗΤΗ_ΕΚΤΑΣΗ
FROM ΙΔΙΟΚΤΗΤΕΣ INNER JOIN
(ΚΑΤΕΧΟΥΝ INNER JOIN ΑΚΙΝΗΤΑ
ΟΝ ΚΑΤΕΧΟΥΝ.ΚΑ= ΑΚΙΝΗΤΑ.ΚΑ)
ON ΙΔΙΟΚΤΗΤΕΣ.ΚΙ=ΚΑΤΕΧΟΥΝ.ΚΙ
Στο ερώτημα αυτό δίνουμε προσοχή ότι η έκταση που
κατέχει ένας ιδιοκτήτης υπολογίζεται από το γινόμενο της ΕΚΤΑΣΗΣ του ακινήτου
επί το ΠΟΣΟΣΤΟ που κατέχει. Δηλ. από το 100% της έκτασης ενός ακινήτου 200τμ
ένας ιδιοκτήτης με ποσοστό 20% κατέχει (20 * 200) / 100 = 4000/100= 40 τμ.
Γ.
SELECT ΚΑΤΕΧΟΥΝ.KI, SUM(ΕΚΤΑΣΗ
* ΠΟΣΟΣΤΟ) AS ΣΥΝΟΛ_ΙΔ_ΕΚΤΑΣΗ
FROM ΚΑΤΕΧΟΥΝ
INNER JΟΙΝ ΑΚΙΝΗΤΑ
ΟΝ
ΚΑΤΕΧΟΥΝ.ΚΑ= ΑΚΙΝΗΤΑ.ΚΑ
GROUP BY ΚΑΤΕΧΟΥΝ.KI
Δ.
SELECT ΚΑΤΕΧΟΥΝ.KI, SUM(ΕΚΤΑΣΗ * ΠΟΣΟΣΤΟ) AS
ΣΥΝΟΛ_ΙΔ_ΕΚΤΑΣΗ
FROM ΚΑΤΕΧΟΥΝ
INNER JΟΙΝ ΑΚΙΝΗΤΑ
ΟΝ
ΚΑΤΕΧΟΥΝ.ΚΑ= ΑΚΙΝΗΤΑ.ΚΑ
GROUP BY ΚΑΤΕΧΟΥΝ.KI
HAVING
SUM(ΕΚΤΑΣΗ * ΠΟΣΟΣΤΟ) >= 10.000
Ε.
SELECT MESITES.KM, SUM(ANT_AΞΙΑ) AS
ΣΥΝΟΛ_ΑΞΙΑ
FROM ΜΕΣΙΤΕΣ INNER JΟΙΝ ΑΚΙΝΗΤΑ
ΟΝ ΜΕΣΙΤΕΣ.ΚΜ= ΑΚΙΝΗΤΑ.ΚΜ
GROUP BY ΜΕΣΙΤΕΣ.ΚΜ
HAVING SUM(ANT_AΞΙΑ) >=
1.000.000
Στ.
SELECT ΘΕΣΗ
FROM ΑΚΙΝΗΤΑ
WHERE ANT_ΑΞΙΑ IN (SELECT MAX(ANT_ΑΞΙΑ)
FROM AKINHTA
Z.
Για να υλοποιήσουμε αυτό το ερώτημα θα πρέπει να
βρούμε πρώτα πόσα ακίνητα διαχειρίζεται κάθε μεσίτης και μετά να βρούμε ποιος
είναι αυτός που έχει τα περισσότερα. Για να το πετύχουμε αυτό θα
χρησιμοποιήσουμε δύο όψεις.
1. CREATE
VIEW V1 AS
SELECT KM, COUNT(KA) AS ΠΛΗΘΟΣ1
FROM AKINHTA
GROUP BY KM
2. CREATE
VIEW V2 AS
SELECT ΜΕΣΙΤΕΣ.KM,
ΕΠΙΘΕΤΟ, ΟΝΟΜΑ, ΤΗΛ, ΠΛΗΘΟΣ1
FROM ΜΕΣΙΤΕΣ INNER JOIN V1 ON ΜΕΣΙΤΕΣ.KM=V1.KM
WHERE ΠΛΗΘΟΣ1 ΙΝ (SELECT
MAX(ΠΛΗΘΟΣ1)
FROM V1)
H.
Για να υλοποιήσουμε και αυτό το ερώτημα θα πρέπει
να βρούμε πρώτα πόσα ακίνητα κατέχει κάθε
ιδιοκτήτης και μετά να βρούμε ποιος είναι αυτός που κατέχει τα περισσότερα. Για
να το πετύχουμε αυτό θα χρησιμοποιήσουμε δύο όψεις.
1. CREATE
VIEW V1 AS
SELECT ΚΙ, COUNT(KA) AS ΠΛΗΘΟΣ2
FROM ΚΑΤΕΧΟΥΝ
GROUP BY KΙ
2. CREATE
VIEW V2 AS
SELECT ΙΔΙΟΚΤΗΤΕΣ.KΙ, ΕΠΙΘΕΤΟ, ΟΝΟΜΑ, ΤΗΛ, ΠΛΗΘΟΣ2
FROM ΙΔΙΟΚΤΗΤΕΣ INNER JOIN V1
ON ΙΔΙΟΚΤΗΤΕΣ.KI=V1.KI
WHERE ΠΛΗΘΟΣ2 ΙΝ (SELECT MAX(ΠΛΗΘΟΣ2)
FROM V1)
Θ.
Για να υλοποιήσουμε και αυτό το ερώτημα θα πρέπει
να βρούμε πρώτα πόσα ακίνητα κατέχει
κάθε ιδιοκτήτης και μετά να ταξινομήσουμε σε φθίνουσα σειρά το πλήθος
των ακινήτων. Για να το πετύχουμε αυτό θα χρησιμοποιήσουμε πάλι δύο όψεις.
1. CREATE
VIEW V1 AS
SELECT ΚΙ, COUNT(KA) AS ΠΛΗΘΟΣ2
FROM ΚΑΤΕΧΟΥΝ
GROUP BY KΙ
2. CREATE
VIEW V2 AS
SELECT ΙΔΙΟΚΤΗΤΕΣ.KΙ, ΕΠΙΘΕΤΟ, ΟΝΟΜΑ, ΤΗΛ, ΠΛΗΘΟΣ2
FROM ΙΔΙΟΚΤΗΤΕΣ INNER JOIN V1
ON ΙΔΙΟΚΤΗΤΕΣ.KI=V1.KI
ORDER BY ΠΛΗΘΟΣ2 DESC
Ι.
Για να υλοποιήσουμε και αυτό το ερώτημα θα πρέπει
να βρούμε πρώτα πόσα ακίνητα κατέχει
κάθε ιδιοκτήτης σε μια παραγόμενη σχέση
και μετά να ταξινομήσουμε σε φθίνουσα σειρά το πλήθος των ακινήτων.
 SELECT KΙ, ΜAX( ΠΛΗΘΟΣ2)
SELECT KΙ, ΜAX( ΠΛΗΘΟΣ2)
FROM (SELECT ΚΙ, COUNT(KA) AS ΠΛΗΘΟΣ2
FROM ΚΑΤΕΧΟΥΝ
GROUP BY KΙ)
AS NEW_TABLE(KI,ΠΛΗΘΟΣ2)
ORDER BY ΠΛΗΘΟΣ2 DESC
Δημιουργήστε με SQL ένα ερώτημα που θα προβάλει
ΕΠΙΘΕΤΟ, ΟΝΟΜΑ, ΤΗΛ από τους ΙΔΙΟΚΤΗΤΕΣ
και τους ΜΕΣΙΤΕΣ που είναι από την πόλη ΣΕΡΡΕΣ
Λύση
Για να δώσει αποτελέσματα σωστά αυτό το ερώτημα θα
πρέπει οι δύο αυτοί πίνακες να έχουν όμοια πεδία ίδιου τύπου δεδομένων, ώστε να
γίνει η ένωση των συνόλων.
(SELECT ΕΠΙΘΕΤΟ, ΟΝΟΜΑ, ΤΗΛ
FROM ΙΔΙΟΚΤΗΤΕΣ
WHERE ΠΟΛΗ=’ΣΕΡΡΕΣ’)
(SELECT ΕΠΙΘΕΤΟ, ΟΝΟΜΑ, ΤΗΛ
FROM ΜΕΣΙΤΕΣ
WHERE ΠΟΛΗ=’ΣΕΡΡΕΣ’)
ΚΕΦΑΛΑΙΟ 6. Επεκτάσεις
SQL.
6.1 Εισαγωγή στις επεκτάσεις SQL
Στο κεφάλαιο αυτό ασχολούμαστε με τις επεκτάσεις της γλώσσα SQL και συγκεκριμένα με διαδικασίες, συναρτήσεις και σκανδάλες ( τυποποίηση SQL:1999). Εξηγούμε τις νέες εντολές (begin .end, while, for, if then else, until, declare κλπ) και την δυνατότητα σύνταξης όπως μια γενική γλώσσα προγραμματισμού. Στο ίδιο πλααίσιο κινούνται και οι πρόσθετες προτάσεις της Transact-SQL, που αναφέρονται σαν "επεκτάσεις SQL’’ και αφορούν αποθηκευμένες διαδικασίες ή σκρίπτ που αποθηκεύονται στον διακομιστή και μπορούν να ξαναχρησιμοποιηθούν
Σε αυτό το κεφάλαιο η φράση Μπλοκ Προτάσεων ή αλλιώς δέσμη εντολών θα χρησιμοποιηθεί πολύ συχνά. Μια δέσμη εντολών είναι μια αλληλουχία προτάσεων SQL και επεκτάσεων SQL που στέλνονται στον SQL Server για να εκτελεστούν μαζί.
Οι προτάσεις ορισμού δεδομένων όπως CREATE VIEW, CREATE
PROCEDURE, CREATE RULE, CREATE TRIGGER και CREATE DEFAULT πρέπει να είναι η
καθεμία η μόνη πρόταση μέσα σε μια δέσμη.
Ένα μπλοκ επιτρέπει την δημιουργία μονάδων με μια ή περισσότερες προτάσεις SQL. Κάθε μπλοκ αρχίζει με την πρόταση BEGIN και τελειώνει με την πρόταση END:
BEGIN
Πρόταση 1
πρόταση_2
END
Ένα μπλοκ μπορεί να χρησιμοποιηθεί μέσα στην πρόταση IF για να επιτρέπει την εκτέλεση περισσοτέρων της μιας προτάσεων, ανάλογα με μια ορισμένη συνθήκη
IF Συνθήκη Αληθής
BEGIN
πρόταση 1
πρόταση_2
END
ELSE BEGIN
πρόταση 3
πρόταση_4
END
Στο παράδειγμα αυτό
γίνεται έλεγχος με την εντολή IF για το εάν το πλήθος των σπουδαστών που πέρασαν το μάθημα με κωδικό ‘403’
είναι πάνω από 100. Στην περίπτωση που ισχύει αυτή η συνθήκη εμφανίζεται ένα
μήνυμα, διαφορετικά εμφανίζονται τα στοιχεία των σπουδαστών που πέρασαν το
μάθημα αυτό.
IF (SELECT COUNT(*)
FROM ΒΑΘΜΟΛΌΓΙΑ
WHERE ΚΜ = ‘403‘ AND ΒΑΘΜΟΣ >= 5
GROUP BY ΑΜ ) > 100
PRINT ‘Ο αριθμός των σπουδαστών που πέρασαν το μάθημα 403 είναι πάνω από 100'
ELSE BEGIN
PRINT ‘Οι σπουδαστές που πέρασαν στο μάθημα 403 είναι:’
SELECT ΣΠΟΥΔΑΣΤΕΣ.ΑΜ, ΕΠΙΘΕΤΟ, ΟΝΟΜΑ
FROM ΣΠΟΥΔΑΣΤΕΣ, ΒΑΘΜΟΛΟΓΙΑ
WHERE ΣΠΟΥΔΑΣΤΕΣ.ΑΜ = ΒΑΘΜΟΛΟΓΙΑ.ΑΜ AND ΚΜ=‘403’
END
Άλλη μια επέκταση SQL είναι και η πρόταση PRINT. Επιστρέφει το μήνυμα που χρήστη που εσωκλείεται σε απλά εισαγωγικά.
Η πρόταση WHILE εκτελεί επαναληπτικά προτάσεις SQL που περικλείονται μέσα σε ένα μπλοκ, όσο η συνθήκη της while επιστρέφει τιμή true.
Ενα μπλοκ μέσα στην πρόταση WHILE μπορεί να περιέχει επιπλέον και τις παρακάτω εντολές:
BREAK για να σταματά την εκτέλεση των προτάσεων μέσα στο μπλοκ και αρχίζει την εκτέλεση της πρότασης που ακολουθεί αυτό το μπλοκ.
CONTINUE για να σταματά μέσα στο μπλοκ την εκτέλεση των υπόλοιπων προτάσεων και να αρχίζει την εκτέλεση του μπλοκ από την αρχή.
ΠΑΡΑΔΕΙΓΜΑ 6.2
Το παράδειγμα αυτό
ελέγχει διαρκώς σε έναν βρόγχο while το άθροισμα του προϋπολογισμού από τον πίνακα ΕΡΓΑ. Στην περίπτωση που το
άθροισμα είναι μικρότερο από 100.000 ξεκινάει η διαδικασία αύξησης της τιμής του πεδίου ΠΡΟΫΠΟΛΟΓΙΣΜΟΣ
κατά 50%. Εάν η τιμή του πεδίου αυτού ξεπεράσει τις 50.000 η εκτέλεση του
βρόγχου σταματά διαφορετικά συνεχίζει η αύξηση της τιμής του κάθε πεδίου.
WHILE (SELECT SUM(ΠΡΟΫΠΟΛΟΓΙΣΜΟΣ)
FROM ΕΡΓΟ) < 100.000
BEGIN
UPDATE ΕΡΓΟ SET ΠΡΟΫΠΟΛΟΓΙΣΜΟΣ = ΠΡΟΫΠΟΛΟΓΙΣΜΟΣ *1.5
IF (SELECT ΠΡΟΫΠΟΛΟΓΙΣΜΟΣ)
FROM ΕΡΓΟ) > 50.000 BREAK
ELSE CONTINUE
END
Η εκτέλεση του παραδείγματος δίνει την πχ παρακάτω έξοδο:
(3 rows affected)
(2 rows affected)
Οι τοπικές μεταβλητές αποτελούν μια επιπλέον επέκταση στην γλώσσα Transact-SQL. Ο λόγος ύπαρξης τους είναι για να αποθηκεύουν τιμές τοπικά όπως λέει και το όνομά τους.
Είναι "τοπικές" επειδή χρησιμοποιούνται μόνο μέσα στην ίδια δέσμη, όπου δηλώνονται. Οι μεταβλητές αυτές χρησιμοποιούν το πρόθεμα @ πριν από το όνομα τους.
Ο SQL Server υποστηρίζει επίσης καθολικές μεταβλητές οι οποίες δηλώνονται με δύο συνεχόμενα ‘παπάκια’ @@ πριν από το όνομα της μεταβλητής.
Κάθε τοπική μεταβλητή ορίζεται με την εντολή DECLARE. Όταν ορίζεται μια μεταβλητή θα πρέπει να οριστεί και ο αντίστοιχος τύπος δεδομένων
Η εκχώρηση μιας τιμής σε μια τοπική μεταβλητή γίνεται χρησιμοποιώντας τα παρακάτω:
1.
Την ειδική μορφή της πρότασης SELECT
2. Την
πρόταση SET
Στο παράδειγμα αυτό οι τιμές αγοράς των προϊόντων από τον πίνακα ΑΠΟΘΗΚΗ αυξάνονται κατά ένα ποσοστό μόνο στην περίπτωση που είναι μικρότερες από την μέση τιμή όλων των τιμών, διαφορετικά εμφανίζεται ένα μήνυμα.
DECLARE @ΜΕΣΗ_ΤΙΜΗ_ΑΓ REAL, @ΑΥΞ_ΤΙΜΗΣ
REAL
SET @ΑΥΞ_ΤΙΜΗΣ = 10
SELECT @ΜΕΣΗ_ΤΙΜΗ_ΑΓ = AVG(ΤΙΜΗ_ΑΓ) FROM ΑΠΟΘΗΚΗ
IF (SELECT ΤΙΜΗ_ΑΓ
FROM ΑΠΟΘΗΚΗ
WHERE ΚΩΔ_ΕΙΔΟΥΣ=‘ΑΑ05') < @ΜΕΣΗ_ΤΙΜΗ_ΑΓ
BEGIN
UPDATE ΑΠΟΘΗΚΗ
SET ΤΙΜΗ_ΑΓ = ΤΙΜΗ_ΑΓ + @ΑΥΞ_ΤΙΜΗΣ
WHERE ΚΩΔ_ΕΙΔΟΥΣ =‘ΑΑ05'
PRINT ‘Η ΤΙΜΗ ΑΓΟΡΑΣ ΑΥΞΗΘΗΚΕ ΚΑΤΑ @ΑΥΞ_ΤΙΜΗΣ'
END
ELSE PRINT ‘Η ΤΙΜΗ ΑΓΟΡΑΣ ΔΕΝ ΑΛΑΞΕ’
Έχει την ίδια λειτουργικότητα μέσα σε μια δέσμη με την πρόταση BREAK μέσα στην WHILE.
Αυτό σημαίνει ότι η RETURN κάνει την εκτέλεση της δέσμης να
τερματίσει και να αρχίσει να εκτελείται η πρώτη πρόταση που ακολουθεί την δέσμη.
Διακλαδώνει σε μια ετικέτα, που βρίσκεται μπροστά από μια πρόταση Transact-SQL μέσα σε μια δέσμη
Παράγει ένα σφάλμα που ορίζεται από τον χρήστη και θέτει μια ένδειξη σφάλματος συστήματος. Ένα μήνυμα σφάλματος που ορίζεται από τον χρήστη πρέπει να είναι μεγαλύτερο από 50000.
Όλοι οι αριθμοί σφάλματος που είναι < = 50000 είναι αριθμοί που ορίζονται από το σύστημα και δεσμεύονται από το SQL Server.
Οι τιμές σφάλματος αποθηκεύονται στην καθολική μεταβλητή @@ERROR την οποία ο προγραμματιστής μπορεί να την χρησιμοποιήσει για να ορίσει και να εμφανίσει βοηθητικά μηνύματα σε περίπτωση σφάλματος.
Ορίζει το χρονικό διάστημα που πρέπει να περιμένει το σύστημα, πριν να εκτελέσει την επόμενη πρόταση στην δέσμη. Η σύνταξη αυτής της πρότασης είναι
WAITFOR {DELAY 'χρόνος' | TIME 'ώρα'}
Η DELAY λέει στον SQL Server να περιμένει μέχρι να περάσει ο καθορισμένος χρόνος ενώ η TIME καθορίζει μια ώρα σε μια αποδεκτή μορφή δεδομένων ημερομηνίας/ώρας
6.2 Αποθηκευμένες Διαδικασίες (Stored Procedures)
Είναι ένα ειδικό είδος δέσμης εντολών που χρησιμοποιεί την γλώσσα SQL και τις επεκτάσεις SQL. Αποθηκεύεται στον διακομιστή της βάσης δεδομένων για να βελτιώσει την απόδοση και την αποφυγή επαναληπτικών εργασιών. Ο SQL Server υποστηρίζει τις αποθηκευμένες διαδικασίες Δημιουργούνται χρησιμοποιώντας την γλώσσα ορισμού δεδομένων
Κάθε αποθηκευμένη διαδικασία δέχεται και τα αντίστοιχα ορίσματα της κάθε φορά που καλείται. Οι αποθηκευμένες διαδικασίες μπορούν προαιρετικά να επιστρέψουν μια τιμή, που θα εμφανίζει κάποιες πληροφορίες που θα ορίζονται από τον χρήστη ή, στην περίπτωση ενός σφάλματος, το αντίστοιχο μήνυμα σφάλματος.
Μια αποθηκευμένη διαδικασία μεταγλωττίζεται εκ των προτέρων, πριν να αποθηκευτεί σαν αντικείμενο μέσα στην βάση δεδομένων. Το πλεονέκτημα είναι εξάλειψη της επαναλαμβανόμενης μεταγλώττισης της διαδικασίας και η αύξηση της απόδοσης της εκτέλεσης.
Υπάρχουν και πλεονεκτήματα που αφορούν τον όγκο των δεδομένων. Ειδικότερα, χρειάζονται λιγότερα από 50 bytes για να κληθεί μια αποθηκευμένη διαδικασία παρά να εκτελεστούν οι αρκετές χιλιάδες bytes εντολών που περιέχονται σε μία διαδικασία.
Οι διαδικασίες χρησιμοποιούνται συχνά για τον έλεγχο της εξουσιοδότησης κατά την πρόσβαση των χρηστών σε κάποιο πίνακα.
Για την εκτέλεση πολλαπλών εντολών ορισμού δεδομένων και καθώς χειρισμού δεδομένων, μιας βάσης δεδομένων. Δηλ. μπορούν σε μια διαδικασία να γραφούν όλες οι εντολές CREATE TABLE για να δημιουργηθούν αυτόματα όλοι οι πίνακες μιας βάσης.
6.2.1 Δημιουργία και Εκτέλεση Αποθηκευμένων Διαδικασιών
Για την δημιουργία μιας αποθηκευμένης διαδικασίας χρησιμοποιείται η
εντολή CREATE PROCEDURE η σύνταξη της
οποίας περιγράφεται παρακάτω.
Σύνταξη
CREATE PROC[EDURE] [ιδιοκτήτης.]όνομα_διαδικασίας [;αριθμός]
[({@παράμετρος1 } τύπος1 [=προεπιλογή1]
[({@παράμετρος2 } τύπος2 [=προεπιλογή2]...
[WITH {RECOMPILE | ENCRYPTION }]
AS
BEGIN
Δέσμη ΕΝΤΟΛΩΝ
….
END
Ιδιοκτήτης είναι το όνομα του χρήστη στον οποίο έχει εκχωρηθεί η ιδιοκτησία της συνάρτησης που έχει οριστεί από τον χρήστη.
Όνομα_διαδικασίας είναι το όνομα της νέας διαδικασίας.
@παράμετρος1, @παράμετρος2,... παράμετροι εισόδου
τύπος1, τυπος2, ... καθορίζουν τους τύπους δεδομένων.
Οι παράμετροι είναι τιμές που περνούν από τον καλούντα την συνάρτηση που δημιουργείται από τον χρήστη και χρησιμοποιούνται μέσα στην συνάρτηση.
προεπιλογή1, προεπιλογή2 καθορίζουν την προαιρετική προεπιλεγμένη τιμή της αντίστοιχης παραμέτρου, μπορεί επίσης να είναι NULL
;number Είναι ένας αυθαίρετος αριθμός που χρησιμοποίται για να ομαδοποιήσει διαδικασίες με το ιδιο όνομα ώστε να μπορούν να διαγραφούν όλες μαζί μα την εντολή DROP PROCEDURE. Για παραδειγμα σε μια εφαρμογή μπορεί να υπάρχουν διαδικασίες με όνομα Παραγγελία;1, Παραγγελία;2, Παραγγελία;3 ……. Με την εντολή DROP PROCEDURE Παραγγελία διαγράφονται όλες οι διαδικασίες μαζί.
Μία διαδικασία μπορεί να έχει το πολύ 2,100 παραμέτρους εισόδου..
Ορίστε τις παραμέτρους εισόδου χρησιμοποιώντας τον χαρακτήρα @.
Default είναι η προεπιλεγμένη τιμή που μπορεί να πάρει μια παράμετρος εισόδου
WITH RECOMPILE καθορίζει ότι οι εντολές της διαδικασίας θα ξαναμεταφράζονται κάθε φορά που καλείται η διαδικασία.
WITH ENCRYPTION κρυπτογραφεί τις στήλες του πίνακα συστήματος που περιέχουν το κείμενο της πρότασης CREATE PROCEDURE
AS Καθορίζει τις ενέργειες που πρόκειται να εκτελέσει η διαδικασία
Το μέγιστο μέγεθος μιας διαδικασίας είναι 128 MB.
BEGIN-END είναι το μπλοκ που περιέχει τις δέσμες εντολών για την υλοποίηση της διαδικασίας.
Παράδειγμα 6.4
Στην διαδικασία αυτή αυξάνεται η τιμή ενός πεδίου κατά ένα ποσοστό που λαμβάνεται ως είσοδος από την τοπική μεταβλητή @ΠΟΣΟΣΤΟ η οποία έχει κάποια προεπιλεγμένη τιμή.
CREATE PROCEDURE ΑΥΞΗΣΗ_ΛΙΑΝ_ΤΙΜΗΣ
(@ΠΟΣΟΣΤΟ REAL=5)
AS UPDATE ΑΠΟΘΗΚΗ
SET TIMH_ΛΙΑΝ=ΤΙΜΗ_ΛΙΑΝ*(1+@ΠΟΣΟΣΤΟ/100)
Παράδειγμα 6.5
Ομοοίως και το παράδειγμα αυτό που αυξάνει την τιμή ενός πεδίου όταν ισχύει μια συνθήκη.
CREATE PROCEDURE ΑΥΞΗΣΗ_bathmon ( @ΤΙΜΗ REAL=0.5)
AS UPDATE [ΒΑΘΜΟΙ_ΣΠΟΥΔΑΣΤΩΝ]
SET
ΒΑΘΜΟΣ=ΒΑΘΜΟΣ+@ΤΙΜΗ
WHERE ΒΑΘΜΟΣ >=4 ΑΝD ΒΑΘΜΟΣ <5
6.2.2 Εκτέλεση Αποθηκευμένων Διαδικασιών
Μια διαδικασία εκτελείται με την εντολή EXEC. H εντολή αυτή συντάσεται είτε μέσα από μια γλώσσα προγραμματισμού προγραμματίζοντας την ιδιότητα ΤΕΧΤ ενός dataset ή από την επιλογή Query του SQL Server ή εκτελώντας ως ένα ερώτημα.
ΣΥΝΤΑΞΗ
EXECUTE Αποθ_Διαδικασία Παράμετρος_Εισόδου
EXEC[UTE] [@επιστρ_κατάσταση =] όνομα διαδικασίας [;αριθμός] {[[@παράμετρος1 =] τιμή | [@παράμετρος1 = ]@μεταβλητή]}..
[WITH RECOMPILE]
Παράδειγμα 6.6
EXECUTE ΑΥΞΗΣΗ_ΛΙΑΝ_ΤΙΜΗΣ 15
EXECUTE ΑΥΞΗΣΗ_bathmon 3
6.3 Συναρτήσεις που Ορίζονται από τον Χρήστη (User Defined Functions )
Στις γλώσσες προγραμματισμού υπάρχουν γενικά δύο τύποι ρουτινών: Διαδικασίες & Συναρτήσεις. Οι διαδικασίες αποτελούνται από αρκετές προτάσεις που έχουν μηδέν ή περισσότερες παραμέτρους εισόδου, αλλά δεν επιστρέφουν παραμέτρους εξόδου. Σε αντίθεση με αυτό, οι συναρτήσεις γενικά επιστρέφουν μια ή περισσότερες παραμέτρους.
Οι συναρτήσεις στις επεκτάσεις SQL δεν υποστηρίζουν παραμέτρους εξόδου,
αλλά επιστρέφουν μια μόνο τιμή δεδομένων.
6.3.1 Δημιουργία και Εκτέλεση των
Συναρτήσεων
CREATE FUNCTION [ιδιοκτήτης.] όνομα συνάρτησης
[({@παράμετρος1 } τύπος1 [= προεπιλογή1])] ([({@παράμετρος2 } τύπος2 [= προεπιλογή2] )]}...
RETURNS [βαθμωτός τύπος | ©μεταβλητή] TABLE}
[WITH {ENCRYPTION | SCHEMABINDING} [AS] {μπλοκ | RETURN (πρόταση)}
Ιδιοκτήτης είναι το όνομα του χρήστη στον οποίο έχει εκχωρηθεί η ιδιοκτησία της συνάρτησης που έχει οριστεί από τον χρήστη.
Όνομα_συνάρτησης είναι το όνομα της νέας συνάρτησης.
@παράμετρος1, @παράμετρος2,... παράμετροι εισόδου
τύπος1, τυπος2, ... καθορίζουν τους τύπους δεδομένων.
Οι παράμετροι είναι τιμές που περνούν από τον καλούντα την συνάρτηση που δημιουργείται από τον χρήστη και χρησιμοποιούνται μέσα στην συνάρτηση.
προεπιλογή1, προεπιλογή2 καθορίζουν την προαιρετική προεπιλεγμένη τιμή της αντίστοιχης παραμέτρου,μπορεί επίσης να είναι NULL
RETURNS ορίζει ένα τύπο δεδομένων της τιμής που επιστρέφεται από την συνάρτηση που ορίζεται από τον χρήστη.
Αυτός ο τύπος δεδομένων μπορεί να είναι οποιοσδήποτε από τους πρότυπους τύπους δεδομένων που υποστηρίζονται από το SQL Server, περιλαμβανομένου και του τύπου δεδομένων TABLE.
(Οι μόνοι πρότυποι τύποι δεδομένων που δεν μπορείτε να χρησιμοποιήσετε είναι ο τύπος δεδομένων TIMESTAMP και τα δεδομένα τύπου text/image.)
WITH ENCRYPTION κρυπτογραφεί τις στήλες του πίνακα συστήματος που περιέχουν το κείμενο της πρότασης CREATE FUNCTION
WITH SCHEMABINDING, δεσμεύει την συνάρτηση που ορίζεται από τον χρήστη στα αντικείμενα βάσης δεδομένων στα οποία αναφέρεται.
Κάθε προσπάθεια τροποποίησης της δομής του αντικειμένου βάσης δεδομένων στο οποίο αναφέρεται η συνάρτηση αποτυγχάνει
μπλοκ είναι το μπλοκ BEGIN-END που περιέχει την υλοποίηση της συνάρτησης.
Η τελική πρόταση του μπλοκ πρέπει να είναι μια πρόταση RETURN με ένα όρισμα.
Η τιμή του ορίσματος είναι η τιμή που επιστρέφεται από την συνάρτηση.
Στο σώμα ενός μπλοκ BEGIN-END, μόνο οι παρακάτω προτάσεις επιτρέπονται:
•
Προτάσεις εκχώρησης σαν την SET
•
Προτάσεις ελέγχου ροής σαν τις WHILE και IF
• Προτάσεις DECLARE που ορίζουν τοπικές μεταβλητές δεδομένων
• Προτάσεις SELECT που περιέχουν λίστες SELECT με εκφράσεις που εκχωρούν σε μεταβλητές που είναι τοπικές στην συνάρτηση
• Προτάσεις INSERT, UPDATE και DELETE, που τροποποιούν μεταβλητές τύπου δεδομένων TABLE, που είναι τοπικές στην συνάρτηση
ΠΑΡΑΔΕΙΓΜΑ 6.7
Αυτή η συνάρτηση υπολογίζει πρόσθετα συνολικά κόστη που προκύπτουν αν αυξηθούν οι προϋπολογισμοί των έργων
CREATE FUNCTION computecosts (©percent INT =10)
RETURNS DECIMAL(16,2) AS
BEGIN
DECLARE @additional_costs DEC (14,2), @sum_budget deed 6,2)
SELECT @sum_budget = SUM (budget) FROM project
SET @additional_costs = @sum_budget * @percent/100
RETURN @additional_costs
END
ΠΑΡΑΔΕΙΓΜΑ 6.8
Η συνάρτηση ΣΠΟΥΔΑΣΤΕΣ_ΜΑΘΗΜΑ χρησιμοποιείται για να εμφανίσει ονόματα όλων των σπουδαστών που έχουν βαθμολογηθεί σε ένα συγκεκριμένο μάθημα. Η παράμετρος εισόδου @ΚΩΔ_ΜΑΘ καθορίζει ένα κωδικό μαθήματος. Η συνάρτηση αυτή τελικά επιστρέφει ως έξοδο έναν πίνακα με πολλές γραμμές, Η φράση RETURNS περιέχει τον τύπο δεδομένων TABLE. Η συνάρτηση αυτή επιστρέφει μια μεταβλητή τύπου TABLE και τα αποτελέσματά της μπορούν στην συνέχεια να χρησιμοποιηθούν σα να ήταν πίνακας της βάσης.
CREATE FUNCTION ΣΠΟΥΔΑΣΤΕΣ_ΜΑΘΗΜΑ (@ΚΩΔ_ΜΑΘ VARCHAR(4))
RETURNS TABLE AS RETURN
(SELECT ΕΠΙΘΕΤΟ, ΟΝΟΜΑ, ΤΗΛ
FROM ΣΠΟΥΔΑΣΤΕΣ, ΒΑΘΜΟΛΟΓΙΑ
WHERE ΣΠΟΥΔΑΣΤΕΣ.ΑΜ = ΒΑΘΜΟΛΟΓΙΑ.ΑΜ
AND ΚΜ = @ΚΩΔ_ΜΑΘ)
ΠΑΡΑΔΕΙΓΜΑ 6.9
εκτέλεση της
παραπάνω συνάρτησης
SELECT * FROM ΣΠΟΥΔΑΣΤΕΣ_ΜΑΘΗΜΑ (‘403ΒΔ_Θ')
Το αποτέλεσμα είναι
ΕΠΙΘΕΤΟ ΟΝΟΜΑ ΤΗΛ
ΔΗΜΗΤΡΙΟΥ ΙΩΑΝΝΗΣ 23456
ΠΑΠΠΑ ΕΙΡΗΝΗ 34567
ΒΡΥΖΑΣ ΖΗΣΗΣ 45678
63.2 ALTER FUNCTION, τροποποιεί την δομή μιας συνάρτησης που ορίζεται από τον χρήστη. Η πρόταση ALTER FUNCTION χρησιμοποιείται συνήθως για να καταργήσει μια δέσμευση σχήματος. Ολες οι επιλογές της πρότασης ALTER FUNCTION αντιστοιχούν στις επιλογές με το ίδιο όνομα στην πρόταση CREATE FUNCTION.
6.3.3 DROP FUNCTION καταργείται μια συνάρτηση που ορίζεται από τον χρήστη Μόνο ο ιδιοκτήτης της συνάρτησης (ή τα μέλη των σταθερών ρόλων βάσης δεδομένων db_owner και sysadmin) μπορούν να καταργήσουν την συνάρτηση
6.4 ΣΚΑΝΔΑΛΕΣ
(Ερεθισμοί)- Triggers
Μία σκανδάλη ή αλλιώς ένας ερεθισμός είναι ένας μηχανισμός που καλείται όταν συμβαίνει μια συγκεκριμένη ενέργεια σε ένα συγκεκριμένο πίνακα και εκτελεί δέσμες εντολών που αφορούν το συγκεκριμένο πίνακα ή άλλους πίνακες. Κάθε ερεθισμός έχει τρία γενικά μέρη:
Ένα όνομα - Μια ενέργεια - Την εκτέλεση
Η ενέργεια ενός ερεθισμού μπορεί να είναι μια πρόταση INSERT, UPDATE ή DELETE.
To τμήμα εκτέλεσης μιας σκανδάλης περιέχει συνήθως μια αποθηκευμένη διαδικασία ή μια δέσμη εντολών. Μία σκανδάλη δημιουργείται χρησιμοποιώντας την πρόταση CREATE TRIGGER, που έχει την παρακάτω μορφή:
CREATE
TRIGGER trigger name ON tablename | viewname
{FOR |
AFTER | INSTEAD OF} { [INSERT] [,] [UPDATE] [,] [DELETE]}
[WITH
ENCRYPTION] AS {batch | IF UPDATE(column) [{AND|OR} UPDATE(column)] batch}
trigger_name είναι το όνομα του ερεθισμού. table_name είναι το όνομα του πίνακα για τον οποίο καθορίζεται ο ερεθισμός. Στον SQL Server 2000, μπορείτε επίσης να ορίσετε ερεθισμούς για όψεις/views.
ON tablename | viewname μια σκανδάλη μπορεί να εφαρμόζεται μόνο σε ένα πίνακα ή όψη.
AFTER και INSTEAD OF είναι δύο πρόσθετες επιλογές, που μπορείτε να ορίσετε σε μια σκανδάλη.
FOR είναι συνώνυμη της AFTER. Η AFTER ξεκινά την εκτέλεση της δέσμης εντολών μετά την εκκίνηση της σκανδάλης.
INSTEAD OF εκτελούνται αντί του αντίστοιχου συμβάντος INSERT, UPDATE ή DELETE της σκανδάλης.
Οι σκανδάλες AFTER μπορούν να εκτελεστούν μόνο σε πίνακες, ενώ αυτές που περιέχουν την επιλογή INSTEAD OF μπορούν να δημιουργηθούν και σε πίνακες και σε όψεις.
Οι επιλογές INSERT, UPDATE και DELETE καθορίζουν την ενέργεια της σκανδάλης δηλ τις εντολές SQL που θα εκτελεστούν μετά την ενεργοποίηση της σκανδάλης. Οι προτάσεις αυτές μπορούν να υπάρχουν ξεχωριστά η κάθε μια ή και συνδυασμός τους.
IF UPDATE χρησιμοποιείται σαν μια πρόσθετη συνθήκη σε περίπτωση εισαγωγής ή ενημέρωσης σε μια συγκεκριμένη στήλη ή στήλες του πίνακα. Στην πρόταση CREATE TRIGGER μπορούν να υπάρχουν περισσότερες από μια φράσεις IF UPDATE, και συνδυάζονται χρησιμοποιώντας τις λογικές συνθήκες AND και OR και είναι ισοδύναμη με τον ορισμό ενός περιορισμού επιπέδου στήλης.
Επιτρέπει η δημιουργία πολλαπλών σκανδάλων σε κάθε πίνακα. Μετά την δημιουργία της βάσης δεδομένων, μόνο ο ιδιοκτήτης της βάσης δεδομένων, ο διαχειριστής της γλώσσας ορισμού δεδομένων και ο ιδιοκτήτης του πίνακα στον οποίο έχει οριστεί ο ερεθισμός έχουν την εξουσιοδότηση να δημιουργήσουν μια σκανδάλη στην τρέχουσα βάση δεδομένων.
Σε κάθε εκτέλεση μιας σκανδάλης δημιουργούνται δύο εικονικοί πίνακες με ειδικά ονόματα. Ο πίνακας deleted και ο πίνακας inserted.
Η δομή αυτών των πινάκων είναι ισοδύναμη με την δομή του πίνακα στον οποίο αναφέρεται η σκανδάλη. Ο πίνακας deleted περιέχει αντίγραφα από τις γραμμές που διαγράφονται από τον πίνακα που έχει εφαρμοσθεί η σκανδάλη.
Το ίδιο ισχύει και για τον πίνακα inserted όπου δημιουργούνται αντίγραφα των γραμμών που εισάγονται στον πίνακα που έχει εφαρμοσθεί η σκανδάλη. Αν στην σκανδάλη υπάρχει μια εντολή UPDATE, τότε στον πίνακα deleted μπαίνουν τα δεδομένα πριν από την τροποποίηση και στον πίνακα inserted μπαίνουν δεδομένα μετά την τροποποίηση.
Ο πίνακας deleted χρησιμοποιείται αν υπάρχει η εντολή DELETE ή UPDATE μέσα στην CREATE TRIGGER. Ο πίνακας inserted χρησιμοποιείται υπάρχει η εντολή INSERT ή UPDATE μέσα στην CREATE TRIGGER.
ΠΑΡΑΔΕΙΓΜΑ 6.10
Δημιουργήστε έναν πίνακα με όνομα LOG_AUTO στον οποίο με την ενεργοποίηση μιας σκανδάλης (TRIGGER) που θα εφαρμόζεται πάνω στον βασικό πίνακα ΑΥΤΟΚΙΝΗΤΑ, θα αποθηκεύονται οι τροποποιήσεις που θα γίνονται στο πεδίο ΤΙΜΗ_ΕΝΟΙΚΙΑSIS του πίνακα ΑΥΤΟΚΙΝΗΤΑ.
CREATE TABLE LOG_AUTO(
AUTO_NUM VARCHAR(10),
USER_ID
VARCHAR(20),
HMEROMHNIA
DATETIME,
OLD
FLOAT,
NEW
FLOAT)
CREATE
TRIGGER TRIG_LOG ON AYTOKINHTA
AFTER
UPDATE AS
IF
UPDATE(TIMH_ENOIKIASIS)
BEGIN
DECLARE @TIMH_old FLOAT
DECLARE @TIMH_new
FLOAT
DECLARE @auto_number VARCHAR(10)
SELECT @TIMH_old = (SELECT TIMH_ENOIKIASIS FROM
deleted)
SELECT @TIMH_new = (SELECT TIMH_ENOIKIASIS FROM
inserted)
SELECT @auto_number = (SELECT KA FROM deleted)
INSERT INTO LOG_AUTO VALUES
(@auto_number,USER_NAME(),GETDATE(),@TIMH_old,
@TIMH_new)
END
To παράδειγμα αυτό δείχνει πώς μπορούν να χρησιμοποιηθούν οι σκανδάλες για να υλοποιήσουν ένα ημερολόγιο παρακολούθησης της κίνησης των συναλλαγών των χρηστών πάνω σε ένα πίνακα. Σε κάθε τροποποίηση της στήλης TIMH_ENOIKIASIS χρησιμοποιώντας την πρόταση UPDATE ενεργοποιείται η σκανδάλη. Έτσι, οι τιμές των γραμμών των εικονικών πινάκων deleted και inserted εκχωρούνται στις αντίστοιχες μεταβλητές @TIMH_old, @TIMH_new και @auto_number. Οι εκχωρημένες τιμές, μαζί με το όνομα χρήστη και την τρέχουσα ημερομηνία και ώρα, θα εισαχθούν κατόπιν στον πίνακα LOG_AUTO.
Αν εκτελεστεί η παρακάτω πρόταση SQL:
UPDATE AYTOKINHTA
SET
TIMH_ENOIKIASIS=200 WHERE KA=1'
Τα περιεχόμενα του πίνακα LOG_AUTO θα είναι ως εξής:
AUTO_NUM USER_ID HMEROMHNIA OLD NEW
1 dbo 2008-06-06
Κεφάλαιο 7. Συναλλαγές
Η ταυτόχρονη εκτέλεση προγραμμάτων χρηστών είναι απαραίτητη
για την καλή απόδοση ενός ΣΔΒΔ. Επειδή οι προσπελάσεις στο δίσκο είναι συχνές
και σχετικά αργές, είναι σημαντικό να κρατείται η cpu απασχολημένη με πολλά
προγράμματα χρηστών. Για το λόγο αυτό και περισσότερα ΣΔΒΔ
είναι πολυχρηστικά .
Στην εικόνα 6.1 φαίνεται ένα διαπλεγμένο μοντέλο ταυτόχρονης εκτέλεσης συναλλαγών από δύο χρήστες Α και Β

Εικόνα 7.1
Γενικά θα μπορούσαμε να πούμε ότι συναλλαγή (transaction)
είναι η εκτέλεση ενός προγράμματος που προσπελαύνει ή τροποποιεί το περιεχόμενο
της βάσης δεδομένων.
Ένα πρόγραμμα χρήστη μπορεί να εκτελεί πολλές λειτουργίες στα δεδομένα που ανακτά από τη ΒΔ, αλλά το ΣΔΒΔ ενδιαφέρεται μόνο για τα δεδομένα που διαβάζονται ή γράφονται στη ΒΔ
Οι βασικές ενέργειες που μπορεί να εκτελέσει ένας χρήστης στη διάρκεια μιας συναλλαγής είναι:
Ανάγνωση(p) - R(p)
Εγγραφήp) - W(p)
Όπού p είναι μια πλειάδα (εγγραφή) της βάσης δεδομένων.
Οι χρήστες υποβάλουν συναλλαγές και πρέπει να μπορούν να θεωρούν ότι κάθε συναλλαγή εκτελείται μόνη της.
O Ταυτοχρονισμός ή συνδρομικότητα (concurrency) αποτελεί ένα πρόβλημα που δημιουργείται στο ΣΔΒΔ όταν διαπλέκονται οι πράξεις (ανάγνωσης και εγγραφής) των διαφόρων συναλλαγών
Κάθε Συναλλαγή πρέπει να αφήνει τη ΒΔ σε μια συνεπή κατάσταση αν όταν άρχισε η Συναλλαγή η ΒΔ ήταν σε συνεπή κατάσταση.
Το ΣΔΒΔ επιβάλει κάποιους περιορισμούς ακεραιότητας με βάση τους περιορισμούς ακεραιότητας που έχουν δηλωθεί στις εντολές CREATE TABLE. Το ΣΔΒΔ καταλαβαίνει την ανάγνωση και την εγγραφή των δεδομένων και όχι τις πράξεις που γίνονται ενδιάμεσα.
7.1 Πράξεις Συναλλαγών
Εκτός από την ανάγνωση και εγγραφή που προαναφέραμε, σε μια συναλλαγή μπορούν να εκτελεστούν και οι ακόλουθες πράξεις :
BEGIN έναρξη της συναλλαγής
R(p) ανάγνωση μιας συστοιχίας p
W(p) εγγραφή μιας συστοιχίας p
END τέλος της συναλλαγής
COMMIT (επικύρωση) - επιτυχία - όλες οι τροποποιήσεις επικυρώνονται και δεν μπορούν να αναιρεθούν
ABORT ή ROLLBACK (ακύρωση ή ανάκληση) - αποτυχία -
όλες οι τροποποιήσεις πρέπει να αναιρεθούν
• Η πράξη COMMIT TRANSACTION (ή απλώς COMMIT, για συντομία) σηματοδοτεί το επιτυχές τέλος της συναλλαγής: ενημερώνει το διαχειριστή συναλλαγών ότι μια λογική μονάδα εργασίας έχει ολοκληρωθεί με επιτυχία, η βάση δεδομένων είναι (ή θα πρέπει να είναι) και πάλι σε συνεπή κατάσταση, και όλες οι ενημερώσεις που έγιναν από αυτή τη μονάδα εργασίας μπορούν τώρα να "επικυρωθούν" (commit), δηλαδή να μονιμοποιηθούν.
• Αντίθετα, η πράξη ROLLBACK TRANSACTION (ή απλώς ROLLBACK, για συντομία) σηματοδοτεί το ανεπιτυχές τέλος της συναλλαγής: ενημερώνει το διαχειριστή συναλλαγών ότι κάτι πήγε στραβά, ότι η βάση δεδομένων ίσως είναι σε ασυνεπή κατάσταση, και ότι όλες οι ενημερώσεις που έγιναν μέχρι εκείνο το σημείο από τη λογική μονάδα εργασίας πρέπει να "ανασκευαστούν" (roll back), δηλαδή να αναιρεθούν.
Μια Συναλλαγή μπορεί να να επικυρωθεί (commit) αφού ολοκληρώσει όλες τις πράξεις της ενώ μπορεί να ακυρωθεί (abort- ROLLBACK ) αφού εκτελέσει κάποιες από τις πράξεις της.
Το ΣΔΒΔ καταγράφει σε ημερολόγια (logs) όλες τις πράξεις ανάγνωσης και εγγραφής έτσι ώστε να μπορεί να αναιρέσει (undo) τις πράξεις μιας ακυρωμένης (aborted) συναλλαγής.
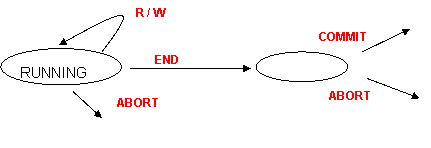
Εικόνα 6.2
Για να είναι δυνατή η ανάκαμψη από αποτυχίες, καταχωρούνται πληροφορίες για τις πράξεις των Συναλλαγών οι οποίες και αποθηκεύονται στο δίσκο στα αρχεία καταγραφής.
Τύποι πληροφορίας που αποθηκεύονται στα αρχεία καταγραφής ή log files είναι:
- έναρξη Συναλλαγής
- εγγραφή στοιχείου (παλιά, νέα τιμή)
- ανάγνωση στοιχείου
- επικύρωση/ ακύρωση
Εάν είναι γνωστά τα παραπάνω τότε είναι δυνατή η αναίρεση (undo) ή η επανάληψη (redo) μιας συναλλαγής
(Στην πραγματικότητα, τα παραπάνω είναι κάπως υπεραπλουστευμένα. Στην πράξη, το αρχείο καταγραφής ή αλλιώς βιβλίο πεπραγμένων αποτελείται από δύο μέρη, ένα ενεργό ή online μέρος και ένα αρχειακό ή offline μέρος. Το ενεργό μέρος είναι το μέρος που χρησιμοποιείται κατά την κανονική λειτουργία του συστήματος, για να καταγράφονται οι λεπτομέρειες των ενημερώσεων καθώς εκτελούνται, και συνήθως τηρείται σε δίσκο. Όταν το ενεργό μέρος γεμίσει, τα περιεχόμενα του μεταφέρονται στο αρχειακό μέρος, το οποίο - επειδή η επεξεργασία του γίνεται πάντα σειριακά - συνήθως τηρείται σε ταινίες dat.)
7.2 Οι Ιδιότητες ACID Μιας Συναλλαγής
Οοι συναλλαγές έχουν τέσσερις σημαντικές ιδιότητες — την
ατομικότητα (atomicity), τη συνέπεια (consistency), την απομόνωση (isolation),
και την ανθεκτικότητα (durability), που όλες μαζί λέγονται "ιδιότητες
ACID".
Αtomicity (ατομικότητα) -οι συναλλαγές είναι ατομικές, είτε όλες οι πράξεις είτε καμία.
Consistency (συνέπεια) - διατήρηση συνέπειας της ΒΔ. Εάν η βάση ήταν σε συνεπή κατάσταση πριν τη συναλλαγή θα παραμείνει σε συνεπή κατάσταση και μετά την συναλλαγή χωρίς να σημαίνει ότι στα ενδιάμεσα βήματα διατηρούνταν η συνέπεια της βάσης.
Isolation (απομόνωση) - δεν αποκαλύπτονται τα ενδιάμεσα αποτελέσματα. Εμφανή είναι τα αποτελέσματα αφού γίνουν οι ενημερώσεις στο τέλος. Δηλαδή μετά την επικύρωση. Πριν την επικύρωση δεν είναι ορατές οι αλλαγές.
Durability (μονιμότητα ή διάρκεια) - μετά την επικύρωση μιας συναλλαγής υπάρχει αποθήκευση των ενημερώσεων και παραμονή των δεδομένων στον δίσκο. Οι αλλαγές αυτές δεν χάνονται ακόμα και αν υπάρξει κατάρρευση του συστήματος.
Το σύστημα πρέπει να εγγυάται ότι οι μεμονωμένες εντολές είναι και οι ίδιες ατομικές (όλα ή τίποτα). Αν συμβεί ένα σφάλμα στη μέση της εκτέλεσης μιας εντολής, η βάση δεδομένων πρέπει να παραμείνει εντελώς αμετάβλητη. Ακόμα και σε περιπτώσεις αλυσιδωτής (cascade) διαγραφής ή ενημέρωσης.
7.3 Ορισμός Συναλλαγής
Μια Συναλλαγή είναι μια ακολουθία από πράξεις εγγραφής και ανάγνωσης που τελειώνει με μια πράξη επικύρωσης (commit) ή με μια πράξη ακύρωσης (abort -rollback)
Θεωρείστε τις δύο συναλλαγές του παραδείγματος:
Παράδειγμα 7.1
Υπάρχουν δύο συναλλαγές Τ1, και Τ2. Στην Τ1 γίνεται ανάγνωση μιας εγγραφής, από όπου αφαιρείται ένα ποσό Κ το οποίο στην συνέχεια προστίθεται σε μία άλλη εγγραφή που έχει αναγνωσθεί. Στην Τ2 γίνεται πρόσθεση ενός ποσού στην ίδια εγγραφή που διάβασε η συναλλαγή Τ1.
T1: BEGIN R(Χ), X=Χ-Κ, W(X), R(Y), Y=Y+Κ, W(Y), END
T2: BEGIN R(X) X=X+M, W(X) END
Οι παραπάνω συναλλαγές θα μπορούσαν πιο γενικά να γραφούν όπως παρακάτω χωρίς να χάσουν το νόημά τους.
Τ1: R(X) W(X)
R(Y) W(Y) C
T2: R(X) W(X) C
Αυτή η ακολουθία πράξεων εκφράζει μια συγκεκριμένη εκτέλεση ενός συνόλου Συναλλαγών
Οι πράξεις των Συναλλαγών εμφανίζονται σε ένα χρονοπρόγραμμα με τη σειρά που εκτελούνται.
7.4 Χρονοπρόγραμμα
Ένα χρονοπρόγραμμα (schedule) S των Συναλλαγών T1, T2, .., Tn είναι μια διάταξη των πράξεων τους με τον περιορισμό ότι για κάθε Συναλλαγή Ti που συμμετέχει στο S θα πρέπει οι πράξεις της κάθε συναλλαγής μέσα στο χρονοπρόγραμμα να εμφανίζονται με την ίδια σειρά που εμφανίζονται στην κάθε συναλλαγή Ti.
Στη συνέχεια θα χρησιμοποιούμε έναν δείκτη στις πράξεις ώστε να φαίνεται καθαρά σε ποια συναλλαγή αναφέρονται.
Έστω Τ1 και Τ2 δύο διαφορετικές συναλλαγές που η κάθε μία κάνει τις ακόλουθες πράξεις:
|
T1 |
T2 |
|
W1(X) |
|
|
W1(Y) |
|
|
R1(X) |
|
|
R1(Y) |
|
|
C1 |
|
|
|
R2(X) |
|
|
W2(X) |
|
|
C2 |
C1 και C2 είναι τα commit της κάθε συναλλαγής. Οι παραπάνω πράξεις γράφονται σε χρονοπρόγραμμα ως εξής
S: R1(X) W1(X) R1(Y) W1(Y) C1 R2(X) W2(X) C2
Υπάρχουν τόσα διαφορετικά χρονοπρογράμματα όσες και οι πιθανοί συνδυασμοί των πράξεων της κάθε συναλλαγής.
S: R1(X) R2(X) W1(X) R1(Y) W2(X) C2 W1(Y) C1
7.5 Σύγκρουση Πράξεων Σε Χρονοπρόγραμμα
Δύο πράξεις σε ένα χρονοπρόγραμμα συγκρούονται αν
(α) ανήκουν σε διαφορετικές Συναλλαγές,
(β) προσπελαύνουν το ίδιο στοιχείο, και
(γ) μια από αυτές είναι πράξη εγγραφής (W)
Σημασία έχει η σχετική θέση (διάταξη) των πράξεων που συγκρούονται
S1: R1(X) R2(X) W1(X) R1(Y) W2(X) C2 W1(Y) C1
S2: R2(X) R1(X) W1(X) R1(Y) W2(X) C2 W1(Y) C1
Τα S1 και S2 είναι ισοδύναμα γιατί διαφέρουν μόνο στη διάταξη πράξεων που δε συγκρούονται.
7.6 Πλήρες Χρονοπρόγραμμα
Αυτό που ζητάμε από ένα χρονοπρόγραμμα επίσης είναι να μην περιέχει ενεργές συναλλαγές δηλ ζητάμε οι συναλλαγές να έχουν ολοκληρωθεί. Σε αυτή την περίπτωση το ονομάζουμε πλήρες.
Ένα πλήρες χρονοπρόγραμμα (schedule) S των Συναλλαγών T1, T2, .., Tn είναι ένα σύνολο από πράξεις και μια μερική διάταξη των πράξεων αυτών με τους ακόλουθους περιορισμούς:
(i) οι πράξεις του S είναι ακριβώς οι πράξεις των T1, T2, .., Tn συμπεριλαμβανομένης μιας πράξης ακύρωσης ή επικύρωσης ως τελευταίας πράξης σε κάθε Συναλλαγή στο χρονοπρόγραμμα
(ii) για κάθε Συναλλαγή Ti που συμμετέχει στο S οι πράξεις της Ti στο S πρέπει να εμφανίζονται με την ίδια σειρά που εμφανίζονται στην Ti
(iii) Για κάθε ζεύγος συγκρουόμενων πράξεων, μια από τις δύο πρέπει να προηγείται της άλλης στο χρονοπρόγραμμα
Επικυρωμένη προβολή C(S) ενός χρονοπρογράμματος S είναι εκείνη που περιλαμβάνει μόνο τις πράξεις του S που ανήκουν σε επικυρωμένες συναλλαγές
Γενικά τα βήματα που ακολουθούνται ώστε μία συναλλαγή να είναι πλήρης είναι καταρχήν:
1. Συναλλαγή
2. Διαπεπλεγμένη εκτέλεση Συναλλαγών (χρονοπρόγραμμα)
3. Σωστό - αποδεκτό χρονοπρόγραμμα ισοδυναμεί με σειριακό χρονοπρόγραμμα
7.7 Σειριακά Χρονοπρογράμματα
Είναι τα χρονοπρογράμματα που δεν διαπλέκουν πράξεις διαφορετικών συναλλαγών. Οι πράξεις κάθε Συναλλαγής εκτελούνται διαδοχικά, χωρίς παρεμβολή πράξεων από άλλη συναλλαγή.
Παρατήρηση: Αν κάθε Συναλλαγή διατηρεί τη συνέπεια, τότε κάθε σειριακό χρονοπρόγραμμα διατηρεί τη συνέπεια.
Ένα σειριακό χρονοπρόγραμμα είναι σίγουρα σωστό
S: R1(X) W1(X) R1(Y) W1(Y) C1
R2(X) W2(X) C2
7.7.1
Ισοδύναμα
Χρονοπρογράμματα :
Για κάθε κατάσταση της ΒΔ, το αποτέλεσμα της εκτέλεσης του πρώτου χρονοπρογράμματος όταν είναι το ίδιο με το αποτέλεσμα του δεύτερου χρονοπρογράμματος τότε τα χρονοπρογράμματα τα ονομάζουμε ισοδύναμα.
Ένα χρονοπρόγραμμα ισοδύναμο με ένα σειριακό είναι σωστό.
Όταν για κάθε κατάσταση της ΒΔ, το αποτέλεσμα της εκτέλεσης του πρώτου χρονοπρογράμματος είναι το ίδιο με το αποτέλεσμα του δεύτερου χρονοπρογράμματος τότε λέμε ότι έχουμε Ισοδύναμα Χρονοπρογράμματα.
7.7.2
Σειριοποιήσιμο
Χρονοπρόγραμμα
Ένα χρονοπρόγραμμα που είναι ισοδύναμο με κάποιο σειριακό ονομάζεται σειριοποιήσιμο χρονοπρόγραμμα
7.8 Ισοδύναμα Χρονοπρογράμματα Βάσει Συγκρούσεων
Δυο χρονοπρογράμματα είναι ισοδύναμα βάσει συγκρούσεων αν η διάταξη κάθε ζεύγους συγκρουόμενων πράξεων είναι ίδια και στα δυο χρονοπρογράμματα.
Παράδειγμα 7.2
Αρχικό χρονοπρόγραμμα
S1: R1(X) R2(X) W1(X) R1(Y) W2(X) C2 W1(Y) C1
Ι
σοδύναμα βάσει συγκρούσεων
S2: R2(X) R1(X) W1(X) R1(Y) W2(X) C2 W1(Y) C1
S3: R2(X) W2(X) C2 R1(X) W1(X) R1(Y) W1(Y) C1
S4: R2(X) R1(X) W1(X) R1(Y) W1(Y) C1
W2(X) C2
7.8.1
Σειριοποιησιμότητα
βάσει Συγκρούσεων:
Ένα χρονοπρόγραμμα S είναι σειριοποιήσιμο βάσει συγκρούσεων αν είναι ισοδύναμο βάσει συγκρούσεων με κάποιο σειριακό χρονοπρόγραμμα S’.
Σε αυτήν την περίπτωση μπορούμε να αναδιατάξουμε τις μη συγκρουόμενες πράξεις στο S μέχρι να σχηματίσουμε ένα ισοδύναμο σειριακό χρονοπρόγραμμα.
S1: R1(X) R2(X) W1(X) R1(Y) W2(X) C2 W1(Y) C1
S2: R2(X) R1(X) W1(X) R1(Y) W2(X) C2 W1(Y) C1
Σειριοποιήσιμα
Sα: R1(X) W1(X) R1(Y) W1(Y) C1 R2(X) W2(X) C2
Sβ: R2(X) W2(X) C2 R1(X) W1(X) R1(Y) W1(Y) C1
7.9Ανάκαμψη
Όταν μια Συναλλαγή υποβάλλεται στο ΣΔΒΔ το σύστημα πρέπει να εξασφαλίσει ότι
(α) είτε όλες οι πράξεις της θα ολοκληρωθούν είτε
(β) καμία δε θα εκτελεστεί - δηλαδή δε θα έχει καμία επίδραση στη ΒΔ - ακόμα και αν συμβούν αποτυχίες
Αυτή είναι μια σημαντική ιδιότητα που πρέπει να εξασφαλίσει το ΣΔΒΔ. Ο χρήστης πρέπει να μπορεί να θεωρεί ότι όλο το πρόγραμμα (πράξεις) εκτελείται σε ένα βήμα είτε καμία πράξη δεν εκτελείται δηλαδή να τηρείται η ατομικότητα των συναλλαγών.
7.9.1 Είδη Αποτυχιών
Δυο είναι οι κατηγορίες αποτυχίας που συνοψίζονται στην καταστροφή ή όχι της μόνιμης αποθήκευσης των δεδομένων, δηλαδή του δίσκου.
Παραδείγματα
αποτυχιών
Αστοχίες συστήματος (διακοπή ρεύματος) οι οποίες επηρεάζουν όλες τις συναλλαγές που είναι σε εξέλιξη, αλλά δεν προκαλούν φυσική βλάβη στη βάση δεδομένων. Μια αστοχία συστήματος λέγεται μερικές φορές κατάρρευση λογισμικού (soft crash).
Αστοχίες μέσων (καταστροφή δίσκου) οι οποίες προκαλούν βλάβη στη βάση δεδομένων ή σε κάποιο μέρος της, και επηρεάζουν τουλάχιστον τις συναλλαγές που χρησιμοποιούν αυτό το μέρος της βάσης δεδομένων. Μια αστοχία μέσου λέγεται μερικές φορές κατάρρευση υλικού (hard crash).
Πώς θα ξέρει όμως το σύστημα κατά την επανεκκίνηση ποιες συναλλαγές πρέπει να αναιρέσει και ποιες να επανεκτελέσει;
7.9.2 Σημείο Έλεγχου
Η απάντηση είναι η εξής:
Σε κάποια προκαθορισμένα χρονικά διαστήματα - κατά κανόνα, όποτε έχει γραφεί ένας προκαθορισμένος αριθμός καταχωρίσεων στο αρχείο πεπραγμένων log - το σύστημα αυτόματα θέτει ένα σημείο ελέγχου (checkpoint). Η τοποθέτηση ενός σημείου ελέγχου σημαίνει
(α) φυσική καταγραφή ("καταναγκαστική καταγραφή") των περιεχομένων των περιοχών προσωρινής αποθήκευσης στη φυσική βάση δεδομένων, και
(β) φυσική καταγραφή μιας ειδικής εγγραφής σημείου ελέγχου (checkpoint record) στο αρχείο πεπραγμένων.
Η εγγραφή του σημείου ελέγχου δίνει μια λίστα όλων των συναλλαγών που ήταν σε εξέλιξη τη στιγμή που τέθηκε το σημείο ελέγχου
Εικόνα 7.3
Κατά την επανεκκίνηση λοιπόν, το σύστημα πρώτα ακολουθεί την παρακάτω διαδικασία, για να αναγνωρίσει όλες τις συναλλαγές των τύπων T2-T5:
1. Η διαδικασία ξεκινάει με δύο λίστες συναλλαγών, τη λίστα αναιρέσεων
(UNDO) και τη λίστα επανεκτελέσεων (REDO). Αρχικά, η λίστα UNDO είναι εξ
ορισμού ίση με τη λίστα όλων των συναλλαγών στην πιο πρόσφατη εγγραφή σημείου
ελέγχου' η λίστα REDO είναι εξ ορισμού κενή.
2. Γίνεται αναζήτηση προς τα εμπρός μέσα στο αρχείο πεπραγμένων, ξεκινώντας από την εγγραφή του σημείου ελέγχου.
3. Αν βρεθεί στο log μια καταχώριση BEGIN TRANSACTION για τη συναλλαγή Τ, προστίθεται η T στη λίστα UNDO.
4. Αν βρεθεί στο αρχείο πεπραγμένων μια καταχώριση COMMIT για τη συναλλαγή Τ, μεταφέρεται η Τ από τη λίστα UNDO στη λίστα REDO.
5. Όταν η αναζήτηση φτάσει στο τέλος του αρχείου πεπραγμένων, οι λίστες UNDO και REDO προσδιορίζουν, αντίστοιχα, τις συναλλαγές των τύπων Τ3 και T5 και τις συναλλαγές των τύπων T2 και Τ4.
Για την ανάκαμψη από μια τέτοια αστοχία, απαιτείται να γίνει επαναφόρτωση (ή επαναφορά - restore) της βάσης δεδομένων από ένα εφεδρικό αντίγραφο (database backup)
Έπειτα να χρησιμοποιηθεί το αρχείο πεπραγμένων - τόσο το ενεργό όσο και το αρχειακό μέρος του, για να επανεκτελεστούν όλες οι συναλλαγές που ολοκληρώθηκαν μετά από τη στιγμή που πάρθηκε το εφεδρικό αντίγραφο.
Οι συναλλαγές που ήταν ακόμα σε εξέλιξη τη στιγμή της αστοχίας, έχουν "αναιρεθεί" (για την ακρίβεια, έχουν χαθεί), έτσι και αλλιώς.
Προκύπτει λοιπόν η ανάγκη να έχουμε ένα βοηθητικό πρόγραμμα
αποτύπωσης/επαναφοράς (dump/restore),
ή εκφόρτωσης/ επαναφόρτωσης (unload/reload) εφεδρικών αντιγράφων.
Το μέρος αυτού του βοηθητικού προγράμματος που ασχολείται με την αποτύπωση (dump) χρησιμοποιείται για τη δημιουργία εφεδρικών αντιγράφων της βάσης δεδομένων(μπορεί να τηρούνται σε ταινία ή σε κάποιο άλλο αρχειακό μέσο αποθήκευσης' δεν είναι απαραίτητο να βρίσκονται σε ένα μέσο άμεσης προσπέλασης.)
Μετά από μια αστοχία μέσου, το μέρος του βοηθητικού προγράμματος που ασχολείται με την επαναφορά (restore) χρησιμοποιείται για να ξαναδημιουργηθεί η βάση δεδομένων από ένα καθορισμένο εφεδρικό αντίγραφο.
7.9.3 Επικύρωση Δυο Φάσεων
Η επικύρωση ή αλλιώς ανασκευή της βάσης σε περίπτωση αστοχίας συστήματος ή μέσου, ονομάζεται επικύρωση δύο φάσεων (two-phase commit). Η επικύρωση δύο φάσεων είναι σημαντική όταν μια δεδομένη συναλλαγή μπορεί να αλληλεπιδρά με πολλούς ανεξάρτητους "διαχειριστές πόρων", που ο καθένας διαχειρίζεται το δικό του σύνολο ανακάμψιμων πόρων (recoverable resources) και συντηρεί το δικό του αρχείο πεπραγμένων για την ανάκαμψη
Στην πρώτη φάση γίνεται καταναγκαστική καταγραφή όλων των καταχωρίσεων πεπραγμένων της συναλλαγής σε μόνιμο μέσο αποθήκευσης.
Ότι και αν συμβεί μετά, ο διαχειριστής πόρων θα έχει μια μόνιμη εγγραφή της εργασίας που έκανε για λογαριασμό της συναλλαγής, και έτσι θα μπορεί να επικυρώσει τις ενημερώσεις της ή να τις ανασκευάσει, ανάλογα με την περίπτωση
Στην δεύτερη φάση γίνετε η επικύρωση ή ανασκευή τη συναλλαγής τοπικά, ανάλογα με την τελική υπόδειξη (commit, abort)
7.9.4 Υποστήριξη Από Την SQL
·Η SQL υποστηρίζει τις συνηθισμένες εντολές COMMIT και ROLLBACK που αφορούν τις συναλλαγές και, επομένως, και την ανάκαμψη με βάση τις συναλλαγές. Ισχύουν τα εξής:
Σειριοποιήσιμο είναι ένα χρονοπρόγραμμα εξορισμού
Επαναλαμβανόμενη ανάγνωση – μόνο οι επικυρωμένες εγγραφές μπορούν να διαβαστούν, οι επαναλαμβανόμενες εγγραφές της ίδιας εγγραφής πρέπει να επιστρέψουν την ίδια τιμή. Ωστόσο, μια δοσοληψία ίσως να μην είναι σειριοποιήσιμη – μπορεί να βρει μερικές εγγραφές που έχουν εισαχθεί από την δοσοληψία, αλλά ίσως να μην τις βρει όλες.
Επικύρωση ανάγνωσης – μόνο εγγραφές που έχουν επικυρωθεί μπορούν να αναγνωστούν, αλλά διαδοχικές αναγνώσεις μιας εγγραφής μπορεί να επιστρέψει διαφορετικά (αλλά επικυρωμένες) τιμές
Ακύρωση ανάγνωσης – ακόμη και οι εγγραφές που δεν έχουν επικυρωθεί μπορούν να αναγνωστούν.
Μια διαφορά μεταξύ της υποστήριξης των συναλλαγών από την SQL και των γενικών εννοιών που σκιαγραφήσαμε είναι ότι η SQL δε διαθέτει ρητή εντολή έναρξης συναλλαγής BEGIN TRANSACTION. Αντίθετα, η έναρξη μιας συναλλαγής υπονοείται, κάθε φορά που το πρόγραμμα εκτελεί μια εντολή "έναρξης συναλλαγής" και δεν είναι ήδη σε εξέλιξη μια συναλλαγή. Οι λεπτομέρειες για το ποιες ακριβώς εντολές της SQL είναι εντολές "έναρξης συναλλαγής" δεν έχουν θέση εδώ, θα αρκεστούμε να πούμε ότι όλες οι εντολές ορισμού δεδομένων και χειρισμού δεδομένων που εξετάστηκαν στο κεφάλαιο της SQL είναι εντολές έναρξης συναλλαγής. Μια ειδική εντολή που ονομάζεται SET TRANSACTION χρησιμοποιείται για να ορίσει κάποια χαρακτηριστικά της νέας συναλλαγής που θα ξεκινήσει (η SET TRANSACTION μπορεί να εκτελεστεί μόνο όταν καμία συναλλαγή δεν είναι σε εξέλιξη, και η ίδια δεν είναι εντολή έναρξης συναλλαγής). Τα μόνα από αυτά τα χαρακτηριστικά που θα εξετάσουμε εδώ είναι ο τρόπος προσπέλασης και το επίπεδο απομόνωσης.
Η σύνταξη της εντολής είναι:
SET TRANSACTION λίστα-επιλόγων ;
όπου η λίστα-επιλογών πρέπει να περιέχει τουλάχιστον μία επιλογή.
• Η επιλογή για τον τρόπο προσπέλασης (access mode) μπορεί να είναι είτε READ ONLY (μόνο ανάγνωση) είτε READ WRITE (ανάγνωση και εγγραφή). Αν δεν καθοριστεί κανένα από τα δύο, ο τρόπος προσπέλασης θεωρείται READ WRITE, εκτός αν έχει καθοριστεί επίπεδο απομόνωσης READ UNCOMMITTED (ανάγνωση ανεπικύρωτων), οπότε ο τρόπος προσπέλασης θεωρείται ότι είναι READ ONLY. Αν καθοριστεί τρόπος προσπέλασης READ WRITE, το επίπεδο απομόνωσης δεν πρέπει να είναι READ UNCOMMITTED.
Η επιλογή για το επίπεδο απομόνωσης (isolation level) έχει τη μορφή ISOLATION LEVEL απομόνωση, όπου απομόνωση μπορεί να είναι μία από τις φράσεις READ UNCOMMITTED (ανάγνωση ανεπικύρωτων), READ COMMITTED (ανάγνωση επικυρωμένων), REPEATABLE READ (επαναλήψιμη ανάγνωση), ή SERIALIZABLE (σειροποιήσιμο).
8. Ταυτοχρονισμός
Τα θέματα του ταυτοχρονισμού και της ανάκαμψης πηγαίνουν μαζί, καθώς είναι και τα δύο μέρη του γενικότερου θέματος της επεξεργασίας συναλλαγών. Θα στρέψουμε τώρα την προσοχή μας ειδικά στον ταυτοχρονισμό και ειδικότερα στα προβλήματα που προκύπτουν. Ο όρος ταυτοχρονισμός ή συνδρομικότητα (concurrency) αναφέρεται στο γεγονός ότι τα DBMS κατά κανόνα επιτρέπουν σε πολλές συναλλαγές να προσπελάζουν τα ίδια δεδομένα την ίδια στιγμή - και σε ένα τέτοιο σύστημα, όπως είναι γνωστό, χρειάζεται ένας μηχανισμός ελέγχου ταυτοχρονισμού κάποιου είδους, για να εξασφαλίζει ότι οι ταυτόχρονες συναλλαγές δε θα παρεμβάλλονται η μία στη λειτουργία της άλλης.
Επιτρέπεται σε πολλαπλές συναλλάγές να εκτελούνται ταυτόχρονα στο σύστημα. Τα πλεονεκτήματα είναι:
·αυξημένη χρήση του επεξεργαστή και του δίσκου, οδηγεί σε καλύτερη συνολική απόδοση του συστήματος: μια δοσοληψία μπορεί να χρησιμοποιήσει την Κ.Μ.Ε την ώρα που κάποια άλλη δοσοληψία διαβάζει ή γράφει στοιχεία στο δίσκο.
·μειωμένος συνολικός μέσος χρόνος απόκρισης για τις δοσοληψίες: οι μικρές δοσοληψίες δεν χρειάζεται να περιμένουν τις δοσοληψίες που αργούν να τελειώσουν.
Θεωρείστε τις δύο συναλλαγές του παραδείγματος 6.1
T1: BEGIN
R(X), X=Χ-Κ,
W(X), R(Y), Y=Y+Κ,
W(Y), END
T2: BEGIN
R(X) X=X+M, W(X) END
Διαισθητικά, η T1 μεταφέρει Κ ποσό χρημάτων από έναν λογαριασμό (Χ) σε έναν άλλο λογαρισμό (Y). Η T2 προθέτει Μ ποσό χρημάτων στον πρώτο λογαριασμό.(Χ )

Δεν υπάρχει καμία εγγύηση ότι η T1 θα εκτελεστεί πριν την T2 η το ανάποδο, αν και
η δύο υποβληθούν ταυτόχρονα. Ωστόσο, το συνολικό αποτέλεσμα πρέπει να είναι
ισοδύναμο με τη μία ή την άλλη περίπτωση (δηλαδή, με κάποια σειριακή εκτέλεση
των δύο Συναλλαγών)

Σε περίπτωση όμως που δεν εκτελεστούν σειριακά οι συναλλαγές θα προκύψει πρόβλημα
όπως φαίνεται.
Τα προβλήματα που προκύπτουν από την ταυτόχρονη εκτέλεση συναλλαγών είναι τρία :
1. Το πρόβλημα της χαμένης ενημέρωσης (lost update)
2. Το πρόβλημα της εξάρτησης από ανεπικύρωτη μεταβολή (uncommitted dependency)
3. Το πρόβλημα της ασυνεπούς ανάλυσης (inconsistent analysis)
τα οποί και θα εξηγήσουμε παρακάτω.
8.1 Χαμένη Ενημέρωση
Στην περίπτωση αυτή όπως φαίνεται από το παρακάτω σχήμα (Εικόνα 8.1) η συναλλαγή Α την χρονική στιγμή t1 κάνει ανάγνωση μιας συστοιχίας Χ, η συναλλαγή Β την χρονική στιγμή t2 κάνει ανάγνωση της ίδιας συστοιχίας Χ, η συναλλαγή Α την χρονική στιγμή t3 κάνει ενημέρωση της συστοιχίας Χ, η συναλλαγή Β την χρονική στιγμή t4 κάνει ενημέρωση της ίδιας συστοιχίας Χ. Η ενημέρωση της συναλλαγής Α χάνεται τη χρονική στιγμή t4, επειδή η συναλλαγή Β την αντικαθιστά χωρίς ούτε καν να την κοιτάξει.
Α Β
-----------------------------------------------------------
R(X) t1 -
- t2 R(X)
W(X) t3 -
- t4 W(X)
Εικόνα 8.1
8.2 Εξάρτηση Από Ανεπικύρωτη Μεταβολή
Στην περίπτωση αυτή όπως φαίνεται από το παρακάτω σχήμα
(Εικόνα 8.2) η συναλλαγή Β την χρονική στιγμή t1 κάνει ενημέρωση μιας συστοιχίας Χ, η συναλλαγή Α την
χρονική στιγμή t2 κάνει
ανάγνωση της ίδιας
συστοιχίας Χ, η συναλλαγή Α την χρονική στιγμή t3 κάνει ενημέρωση της συστοιχίας Χ, η
συναλλαγή Β την χρονική στιγμή t4 κάνει ακύρωση της ενημέρωσης της συστοιχίας Χ. Οπότε η πρώτη συναλλαγή θα έχει
δει κάποια δεδομένα που τώρα δεν υπάρχουν πια (και κατά μία έννοια,
"ποτέ" δεν υπήρξαν).
Α Β
--------------------------------------------------------
t1
W(X)
R(X) t2 -
W(X) t3
- t4 ABORT
Εικόνα 8.2
Η συναλλαγή Α λειτουργεί λοιπόν με μια εσφαλμένη παραδοχή, συγκεκριμένα, την παραδοχή ότι η συστοιχία X έχει την τιμή που είδε τη στιγμή t2, ενώ στην πραγματικότητα έχει την όποια τιμή απέκτησε πριν από τη στιγμή t1. Ως αποτέλεσμα, η συναλλαγή Α μπορεί να δώσει λανθασμένο αποτέλεσμα. Σημειώστε, με την ευκαιρία, ότι η ανασκευή (ABORT ή ROLLBACK) της συναλλαγής Β μπορεί να μην οφείλεται σε σφάλμα της Β, μπορεί, για παράδειγμα, να οφείλεται σε μια κατάρρευση συστήματος. (Επίσης, η συναλλαγή Α μπορεί να έχει ήδη τερματιστεί εκείνη τη στιγμή, οπότε η κατάρρευση δε θα προκαλούσε ανασκευή και για την Α.)
8.3 Ασυνεπής Ανάλυση
Ας εξετάσουμε την Εικόνα 8.3, που δείχνει δύο συναλλαγές, τις Α και Β, οι οποίες επενεργούν σε συστοιχίες λογαριασμών (RecA): Η συναλλαγή Α αθροίζει υπόλοιπα λογαριασμών, και η συναλλαγή Β μεταφέρει ένα ποσό 10 από το λογαριασμό RecA 3 στο λογαριασμό RecA 1.
Το αποτέλεσμα που παράγεται από την Α, το ποσό 410, είναι προφανώς λανθασμένο. Aν η Α προχωρούσε στην καταγραφή αυτού του αποτελέσματος στη βάση δεδομένων, η πράξη αυτή θα άφηνε τη βάση δεδομένων σε ασυνεπή κατάσταση. Λέμε ότι η Α είδε μια ασυνεπή κατάσταση της βάσης δεδομένων και γι' αυτό πραγματοποίησε μια ασυνεπή ανάλυση. Προσέξτε τη διαφορά ανάμεσα σε αυτό το παράδειγμα και το προηγούμενο: εδώ, δεν υπάρχει ζήτημα εξάρτησης της Α από μια ανεπικύρωτη μεταβολή, αφού η Β επικυρώνει (COMMIT) όλες τις ενημερώσεις της πριν δει η Α το λογαριασμό RecA 3.
[RecA 1=140, RecA2=150, RecA3 =130]
Α Β
--------------------------------------------------------------
R(X) RecA1
sum=40 t1 -
R(X) RecA2
sum=290 t2 -
- t3 R(X) RecA3
- t4 W(X) RecA3 130à120
- t5 R(X) RecA1
- t6 R(X) RecA1 140à150
- t7 COMMIT
R(X) RecA3 t8 -
sum=410 και όχι 420
Εικόνα 8.3
8.4 Τεχνική Έλεγχου Κλείδωμα (locking)
Μία από τις βασικές τεχνικές που χρησιμοποιούνται για τον έλεγχο ταυτόχρονης εκτέλεσης δοσοληψιών βασίζεται στην έννοια του κλειδώματος δεδομένων.
Το αποτέλεσμα του κλειδώματος είναι να αποκλειστούν οι άλλες συναλλαγές από την συστοιχία, και έτσι να μην μπορούν να την μεταβάλουν. Η πρώτη συναλλαγή έχει έτσι τη δυνατότητα να πραγματοποιήσει την επεξεργασία της, γνωρίζοντας με βεβαιότητα ότι το δεδομένο αντικείμενο θα παραμείνει σε σταθερή κατάσταση για όσο χρόνο επιθυμεί η συναλλαγή.
Διάφοροι τύποι κλειδωμάτων χρησιμοποιούνται στον έλεγχο του ταυτοχρονισμού. Πρώτον υπάρχουν τα δυαδικά κλειδώματα τα οποία είναι απλά, αλλά κατά κάποιον τρόπο περιοριστικά στη χρήση τους. Υπάρχουν και τα διαμοιραζόμενα και τα αποκλειστικά κλειδώματα, τα οποία παρέχουν πιο γενικευμένες δυνατότητες κλειδώματος.
1. Πρώτον, δεχόμαστε ότι το σύστημα υποστηρίζει δύο είδη κλειδωμάτων, τα αποκλειστικά (exclusive locks) ή κλειδώματα Χ, και τα μεριζόμενα (shared locks) ή κλειδώματα S. Σημείωση: Τα κλειδώματα Χ και S ονομάζονται μερικές φορές κλείδωμα πράξων εγγραφής (write lock) και κλείδωμα πράξεων ανάγνωσης (read lock), αντίστοιχα. Θα θεωρήσουμε προς το παρόν ότι τα κλειδώματα Χ και S είναι τα μόνα είδη που υπάρχουν. Θα θεωρήσουμε επίσης ότι η συστοιχία είναι το μόνο είδος αντικειμένου που επιδέχεται κλείδωμα.
2. Αν η συναλλαγή Α κατέχει ένα αποκλειστικό (Χ) κλείδωμα πάνω στη συστοιχία ρ, τότε μια αίτηση από κάποια άλλη συναλλαγή Β για ένα κλείδωμα οποιουδήποτε από τους δύο τύπους στην ρ θα απορριφθεί.
3. Αν η συναλλαγή Α κατέχει ένα μεριζόμενο (S) κλείδωμα πάνω στη συστοιχία ρ, τότε:
• Μια αίτηση από κάποια άλλη συναλλαγή Β για ένα κλείδωμα Χ στην ρ θα απορριφθεί.
• Μια αίτηση από κάποια άλλη συναλλαγή Β για ένα κλείδωμα S στην ρ θα γίνει δεκτή (δηλαδή, και η Β θα διατηρεί τώρα ένα κλείδωμα S στην ρ).
8.4.1 Μητρώο Συμβατότητας (Compatibility Matrix)
Οι κανόνες αυτοί είναι βολικό να συνοψιστούν σε ένα μητρώο συμβατότητας (compatibility matrix - Εικόνα 8.4). Το μητρώο αυτό ερμηνεύεται με τον εξής τρόπο: Έστω μια συστοιχία ρ έστω ότι η συναλλαγή Α κατέχει αυτή τη στιγμή ένα κλείδωμα στην ρ, όπως δείχνουν οι καταχωρίσεις στις επικεφαλίδες των στηλών (παύλα = χωρίς κλείδωμα)', και έστω ότι κάποια άλλη συναλλαγή Β υποβάλλει αίτηση για ένα κλείδωμα στην ρ, όπως δείχνουν οι καταχωρίσεις στην αριστερή πλευρά (για πληρότητα, συμπεριλάβαμε πάλι την περίπτωση "χωρίς κλείδωμα").
|
|
X |
S |
- |
|
X |
O |
O |
N |
|
S |
O |
N |
N |
|
- |
N |
N |
N |
Εικόνα 8.4
Το "Ο" (όχι) σημαίνει σύγκρουση (conflict δηλαδή η αίτηση της Β δεν μπορεί να ικανοποιηθεί και η Β περνάει σε κατάσταση αναμονής), ενώ το "Ν" (ναι) σημαίνει συμβατότητα (η αίτηση της Β ικανοποιείται). Το μητρώο είναι προφανώς συμμετρικό.
8.4.2 Πρωτόκολλο Προσπέλασης Δεδομένων (data access protocol)
Μια συναλλαγή που θέλει να ανακαλέσει μια συστοιχία πρέπει πρώτα να αποκτήσει ένα κλείδωμα S σε αυτή τη συστοιχία.
Μια συναλλαγή που θέλει να ενημερώσει μια συστοιχία πρέπει πρώτα να αποκτήσει ένα κλείδωμα Χ σε αυτή τη συστοιχία. Αν κατέχει ήδη ένα κλείδωμα S στη συστοιχία, όπως συμβαίνει σε μια ακολουθία ανάγνωσης και ενημέρωσης (Read-Write), τότε θα πρέπει να προαγάγει το κλείδωμα S σε κλείδωμα επιπέδου Χ.
Αν μια αίτηση κλειδώματος από τη συναλλαγή Β απορριφθεί επειδή έρχεται σε σύγκρουση με ένα κλείδωμα που κατέχει ήδη η συναλλαγή Α, τότε η συναλλαγή Β περνάει σε κατάσταση αναμονής.
Τα κλειδώματα Χ διατηρούνται μέχρι το τέλος της συναλλαγής (COMMIT ή ABORT).
8.5 Αδιέξοδο (DEADLOCK)
Το αδιέξοδο είναι μια κατάσταση όπου δύο ή περισσότερες συναλλαγές είναι ταυτόχρονα σε κατάσταση αναμονής, και η κάθε μία περιμένει μια από τις άλλες να απελευθερώσει ένα κλείδωμα, πριν μπορέσει να προχωρήσει.
Επιστροφή στα τρία προβλήματα ταυτοχρονισμού
8.5.1
Το πρόβλημα της χαμένης ενημέρωσης με κλειδώματα
Α Β
---------------------------------------------------------------
R(p) S t1 -
- t2 R(p) S
W(p) X t3 -
αναμονή t4 W(p) X
αναμονή αναμονή
Εικόνα 8.5
Η πράξη ενημέρωσης της συναλλαγής Α τη χρονική στιγμή t3 δε γίνεται δεκτή, γιατί είναι έμμεση αίτηση για ένα κλείδωμα Χ στην p, και μια τέτοια αίτηση έρχεται σε σύγκρουση με το κλείδωμα S που ήδη κατέχει η συναλλαγή Β, έτσι, η Α περνάει σε κατάσταση αναμονής. Για ανάλογους λόγους, η Β περνάει σε κατάσταση αναμονής τη χρονική στιγμή t4. Τώρα, και οι δύο συναλλαγές δεν μπορούν να προχωρήσουν, και έτσι δεν υπάρχει ζήτημα απώλειας κάποιας ενημέρωσης. Έτσι, το κλείδωμα λύνει το πρόβλημα της χαμένης ενημέρωσης, ανάγοντας το σε ένα άλλο πρόβλημα! Όμως τουλάχιστον λύνει το αρχικό πρόβλημα. Το νέο πρόβλημα ονομάζεται αδιέξοδο (deadlock).
8.5.2
Το πρόβλημα Εξάρτησης από Ανεπικύρωτη Μεταβολή με κλειδώματα
Α Β
--------------------------------------------------------------------
t1 W(p) X
R(p) t2 -
ΑΝΑΜΟΝΗ
ΑΝΑΜΟΝΗ t3 Abort/ Commit
Συνέχεια R( p) S t4
Εικόνα 8.6
Η πράξη που εκτελεί η συναλλαγή Α τη χρονική στιγμή t2 δε γίνεται δεκτή, επειδή είναι υπονοούμενη αίτηση για ένα κλείδωμα στην p, και μια τέτοια αίτηση έρχεται σε σύγκρουση με το κλείδωμα Χ που ήδη κατέχει η συναλλαγή Β, έτσι, η Α περνάει σε κατάσταση αναμονής.
Παραμένει σε αυτή την κατάσταση αναμονής μέχρι να φτάσει η Β στον τερματισμό της (είτε με COMMIT είτε με ABORT), οπότε το κλείδωμα της Β απελευθερώνεται και η Α μπορεί να προχωρήσει.
Σε εκείνο το σημείο, η Α βλέπει μια επικυρωμένη τιμή (είτε την τιμή πριν από την Β, αν η Β τερματίστηκε με ABORT, είτε την τιμή μετά από την Β, στην αντίθετη περίπτωση). Και στις δύο περιπτώσεις, η Α δεν είναι πια εξαρτημένη από την ανεπικύρωτη ενημέρωση. Δηλαδή το πρόβλημα αυτό λύθηκε τελείως με την χρήση κλειδωμάτων ανάγνωσης και εγγραφής.
8.5.3
Το πρόβλημα Ασυνεπούς Ανάλυσης με κλειδώματα
Εφαρμόζοντας κλειδώματα εγγραφής και ανάγνωσης στο πρόβλημα της ασυνεπούς ανάλυσης φαίνεται ότι λύνεται το πρόβλημα άλλα δημιουργείται ένα νέο πρόβλημα
Η πράξη Write(p) της συναλλαγής Β τη χρονική στιγμή t6 δε γίνεται δεκτή, επειδή είναι υπονοούμενη αίτηση για ένα κλείδωμα Χ στο λογαριασμό RecA1, και μια τέτοια αίτηση έρχεται σε σύγκρουση με το κλείδωμα S που ήδη κατέχει η Α. Έτσι, η Β περνάει σε κατάσταση αναμονής
[RecA 1=140, RecA2=150, RecA3 =130]
Α Β
-------------------------------------------------------------------------------------------------
R(p) RecA1 S
sum=40 t1 -
R(p) RecA2
S sum=290 t2 -
- t3 R(p) RecA3 S
- t4 W(p) RecA3 X 130à120
- t5 R(p) RecA1 S
- t6 W(p) RecA1 140à150
R(p) RecA3 t7 Αναμονή
Αναμονή t8 Αναμονή
Εικόνα 8.7
. Αντίστοιχα, η Write(p) της συναλλαγής Α τη χρονική στιγμή t7 επίσης δε γίνεται αποδεκτή, επειδή είναι υπονοούμενη αίτηση για ένα κλείδωμα S στο λογαριασμό RecA 3, και μια τέτοια αίτηση έρχεται σε σύγκρουση με το κλείδωμα Χ που ήδη κατέχει η Β. Έτσι, η Α περνάει και αυτή σε κατάσταση αναμονής. Και πάλι λοιπόν, το κλείδωμα λύνει το αρχικό πρόβλημα (το πρόβλημα της ασυνεπούς ανάλυσης, σε αυτή την περίπτωση) προκαλώντας ένα αδιέξοδο.
8.5.4 Γενικό Παράδειγμα Αδιεξόδου
Η παρακάτω Εικόνα 8 δείχνει ένα αδιέξοδο όπου εμπλέκονται δύο συναλλαγές, αλλά είναι δυνατό να υπάρξουν και αδιέξοδα όπου εμπλέκονται τρεις, τέσσερις, ή περισσότερες συναλλαγές, τουλάχιστον στη θεωρία. Στην πράξη σχεδόν ποτέ δεν εμπλέκονται στα αδιέξοδα περισσότερες από δύο συναλλαγές.
Α Β
---------------------------------------------------------------
Lock p1 X t1 -
- t2 Lock p2 X
Lock p2 X t3 -
αναμονή t4 Lock p1 X
αναμονή αναμονή
Εικόνα 8.8
Αν συμβεί ένα αδιέξοδο, είναι επιθυμητό το σύστημα να το εντοπίσει και να το σπάσει.
Σπάσιμο του αδιεξόδου σημαίνει να διαλέξουμε για θύμα (victim) μία από τις συναλλαγές που βρίσκονται σε αδιέξοδο και να την ανασκευάσουμε, απελευθερώνοντας έτσι τα κλειδώματα της και επιτρέποντας να προχωρήσει κάποια άλλη συναλλαγή.
Παρατηρήστε, με την ευκαιρία, ότι η συναλλαγή-θύμα έχει
"αποτύχει" και έχει ανασκευαστεί χωρίς να φταίει η ίδια. Μερικά
συστήματα ξανά ξεκινούν αυτόματα από την αρχή μια τέτοια συναλλαγή, θεωρώντας
ότι οι συνθήκες που προκάλεσαν το αδιέξοδο την πρώτη φορά δε θα επαναληφθούν.
Άλλα συστήματα απλώς επιστρέφουν έναν κωδικό "θύματος αδιεξόδου" πίσω
στην εφαρμογή' είναι τότε δουλειά του προγράμματος να αντιμετωπίσει την
κατάσταση με κάποιον κατάλληλο τρόπο.
8.5.5 Χρονοσήμο Δοσοληψίας
Οι τεχνικές αυτές χρησιμοποιούν τη έννοια του χρονοσήμου
δοσοληψίας TS(T), το οποίο είναι μια μοναδική
ταυτότητα που ανατίθεται σε κάθε δοσοληψία. Τα χρονόσημα διατάσσονται με
βάση την σειρά που εκκινήθησαν οι δοσοληψίες, συνεπώς αν η δοσοληψία Τ1
εκκινείτε πριν από την δοσοληψία Τ2, τότε TS(T1)<TS(T2). Σημειώνουμε ότι η
παλαιότερη δοσοληψία έχει το μικρότερο χρονόσημο. Δύο σχήματα πρόληψης
αδιεξόδου ονομάζονται σχήματα αναμονής –θανάτωσης (wait-die) και σχήμα
τραυματισμού- αναμονής (wound-wait). Υποθέστε ότι η δοσοληψία Ti προσπαθεί να
κλειδώσει ένα στοιχείο Χ αλλά δεν
μπορεί, διότι το Χ είναι κλειδωμένο από κάποια δοσοληψία Τj με κλείδωμα που δεν
είναι συμβατό με το αιτούμενο. Οι
κανόνες που ακολουθούνται από αυτά τα σχήματα έχουν ως ακολούθως :
·
Αναμονή-θανάτωση: αν TS(Ti)<TS(Tj) (η Τi είναι
παλαιότερη από την Τj) τότε η Τi μπορεί να περιμένει. Διαφορετικά η Τi ακυρώνεται και επανεκκινείται αργότερα με το
ίδιο χρονόσημο
·
Τραυματισμός-αναμονή: αν TS(T1)<TS(T2)( Τi είναι
παλαιότερη από την Τj). Τότε ακυρώνεται η Τj (η Τi τραυματίζει την Tj) και
επανεκκινείται αργότερα με το ίδιο χρονόσημο. Διαφορετικά η Ti μπορεί να
περιμένει
8.5.6 Επιφυλακτική αναμονή
Mία άλλη ομάδα πρωτοκόλλων που προλαμβάνουν τα αδιέξοδα δεν
απαιτεί χρονόσημα. Αυτά τα πρωτόκολλα περιλαμβάνουν τους αλγόριθμους άνευ αναμονής (no waiting
(NW)) και επιφυλακτικής αναμονής (cautious waiting (CW)). Στον αλγόριθμο άνευ
αναμονής, αν μια δοσοληψία δεν μπορεί να κλειδώσει ένα στοιχείο
ακυρώνεται αμέσως και επανεκκινήται μετά από κάποιο χρονικό διάστημα, χωρίς να ελεγχθεί αν στην πραγματικότητα θα προκύψει ή όχι αδιέξοδο.
Οι κανόνες της επιφυλακτικής αναμονής έχουν ως ακολούθως
·
Αν η Tj δεν έχει ανασταλεί (δεν περιμένει για κάποιο
άλλο κλειδωμένο στοιχείο).
·
Τότε η Ti αναστέλλεται και της επιτρέπεται να
περιμένει.
·
Διαφορετικά η Ti ακυρώνεται.
Στην πράξη, δεν εντοπίζουν όλα τα συστήματα τα αδιέξοδα — μερικά χρησιμοποιούν απλώς ένα μηχανισμό χρονικού ορίου (timeout) και θεωρούν ότι μια συναλλαγή που δεν έχει κάνει καμία δουλειά για ένα προκαθορισμένο χρονικό διάστημα είναι σε αδιέξοδο.
8.6 Πρωτόκολλο Κλειδώματος Δυο Φάσεων
Πριν επενεργήσει σε οποιοδήποτε αντικείμενο (π.χ., σε μια συστοιχία βάσης δεδομένων), μια συναλλαγή πρέπει να αποκτήσει ένα κλείδωμα σε αυτό το αντικείμενο.
Αφού απελευθερώσει ένα κλείδωμα, μια συναλλαγή δεν πρέπει ποτέ να προχωρήσει στην απόκτηση και άλλων κλειδωμάτων.
Μια συναλλαγή που υπακούει σε αυτό το πρωτόκολλο έχει λοιπόν δύο φάσεις, μια φάση απόκτησης κλειδώματος και μια φάση απελευθέρωσης κλειδώματος
Ένα πρωτόκολλο πρόληψης αδιεξόδων, το οποίο χρησιμοποιείται στο συντηρητικό κλείδωμα δύο φάσεων, ορίζει ότι κάθε δοσοληψία πρέπει να κλειδώνει τα στοιχεία που χρειάζεται, πριν ξεκινήσει. Αν κάποιο στοιχείο δεν μπορεί να κλειδωθεί, κανένα δεν κλειδώνεται.
8.7 Προτιθέμενο κλείδωμα
Αναφέραμε ήδη ότι τα κλειδώματα Χ και S έχουν νόημα και για ολόκληρες σχέσεις και για μεμονωμένες συστοιχίες.
Εισάγουμε τρία νέα είδη κλειδωμάτων, που ονομάζονται προτιθέμενα κλειδώματα (intent locks), τα οποία έχουν επίσης νόημα για τις σχέσεις αλλά όχι για τις μεμονωμένες συστοιχίες.
προτιθέμενο μεριζόμενο κλείδωμα (intent shared — IS),
προτιθέμενο αποκλειστικό κλείδωμα (intent exclusive — IX)
μεριζόμενο και προτιθέμενο αποκλειστικό κλείδωμα (shared intent exclusive — SIX).
IS :Η συναλλαγή Τ σκοπεύει να θέσει κλειδώματα S σε μεμονωμένες συστοιχίες της R, για να εξασφαλιστεί η σταθερότητα αυτών των συστοιχιών ενώ γίνεται η επεξεργασία τους.
IX :Το ίδιο με το IS, και επιπλέον η Τ μπορεί να χρειαστεί να ενημερώνει μεμονωμένες συστοιχίες της R, γι' αυτό θέτει κλειδώματα Χ σε αυτές τις συστοιχίες.
S :Η T ανέχεται ταυτόχρονες αναγνώσεις, αλλά όχι ταυτόχρονες ενημερώσεις της R. Η ίδια η T δεν ενημερώνει συστοιχίες της R.
SIX :Συνδυάζει τα S και IX, δηλαδή, η T ανέχεται ταυτόχρονες αναγνώσεις, αλλά όχι ταυτόχρονες ενημερώσεις της R, και επιπλέον η T μπορεί να χρειαστεί να ενημερώνει μεμονωμένες συστοιχίες της R, γι' αυτό θέτει κλειδώματα Χ σε αυτές τις συστοιχίες.
Χ :Η Τ δεν ανέχεται καμία απολύτως ταυτόχρονη προσπέλαση της R, η ίδια η T μπορεί να ενημερώνει ή να μην ενημερώνει μεμονωμένες συστοιχίες της R.
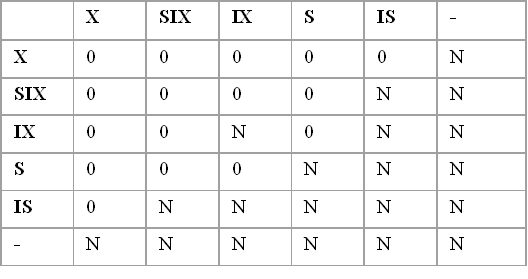
Στην Εικόνα 8.9 φαίνεται το μητρώο συμβατότητας, διευρυμένο ώστε να
περιλαμβάνει τα προτιθέμενα κλειδώματα. (Ν=Ναι, Ο=Όχι).
Εικόνα 8.9 Διευρυμένο μητρώο συμβατότητας.
Κεφάλαιο 9. Ασφάλεια
9.1 ασφαλεια βασεων δεδομενων
Οι όροι ασφάλεια και ακεραιότητα ακούγονται συχνά μαζί όταν
γίνεται αναφορά σε βάσεις δεδομένων, αν και
οι δύο έννοιες είναι στην πραγματικότητα εντελώς διαφορετικές.
Η ασφάλεια (security) αναφέρεται στην προστασία δεδομένων από τη γνωστοποίηση, την αλλοίωση, ή την καταστροφή από μη εξουσιοδοτημένα άτομα
H ακεραιότητα αναφέρεται στην ακρίβεια ή την εγκυρότητα των δεδομένων. Με άλλα λόγια:
Ασφάλεια σημαίνει να εξασφαλίζεται ότι οι χρήστες επιτρέπεται να κάνουν αυτά που επιχειρούν να κάνουν.
Ακεραιότητα (integrity) σημαίνει να εξασφαλίζεται ότι αυτά που επιχειρούν να κάνουν οι χρήστες είναι σωστά και δεν θα πρέπει να μπορούν να τροποποιούν πράγματα που δεν πρέπει. π.χ., ένας φοιτητής δεν μπορεί να βάλει βαθμούς
Μυστικότητα (secrecy) οι χρήστες θα πρέπει να μπορούν να δουν μόνο ότι πρέπει π.χ., ένας φοιτητής δεν θα πρέπει να μπορεί να δει τους βαθμούς άλλων φοιτητών
Διαθεσιμότητα (availability) Οι χρήστες θα πρέπει να μπορούν να δούν και να αλλάξουν τα πράγματα που τους επιτρέπεται
Υπάρχουν βέβαια και μερικές ομοιότητες: Και σε αυτές τις περιπτώσεις, το σύστημα χρειάζεται να είναι ενήμερο για ορισμένους κανόνες που δεν πρέπει να παραβιάζουν οι χρήστες, οι κανόνες αυτοί πρέπει να καθορίζονται (κατά κανόνα, από τον υπεύθυνο διαχείρισης βάσεων δεδομένων — DBA) σε κάποια κατάλληλη γλώσσα, και να τηρούνται στον κατάλογο του συστήματος. Το DBMS πρέπει να παρακολουθεί τις πράξεις των χρηστών με κάποιον τρόπο, για να εξασφαλίζει την τήρηση των κανόνων.
9.2 Προβλήματα
Το πρόβλημα της ασφάλειας (security) έχει πολλές πλευρές, μεταξύ των οποίων οι παρακάτω:
Νομικές, κοινωνικές, και ηθικές πλευρές (για παράδειγμα, το άτομο που υποβάλλει την αίτηση, π.χ., για την πίστωση ενός πελάτη, έχει νομικό δικαίωμα για πρόσβαση στις πληροφορίες που ζητάει;)
Φυσικοί έλεγχοι (για παράδειγμα, είναι η αίθουσα του υπολογιστή ή του τερματικού κλειδωμένη ή ασφαλισμένη με κάποιον άλλον τρόπο;)
Ζητήματα πολιτικής (για παράδειγμα, πώς αποφασίζει η επιχείρηση στην οποία ανήκει το σύστημα σε ποιον θα επιτρέπεται πρόσβαση σε τι;)
Λειτουργικά προβλήματα (για παράδειγμα, αν χρησιμοποιείται ένας μηχανισμός με συνθηματικά, πώς διατηρούνται κρυφά τα ίδια τα συνθηματικά και πόσο συχνά αλλάζουν;)
Έλεγχοι μέσω του υλικού (για παράδειγμα, παρέχει η μονάδα επεξεργασίας υπηρεσίες ασφάλειας, όπως κλειδιά προστασίας της μνήμης ή έναν προνομιακό τρόπο λειτουργίας;)
Ασφάλεια μέσω του λειτουργικού συστήματος (για παράδειγμα, το υποκείμενο λειτουργικό σύστημα σβήνει τα περιεχόμενα της μνήμης και τα αρχεία δεδομένων όταν τελειώσει την εργασία με αυτά;)
Και τέλος:
Ζητήματα που αφορούν ειδικά το ίδιο το σύστημα βάσης δεδομένων (για παράδειγμα, διαθέτει το σύστημα βάσης δεδομένων κάποια έννοια ιδιοκτησίας δεδομένων;)
Θα ασχοληθούμε κυρίως με ζητήματα αυτής της τελευταίας κατηγορίας μόνο.
9.3 Πολιτική Ασφάλειας
Μια πολιτική ασφάλειας καθoρίζει ποιος έχει τη δικαιοδοσία να κάνει τι
Τα αποτελέσματα αυτών των αποφάσεων πολιτικής (α) πρέπει να γνωστοποιηθούν στο σύστημα
(αυτό γίνεται με εντολές γραμμένες σε κάποια κατάλληλη γλώσσα ορισμών),
και (β) το σύστημα πρέπει να τα θυμάται
(αυτό γίνεται με την αποθήκευση τους στον κατάλογο, με τη μορφή κανόνων
ασφάλειας (security rule), που είναι γνωστοί και ως κανόνες εξουσιοδότησης
(authorization)).
Για τα αποτελέσματα αυτών των αποφάσεων πολιτικής πρέπει να υπάρχει ένα μέσο για τον έλεγχο μιας δεδομένης αίτησης πρόσβασης με βάση τους ισχύοντες κανόνες ασφάλειας. (Με τον όρο "αίτηση πρόσβασης" εδώ εννοούμε γενικά το συνδυασμό αιτούμενη πράξη συν αιτούμενο αντικείμενο συν αιτών χρήστης.) Ο έλεγχος αυτός γίνεται από το υποσύστημα ασφάλειας του DBMS, που είναι γνωστό και ως υποσύστημα εξουσιοδοτήσεων.
Το DBMS για να μπορεί να αποφασίζει ποιοι κανόνες ασφάλειας ισχύουν για μια δεδομένη αίτηση πρόσβασης, πρέπει να έχει τη δυνατότητα να αναγνωρίζει την προέλευση αυτής της αίτησης — δηλαδή, τον αιτούντα χρήστη. Γι' αυτόν το λόγο, όταν οι χρήστες εισέρχονται (sign on) στο σύστημα, συνήθως απαιτείται να δίνουν όχι μόνο την ταυτότητα τους (user ID — για να δηλώσουν ποιοι είναι) αλλά και ένα συνθηματικό (password — για να αποδείξουν ότι είναι αυτοί που ισχυρίζονται ότι είναι). Το συνθηματικό υποτίθεται ότι είναι γνωστό μόνο στο σύστημα και στους νόμιμους χρήστες που έχουν τη συγκεκριμένη ταυτότητα χρήστη.
9.1 Μηχανισμός Ασφάλειας
Ένας μηχανισμός ασφάλειας μας επιτρέπει την εφαρμογή μιας συγκεκριμένης πολιτικής
Στο επίπεδο του ΣΔΒΔ δύο βασικοί μηχανισμοί
Α. Επιλεκτικός μηχανισμός ασφάλειας ή Περιπτωσιακός έλεγχος. (discretionary access control): εκχώρηση προνομίων στους χρήστες. Κάθε χρήστης έχει διαφορετικά δικαιώματα πρόσβασης (προνόμια-privileges, εξουσίες-authorities). Οι μηχανισμοι αυτού του τύπου είναι πολύ ευέλικτοι και οι συνηθέστεροι στα περισσότερα ΣΣΔΒΔ.
Β. Υποχρεωτικός μηχανισμός ασφάλειας ή Κανονιστικός έλεγχος. (manadatory access control): επιβολή ασφάλειας πολλών επιπέδων - διαχωρισμός των χρηστών σε διάφορα επίπεδα (κλάσεις) ασφάλειας. Κάθε αντικείμενο χαρακτηρίζεται με επίπεδο βαθμού ασφαλείας (classification) και κάθε χρήστης έχει ορισμένο επίπεδο δικαιοδοσίας (clearance). Μηχανισμοί ελέγχου άκαμπτοι.
9.2 Ο Διαχειριστής ΒΔ
Ο ΔΒΔ αποτελεί την κεντρική αρχή για την διαχείριση ενός συστήματος βάσεων δεδομένων. Στα καθήκοντα του ΔΒΔ περιλαμβάνεται και η εκχώρηση δικαιωμάτων στους χρήστες που πρέπει να χρησιμοποιήσουν στο σύστημα, καθώς και η ένταξη των χρηστών και των δεδομένων σε επίπεδα ασφάλειας, σύμφωνα με την πολιτική του οργανισμού. Ο ΔΒΔ έχει ένα προνομιακό λογαριασμό στον ΣΔΒΔ, ο οποίος μερικές φορές ονομάζεται λογαριασμός συστήματος και παρέχει αυξημένες δυνατότητες οι οποίες δεν είναι διαθέσιμες στους κοινούς λογαριασμούς και χρήστες της βάσης δεδομένων. Ο λογαριασμός αυτός είναι παρόμοιος με τον λογαριασμό υπερχρήστη (ή root) που έχουν οι διαχειριστές υπολογιστικών συστημάτων και που επιτρέπει προσπέλαση σε διαβαθμισμένες εντολές του λειτουργικού συστήματος. Οι προνομιακές εντολές του ΔΒΔ περιλαμβάνουν εντολές για εκχώρηση και αφαίρεση δικαιωμάτων σε μεμονωμένους λογαριασμούς , χρήστες ή ομάδες χρηστών, καθώς και για την εκτέλεση των παρακάτω λειτουργιών:
1. Δημιουργία λογαριασμού : η λειτουργία αυτή δημιουργεί ένα νέο λογαριασμό και ένα συνθηματικό για ένα χρήστη ή για μια ομάδα χρηστών, επιτρέποντας τους την προσπέλαση στο ΣΔΒΔ
2. Εκχώρηση προνομίων: η λειτουργία αυτή επιτρέπει στο ΔΒΔ να εκχωρήσει διάφορα προνόμια σε συγκεκριμένους λογαριασμούς
3. Αφαίρεση προνομίων : η λειτουργία αυτή επιτρέπει στο ΔΒΔ να αφαιρέσει (ακυρώσει) διάφορα προνόμια που είχαν δοθεί προηγουμένως σε συγκεκριμένους λογαριασμούς
4. Καθορισμός επιπέδου ασφάλειας : η λειτουργία αυτή συνιστάται στην αντιστοίχηση λογαριασμών των χρηστών στα κατάλληλα επίπεδα ασφάλειας
User ID :
Password :
User Groups --->
διαφορετικά προνόμια
Ο ΔΒΔ είναι υπεύθυνος για την συνολική ασφάλεια του συστήματος της βάσης δεδομένων. Η λειτουργία 1 στην παραπάνω λίστα χρησιμοποιείτε για να ελέγχεται η προσπέλαση στο ΣΔΒΔ συνολικά, ενώ οι λειτουργίες 2 και 3 χρησιμοποιούνται για τον έλεγχο της επιλεκτικής ασφάλειας στην βάση δεδομένων και η λειτουργία 4 χρησιμοποιείται για τον έλεγχο των υποχρεωτικών δικαιοδοσιών.
9.3 Προστασία Προσπέλασης, Λογαριασμοί Χρηστών και Επιθεωρήσεις Βάσεων Δεδομένων.
Όταν ένα άτομο ή μια ομάδα ατόμων πρέπει να αποκτήσει προσπέλαση σε ένα σύστημα βάσεων δεδομένων, πρέπει πρώτα να ζητήσει ένα λογαριασμό χρήστη. Ο ΔΒΔ, αν υπάρχει δικαιολογημένη ανάγκη για προσπέλαση στην βάση δεδομένων, θα δημιουργήσει έναν νέο αριθμό λογαριασμού και ένα συνθηματικό για τον χρήστη. Ο χρήστης κάθε φορά που επιθυμεί να προσπελάσει την βάση δεδομένων, πρέπει να συνδεθεί (log –in) στο ΣΔΒΔ εισάγοντας τον αριθμό λογαριασμού και το συνθηματικό. Το ΣΔΒΔ ελέγχει την εγκυρότητα του λογαριασμού και του συνθηματικού και, αν είναι έγκυρα, επιτρέπεται στον χρήστη να χρησιμοποιήσει το ΣΔΒΔ και να προσπελάσει τη βάση δεδομένων. Τα προγράμματα εφαρμογών μπορούν επίσης να θεωρηθούν χρήστες και είναι δυνατόν να απαιτείται από αυτά να δίνουν συνθηματικά.
Είναι εύκολη η παρακολούθηση των χρηστών της βάσης δεδομένων, των λογαριασμών και των συνθηματικών τους με την δημιουργία ενός κρυπτογραφημένου πίνακα ή αρχείου με δύο πεδία, τα Αριθ_Λογαριασμού και Συνθηματικό. Ο πίνακας αυτός μπορεί εύκολα να συντηρηθεί από το ΣΔΒΔ. Όταν δημιουργείται ένας νέος λογαριασμός, μια νέα εγγραφή εισάγεται στον πίνακα. Όταν ακυρώνεται ένας λογαριασμός, πρέπει να διαγραφεί από τον πίνακα η αντίστοιχη εγγραφή.
Το σύστημα της βάσης δεδομένων πρέπει επίσης να παρακολουθεί όλες τις πράξεις που εφαρμόζονται από ένα χρήστη στην βάση δεδομένων κατά την διάρκεια μιας συνόδου σύνδεσης (log –in session), η οποία αποτελείται από την ακολουθία των αλληλεπιδράσεων με την βάση δεδομένων που εκτελεί ο χρήστης από την στιγμή της σύνδεσης του μέχρι την στιγμή αποσύνδεσης (log off). Όταν ένας χρήστης συνδέεται με το σύστημα, το ΣΔΒΔ μπορεί να καταγράψει τον αριθμό λογαριασμού του χρήστη και να τον αντιστοιχίσει με το τερματικό από το οποίο ο χρήστης συνδέθηκε. Όλες οι πράξεις που γίνονται από το τερματικό αυτό αποδίδονται στον λογαριασμό του χρήστη, μέχρι ο χρήστης να αποσυνδεθεί. Είναι ιδιαίτερα σημαντικό να παρακολουθούνται οι πράξεις ενημέρωσης που εφαρμόζονται στην βάση δεδομένων, έτσι ώστε αν προκληθεί βλάβη στην βάση δεδομένων να έχει ο ΔΒΔ την δυνατότητα να ανακαλύψει ποιος την προξένησε.
Για την καταγραφή όλων των ενημερώσεων που εφαρμόζονται στην βάση δεδομένων, καθώς και του χρήστη που εκτέλεσε κάθε ενημέρωση, μπορούμε να τροποποιήσουμε τον κατάλογο του συστήματος. Υπενθυμίζουμε ότι το ημερολόγιο συστήματος περιλαμβάνει μία καταχώρηση για κάθε πράξη που εφαρμόζεται στην βάση δεδομένων και που είναι δυνατόν να χρειασθεί (για αναίρεση ή επανάληψη) κατά την διαδικασία ανάκαμψης από αποτυχία δοσοληψίας ή κατάρρευσης συστήματος. Μπορούμε να επεκτείνουμε τις καταχωρήσεις του ημερολογίου ώστε να περιλάβουν τον αριθμό λογαριασμού του χρήστη και την ταυτότητα του τερματικού άμεσης πρόσβασης που εκτέλεσε κάθε πράξη που έχει καταγραφεί στο ημερολόγιο. Αν υπάρχει υποψία βλάβης στη βάση δεδομένων διενεργείται επιθεώρηση της βάσης δεδομένων (database audit), η οποία συνίσταται στην επιθεώρηση του ημερολογίου προκειμένου να ελεγχθούν όλες οι πράξεις που εφαρμόστηκαν στην βάση δεδομένων κατά την διάρκεια μιας συγκεκριμένης χρονικής στιγμής. Όταν βρεθεί μια μη επιτρεπόμενη ή παράνομη πράξη, ο ΔΒΔ μπορεί να εντοπίσει τον αριθμό λογαριασμού που εκτέλεσε την πράξη αυτή. Οι επιθεωρήσεις των βάσεων δεδομένων είναι ιδιαίτερα σημαντικές σε ευαίσθητες βάσεις δεδομένων οι οποίες ενημερώνονται από πολλές δοσοληψίες και χρήστες, όπως οι τραπεζικές βάσεις δεδομένων που ενημερώνονται από πολλούς υπαλλήλους της τράπεζας. Ένα ημερολόγιο βάσης δεδομένων που χρησιμοποιείται κυρίως για λόγους ασφαλείας ονομάζεται μερικές φορές αρχείο επιθεώρησης ή ίχνος ελέγχου (audit trail).
9.4 Ίχνος Έλεγχου
Είναι σημαντικό να μη θεωρούμε ότι το σύστημα ασφάλειας είναι
τέλειο. Ένας επίδοξος εισβολέας που είναι αρκετά αποφασισμένος θα βρει συνήθως
έναν τρόπο να ξεπεράσει τους ελέγχους, ιδιαίτερα αν η ανταμοιβή του θα είναι
αρκετά μεγάλη. Γι' αυτό, σε περιπτώσεις που τα δεδομένα είναι αρκετά
εμπιστευτικά ή η επεξεργασία τους έχει αρκετά κρίσιμη σημασία, ένα ίχνος
ελέγχου (audit trail) είναι απαραίτητο. Αν, για παράδειγμα, κάποιες ασυνέπειες
των δεδομένων οδηγούν στην υποψία ότι κάποιος έχει πειράξει τη βάση δεδομένων,
το ίχνος ελέγχου μπορεί να χρησιμοποιηθεί για να εξεταστεί τι έχει συμβεί και
να εξακριβωθεί αν τα πράγματα είναι υπό έλεγχο — ή τουλάχιστον, στην περίπτωση
που δεν είναι υπό έλεγχο, να βοηθήσει στον εντοπισμό του ενόχου. Ένα ίχνος
ελέγχου είναι ουσιαστικά ένα ειδικό αρχείο ή βάση δεδομένων, μέσα στο οποίο το
σύστημα παρακολουθεί αυτόματα όλες τις πράξεις που γίνονται από τους χρήστες
στη βάση δεδομένων. Μια τυπική καταχώριση στο ίχνος ελέγχου μπορεί να περιέχει
τις παρακάτω πληροφορίες:
- αίτηση (πηγαίος κώδικας)
- τερματικό από το οποίο κλήθηκε η πράξη
- χρήστης που κάλεσε την πράξη
- ημερομηνία και ώρα της πράξης
- βασικές σχέσεις, συστοιχίες και γνωρίσματα που επηρεάστηκαν
- παλιές τιμές
- νέες τιμές
Όπως αναφέραμε πιο πάνω, το ίδιο το γεγονός ότι υπάρχει ένα
ίχνος ελέγχου μπορεί να είναι αρκετό από μόνο του για να αποτρέψει έναν επίδοξο
εισβολέα σε μερικές περιπτώσεις.
9.5 Επιλεκτικός ή Περιπτωσιακός Eλεγχος Προσπέλασης
Βασίζεται στην έννοια των δικαιωμάτων προσπέλασης ή προνομίων πάνω σε αντικείμενα (όπως πίνακες ή όψεις) και μηχανισμούς εκχώρησης και αφαίρεσης προνομίων στους χρήστες
9.5.1
Επιλεκτικός ή Περιπτωσιακός Έλεγχος
Προσπέλασης βάσει Όψεων
Δυο επίπεδα δικαιωμάτων:
Επίπεδο λογαριασμού (γίνεται από αυτούς που υλοποιούν το ΣΔΒΔ) Παραδείγματα προνομίων: create schema, create table, create view, alter, drop, modify, select
Επίπεδο σχέσης (ορίζονται ως τμήμα της SQL) Προσδιορίζουν για κάθε χρήστη τις σχέσεις στις οποίες μπορεί να εφαρμοστεί κάθε τύπος εντολής
Μοντέλο Πίνακα Προσπέλασης (Access Matrix Model)
Πίνακας προσπέλασης M(i, j) ::
i: υποκείμενο (π.χ, χρήστης, λογαριασμός, πρόγραμμα)
j: αντικείμενο (σχέση, εγγραφή (πλειάδα), στήλη (γνώρισμα), όψη, πράξη)
αναπαριστά τον τύπο των προνομίων (εγγραφή, ανάγνωση, τροποποίηση) που έχει το υποκείμενο i στο αντικείμενο j
Εφαρμόζοντας το παραπάνω μοντέλο πίνακα προσπέλασης στην SQL μπορούμε να πούμε ότι για κάθε συναλλαγή M(i, j) :
i: υποκείμενο (π.χ, χρήστης, λογαριασμός, πρόγραμμα)
j: μόνο σχέση, όψη, στήλη (γνώρισμα)
Ο δημιουργός ενός πίνακα ή μιας όψης παίρνει αυτόματα όλα τα προνόμια σε αυτόν και καλείται ιδιοκτήτης.
Το ΣΔΒΔ διατηρεί πληροφορίες σχετικά με το ποιος παίρνει ή χάνει προνόμια και επιτρέπει μόνο αιτήσεις από χρήστες που έχουν τα απαραίτητα προνομία όταν γίνεται η αίτηση
9.5.3
Η εντολή GRANT
Σύνταξη
GRANT privileges ON object TO users [WITH
GRANT OPTION]
Επιτέπονται τα παρακάτω προνόμια-privileges :
SELECT: Μπορεί να διαβάσει όλες τις στήλες (συμπεριλαμβανομένων αυτών που μπορεί να προστεθούν αργότερα με την εντολή ALTER TABLE).
INSERT (όνομα στήλης
Α): Μπορεί να εισάγει πλειάδες με non-null ή
non-default τιμές στη στήλη Α.
INSERT σημαίνει το ίδιο για όλες τις στήλες.
DELETE: Μπορεί να διαγράφει πλειάδες.
UPDATE(όνομα στήλης Α)
REFERENCES (όνομα στήλης Α): Μπορεί να ορίσει ξένα κλειδιά (σε άλλους πίνακες) που αναφέρονται στην στήλη Α.
Αν ένας χρήστης έχει ένα προνόμιο με το GRANT OPTION μπορεί να δώσει αυτό το προνόμιο σε άλλους χρήστες (μπορεί να δώσει ή να μη δώσει το GRANT OPTION).
Αν και δεν έχουν ακόμα υλοποιηθεί υπάρχουν μηχανισμοί για τον περιορι-σμό της διάδοσης προνομίων
Τα προνόμια CREATE, ALTER, και DROP μπορεί να εκτελεστούν μόνο από τον ιδιοκτήτη.
9.5.4
Η εντολή REVOKE
Σύνταξη
REVOKE privileges ON object FROM users
Με την εντολή αυτή γίνετε αφαίρεση προνομίου από έναν χρήστη
Όταν αφαιρεθεί ένα προνόμιο από το χρήστη Χ αφαιρείται και από όλους τους χρήστες που πήραν αυτό το προνόμιο αποκλειστικά από αυτόν
Παράδειγμα 9.1
GRANT
INSERT, SELECT ON Student TO
Alex
Ο χρήστης Alex μπορεί να κάνει ερωτήσεις και να εισάγει πλειάδες στη σχέση Student
GRANT DELETE ON Student
TO Grammateia WITH GRANT OPTION
Ο χρήστης Grammateia μπορεί να διαγράφει πλειάδες από τη σχέση Student και μπορεί να εξουσιοδοτήσει και άλλους για αυτό.
GRANT UPDATE (THL) ON Student TO User1
Ο χρήστης User1 μπορεί να τροποποιεί (μόνο) το γνώρισμα THL της σχέσης Student .
9.5.5
Επιλεκτικός Έλεγχος Προσπέλασης στις
Όψεις
Οι όψεις μπορεί να χρησιμοποιηθούν για να δώσουν μόνο την απαραίτητη πληροφορία.
Οι όψεις μαζί με τις εντολές GRANT/ REVOKΕ αποτελούν ένα πολύ ισχυρό εργαλείο για τον έλεγχο προσπέλασης
Ο δημιουργός μιας όψης έχει ένα προνόμιο πάνω στην όψη μόνο αν έχει το προνόμιο σε όλες τις σχέσεις που περιλαμβάνονται στον ορισμό της όψης
Για την δημιουργία της όψης απαιτείται το προνόμιο SELECT σε όλες τις σχέσεις που περιλαμβάνονται στον ορισμό της όψης
Πως μπορούμε να ορίσουμε προνόμια στο επίπεδο του ενός γνωρίσματος μιας πλειάδας
Η SQL-92, δίνει προνόμια σε authorization ids, που μπορεί να αναφέρονται σε ένα χρήστη ή σε μια ομάδα χρηστών
Η SQL:1999 (και σε αρκετά συστήματα), δίνει προνόμια σε ρόλους.
Στη συνέχεια μπορεί να ανατεθούν ρόλοι σε χρήστες ή σε άλλους ρόλους
9.5.6
SECURITY RULE
Σύνταξη
CREATE SECURITY RULE κανόνας GRANT λίστα-προνομίων ON παράσταση ΤΟ λίστα-χρηστών [ ON ATTEMPTED VIOLATION ενέργεια } ;
Επεξήγηση:
Ο κανόνας είναι το όνομα του νέου κανόνα ασφάλειας.
Κάθε προνόμιο είναι ένα από τα εξής:
RETRIEVE [ ( λίστα-γνωρισμάτων ) ]
INSERT
UPDATE [ ( λίστα-γνωρισμάτων ) ]
DELETE
ALL
Φυσικά, χρειαζόμαστε και έναν τρόπο για να καταργούμε
υπάρχοντες κανόνες:
Σύνταξη
DESTROY
SECURITY RULE
κανόνας ;
9.6 Υποχρεωτικός ή Κανονιστικός Ελεγχος Προσπέλασης
Οι έλεγχοι που γίνονται από ΣΔΒΔ βασίζονται σε πολιτικές που ισχύουν για όλο το σύστημα και δεν μπορούν να τροποποιηθούν από συγκεκριμένους χρήστες. Σε κάθε αντικείμενο της ΒΔ ανατίθεται και μια κλάση ασφάλειας.
Σε κάθε υποκείμενο (χρήστη ή πρόγραμμα) ανατίθεται και ένα δικαίωμα για μια κλάση ασφάλειας
Κανόνες αυτοί είναι βασιζόμενοι στις κλάσεις ασφάλειας και στα δικαιώματα τα οποία καθορίζουν ποιος μπορεί να διαβάσει ή να γράψει και σε ποια ακριβώς αντικείμενα
Ο Χρήστης i μπορεί να δεί το αντικείμενο j εάν το επίπεδο δικαιοδοσίας του i είναι μεγαλύτερο ή ίσο του επίπεδου ασφαλείας του j. Ο Χρήστης i μπορεί να τροποποιήσει το αντικείμενο j εάν το επίπεδο δικαιοδοσίας του i είναι μεγαλύτερο ή ίσο του επίπεδου ασφαλείας του j. Κάθε τι που γράφει ο χρήστης i έχει επίπεδο ασφαλείας ίσο με το επίπεδο δικαιοδοσίας του i
9.6.1
Κλάσεις Ασφάλειας
Οι προδιαγραφές ορίζουν τέσσερις κλάσεις ασφάλειας (security classes), τις D, C, Β, και Α. με απλά λόγια, η κλάση D είναι η λιγότερο ασφαλής, η κλάση C είναι πιο ασφαλής από την D, κ.ο.κ. Η κλάση D λέμε ότι παρέχει ελάχιστη προστασία, η κλάση C περιπτωσιακή προστασία, η κλάση Β κανονιστική προστασία, και η κλάση Α βεβαιωμένη προστασία.
• Περιπτωσιακή προστασία (discretionary protection): Η κλάση ασφάλειας C υποδιαιρείται σε δύο επιμέρους κλάσεις, τις C1 και C2 (όπου η C1 είναι λιγότερο ασφαλής από τη C2). Η κάθε μία υποστηρίζει τον περιπτωσιακό έλεγχο πρόσβασης, που σημαίνει ότι ο έλεγχος πρόσβασης είναι στη διακριτική ευχέρεια του ιδιοκτήτη των δεδομένων.
• Η κλάση C1 απαιτεί το διαχωρισμό των δεδομένων και των χρηστών' δηλαδή, υποστηρίζει την έννοια των μεριζόμενων δεδομένων, ενώ επιτρέπει να έχουν οι χρήστες και δικά τους ιδιωτικά δεδομένα.
• Η κλάση C2 απαιτεί επιπλέον την υποστήριξη λογαριασμών (accountability support), με διαδικασίες ελέγχου εισόδου του χρήστη (sign-on), λογιστικού ελέγχου (auditing) και απομόνωσης πόρων.
• Δομημένη προστασία (structured protection): Η κλάση ασφάλειας Β είναι η κλάση που αναλαμβάνει τους κανονιστικούς ελέγχους. Υποδιαιρείται σε τρεις επιμέρους κλάσεις, τις B1, B2, και Β3 (όπου η Β1 είναι η λιγότερο ασφαλής από τις τρεις και η Β3 η περισσότερο ασφαλής). Η κλάση Β1 απαιτεί "προστασία με ετικέτες" (δηλαδή, απαιτεί να έχει το κάθε αντικείμενοως ετικέτα το επίπεδο βαθμού ασφαλείας του — απόρρητο, εμπιστευτικό, κ.λπ.). Απαιτεί επίσης μια άτυπη δήλωση της πολιτικής που εφαρμόζεται σε σχέση με την ασφάλεια. Η κλάση Β2 απαιτεί επιπλέον μια τυπική δήλωση της πολιτικής που εφαρμόζεται σε σχέση με την ασφάλεια' απαιτεί επίσης να εντοπιστούν και να εξαλειφθούν τα συγκαλυμμένα κανάλια (covert channel)' ένα παράδειγμα συγκαλυμμένου καναλιού είναι η δυνατότητα να προκύπτει η απάντηση ενός μη επιτρεπτού ερωτήματος από την απάντηση ενός επιτρεπτού ερωτήματος.Η κλάση Β3 απαιτεί να υποστηρίζεται ο λογιστικός έλεγχος (audit) και η ανάκαμψη, και να υπάρχει ένας διορισμένος υπεύθυνος διαχείρισης ασφάλειας (security administrator).
• Βεβαιωμένη προστασία (verified protection): Η κλάση ασφάλειας Α, η πιο ασφαλής, απαιτεί μια μαθηματική απόδειξη ότι (α) ο μηχανισμός ασφάλειας είναι συνεπής, και (β) είναι επαρκής για την υποστήριξη της καθορισμένης πολιτικής για την ασφάλεια.
Τα DBMS που υποστηρίζουν υποχρεωτικούς ελέγχους προσπέλασης λέγονται, συχνά, συστήματα με πολυεπίπεδη ασφάλεια (multilevel secure).
Τα περισσότερα εμπορικά συστήματα δεν υποστηρίζουν τον υποχρεωτικό έλεγχο πρόσβασης.
Παράδειγμα 9.2
Ποια είναι αντικείμενα ποια υποκείμενα και ποιες οι κλάσεις ασφαλείας στον κανονιστικό έλεγχο;
Λύση
Αντικείμενα (π.χ., πίνακες, όψεις, πλειάδες)
Υποκείμενα (π.χ., χρήστες, προγράμματα)
Κλάσεις ασφάλειας:
Άκρως Απόρρητη (TS), Απόρρητη (S), Εμπιστευτική (C), Αδιαβάθμητη (U):
TS > S
> C > U
Σε κάθε αντικείμενο και υποκείμενο ανατίθεται μια κλάση.
Το υποκείμενο S μπορεί να διαβάσει το αντικείμενο O μόνο αν class(S) >= class(O) (Απλή Ιδιότητα Ασφάλειας)
Το υποκείμενο S μπορεί να γράψει το αντικείμενο O μόνο αν class(S) <= class(O) (Ιδιότητα)
Η ιδέα είναι ότι πληροφορία δεν περνά ποτέ από μια υψηλή κλάση ασφάλειας σε μια χαμηλή κλάση ασφάλειας
Η υποχρεωτική προστασία εφαρμόζεται επιπρόσθετα της επιλεκτικής προστασίας.
Παράδειγμα 9.3
Τι θα συμβεί σε ένα κανάλι διαρροής;
Στον παρακάτω πίνακα καταχωρούν δεδομένα οι χρήστες με διαφορετικά προνόμια και διαφορετικές κλάσεις πρόσβασης.
Χρήστες με επίπεδο δικαιοδοσίας S και TS μπορούν να δουν και τις δυο γραμμές, οι χρήστες με C βλέπουν μόνο 2η γραμμή; ενώ χρήστες με U δε βλέπουν καμία.
Αν ένας χρήστης με C προσπαθήσει να εισάγει <101,VW Golf, Blue,C>, τι θα συμβεί;
Αν επιτρέψουμε την εισαγωγή, γίνετε παραβίαση του περιορισμού κλειδιού.
Αν δεν του επιτρέψουμε να εισάγει δεδομένα αποκαλύπτουμε ότι υπάρχει ένα άλλο αντικείμενο με κλειδί 101 και κλάση C. Και τελικά αποκαλύπτουμε ότι η κλάση είναι μέρος του κλειδιού ενώ δεν θα έπρεπε.
Το πρόβλημα που παρουσιάζεται το ονομάσαμε κανάλι διαρροής (covert channel). Η λύση σε αυτή την διαρροή πληροφόρησης σε μη εξουσιοδοτημένα άτομα μπορεί να δοθεί με την δημιουργία πολλαπλών στιγμιότυπων
10 . Κρυπτογράφηση
Κρυπτογράφηση των δεδομένων (data encryption) ονομάζουμε την αποθήκευση ή την μετάδοση των εμπιστευτικών δεδομένων σε κωδικοποιημένη μορφή.
Για να μπορέσουμε να εξετάσουμε μερικές από τις έννοιες της κρυπτογράφησης δεδομένων, χρειάζεται να εισαγάγουμε μερικούς όρους ακόμα.
Τα αρχικά πραγματικά δεδομένα ονομάζονται απλό κείμενο (plaintext).
Στo απλό κείμενο που πρόκειται να κρυπτογραφηθεί εφαρμόζουμε του έναν αλγόριθμο κρυπτογράφησης, που η είσοδος του είναι το απλό κείμενο και ένα κλειδί κρυπτογράφησης.
Η έξοδος αυτού του αλγορίθμου - η κρυπτογραφημένη μορφή του απλού κειμένου - ονομάζεται κρυπτογραφικό κείμενο (ciphertext).
Οι λεπτομέρειες του αλγορίθμου κρυπτογράφησης γνωστοποιούνται, ή τουλάχιστον δεν κρύβονται ιδιαίτερα, αλλά το κλειδί της κρυπτογράφησης κρατιέται μυστικό.
Το κρυπτογραφικό κείμενο, που θα πρέπει να είναι ακατανόητο σε οποιονδήποτε δεν έχει το κλειδί της κρυπτογράφησης, είναι εκείνο που αποθηκεύεται στη βάση δεδομένων ή μεταδίδεται μέσα από τη γραμμή επικοινωνίας.
10.1 Απλός Μηχανισμός Κρυπτογράφησης
Στο κεφαλαίο αυτό θα παρουσιάσουμε έναν απλό μηχανισμό κρυπτογράφησης με υποκατάσταση, όπου θα γίνεται χρήση ενός κλειδιού με συγκεκριμένο μήκος και περιορισμένο πεδίο ορισμού.
Έστω ότι το απλό κείμενο που καλούμαστε να κρυπτογραφήσουμε είναι το παρακάτω με ένα αυθαίρετο κλειδί κρυπτογράφησης:
Απλό κείμενο (PLAINTEXT)= TMHMA PLHROFORIKHS
ΚΛΕΙΔΙ= TEST
Αλγόριθμος
1. Διαίρεση του κειμένου σε ίσα τμήματα με το κλειδί και αντικατάσταση του κενού με το σύμβολο +
TMHM A+PL HROF ORIK HS++
2. Αντικατάσταση χαρακτήρων με αριθμούς από 00-26.
 Για
λόγους απλότητας λαμβάνουμε υπόψη μόνο
τους λατινικούς χαρακτήρες. Δηλ. το πεδίο ορισμού που μπορεί να πάρει ο κάθε
χαρακτήρας είναι μόνο 27 λατινικά γράμματα. Στην πράξη πεδίο ορισμού θα
μπορούσε να είναι το σύνολο των ASCII
χαρακτήρων ή των Uniform χαρακτήρων.
Για
λόγους απλότητας λαμβάνουμε υπόψη μόνο
τους λατινικούς χαρακτήρες. Δηλ. το πεδίο ορισμού που μπορεί να πάρει ο κάθε
χαρακτήρας είναι μόνο 27 λατινικά γράμματα. Στην πράξη πεδίο ορισμού θα
μπορούσε να είναι το σύνολο των ASCII
χαρακτήρων ή των Uniform χαρακτήρων.
Αντικαθιστούμε κάθε γράμμα με τον διψήφιο αριθμό του. Δηλ.
Κενό=00 Α=01, Β=02, C=03……Z=26
TMHM A+PL HROF
κείμενο 20130813 01001612 ……….
κλειδί 20051920 20051920 20051920
40182733 21133532 …………..
3. Άθροιση των παραπάνω
και διαίρεση του κάθε διψήφιου αριθμού με το 27
4.Το υπόλοιπο της διαίρεσης το κρατάμε
Στην πράξη αφαιρούμε το 27 από κάθε αριθμό που είναι μεγαλύτερος
του 27 και Κρατάμε την διαφορά. Διαφορετικά κρατάμε τον ίδιο τον αριθμό.
Αποτέλεσμα 13180006 21130805 …………..
Κρυπτογραφημένο κείμενο
5. Αντικατάσταση κάθε αριθμού με τον χαρακτήρα που αντιστοιχεί
ΜR+F UMHE ………...
10.2 ΤΟ
ΠΡΟΤΥΠΟ DES (DATA ENCRYPTION
STANDARD)
ΥΠΟΚΑΤΑΣΤΑΣΗ (SUBSTITUTION) :χρησιμοποιεί ένα κλειδί κρυπτογράφησης έτσι ώστε να προσδιοριστεί, για τον κάθε χαρακτήρα απλού κειμένου, ένας χαρακτήρας κρυπτογραφικού κειμένου με τον οποίο θα υποκατασταθεί αυτός ο χαρακτήρας
ΜΕΤΑΘΕΣΗ (PERMUTATION) οι χαρακτήρες απλού κειμένου απλώς αναδιατάσσονται με κάποια διαφορετική σειρά.
Καμία από τις δύο αυτές προσεγγίσεις δεν είναι ιδιαίτερα ασφαλής από μόνη της, αλλά οι αλγόριθμοι που τις συνδυάζουν και τις δύο παρέχουν έναν πολύ υψηλό βαθμό ασφάλειας.
Ένας τέτοιος αλγόριθμος είναι το πρότυπο DES (Data Encryption Standard — Πρότυπο Κρυπτογράφησης Δεδομένων), που υιοθετήθηκε για πρώτη φορά ως ομοσπονδιακό πρότυπο των ΗΠΑ το 1977
Το απλό κείμενο υποδιαιρείται σε τμήματα των 64 bit και το κάθε τμήμα κρυπτογραφείται με ένα κλειδί των 64 bit
Στην πραγματικότητα, το κλειδί αποτελείται από 56 bit δεδομένων + 8 bit ισοτιμίας, και επομένως δεν υπάρχουν 264 αλλά μόνο 256 πιθανά κλειδιά).
Για να κρυπτογραφηθεί ένα τμήμα, πρώτα εκτελείται μια αρχική μετάθεση πάνω σε αυτό, έπειτα το τμήμα που προκύπτει από τη μετάθεση υποβάλλεται σε μια ακολουθία 16 βημάτων σύνθετης υποκατάστασης, και τέλος εφαρμόζεται άλλη μία μετάθεση, η αντίστροφη της αρχικής, στο αποτέλεσμα του προηγούμενου βήματος.
Η υποκατάσταση στο βήμα i δεν ελέγχεται άμεσα από το αρχικό κλειδί κρυπτογράφησης Κ, αλλά από ένα κλειδί Κi που υπολογίζεται από τις τιμές Κ και i.
To DES έχει την ιδιότητα ότι ο αλγόριθμος αποκρυπτογράφησης είναι ο ίδιος με τον αλγόριθμο κρυπτογράφησης, με τη διαφορά ότι τα κλειδιά Κi εφαρμόζονται με αντίστροφη σειρά
10.3 Κρυπτογράφηση με Δημόσιο Κλειδί
Σε ένα μηχανισμό με δημόσιο κλειδί (public-key), τόσο ο αλγόριθμος κρυπτογράφησης όσο και 'το κλειδί κρυπτογράφησης είναι διαθέσιμα σε όλους' έτσι, ο καθένας μπορεί να μετατρέψει κάποιο απλό κείμενο σε κρυπτογραφικό κείμενο.
Tο αντίστοιχο κλειδί αποκρυπτογράφησης διατηρείται μυστικό (οι μηχανισμοί με δημόσιο κλειδί έχουν δύο κλειδιά, ένα για την κρυπτογράφηση και ένα για την αποκρυπτογράφηση).
Tο κλειδί αποκρυπτογράφησης δεν είναι δυνατό να προκύψει από το κλειδί κρυπτογράφησης" έτσι, ακόμα και το άτομο που κάνει την αρχική κρυπτογράφηση δεν μπορεί να κάνει την αντίστοιχη αποκρυπτογράφηση αν δεν έχει την εξουσιοδότηση να το κάνει.
10.4 Mηχανισμός RSA
Ο μηχανισμός κρυπτογράφησης αυτός πήρε το όνομά του από τα αρχικά των εμπνευστών της, Rivest, Shamir, και Adleman)
Bασίζεται στα εξής δύο γεγονότα:
1. Υπάρχει ένας γνωστός γρήγορος αλγόριθμος με τον οποίο μπορεί να προσδιοριστεί αν ένας δεδομένος αριθμός είναι πρώτος αριθμός.
2. Δεν υπάρχει κανένας γνωστός γρήγορος αλγόριθμος για την εύρεση των πρώτων παραγόντων ενός δεδομένου παραγώγου (δηλαδή, όχι πρώτου) αριθμού.
Για να προσδιοριστεί (σε έναν η/υ) αν ένας δεδομένος αριθμός με 130 ψηφία είναι πρώτος αριθμός, χρειάζονται περίπου επτά λεπτά, ενώ για να βρεθούν (στο ίδιο μηχάνημα) οι δύο πρώτοι παράγοντες ενός αριθμού 63 ψηφίων που προκύπτει από τον πολλαπλασιασμό δύο πρώτων αριθμών θα χρειάζονταν περίπου 40 τετράκις εκατομμύρια χρόνια.
10.4.1
Λειτουργία RSA
Ο μηχανισμός RSA λειτουργεί με τον εξής τρόπο:
1. Επιλέγονται τυχαία δύο διαφορετικοί μεγάλοι πρώτοι αριθμοί, ρ και q, και υπολογίζεται το γινόμενο r = p * q.
2. Επιλέγεται τυχαία ένας μεγάλος ακέραιος e που είναι σχετικά πρώτος (relatively prime) ως προς το γινόμενο (p — 1) * (q — 1). Ο ακέραιος e είναι το κλειδί της κρυπτογράφησης. Σημείωση: Η επιλογή του c είναι εύκολη. Οποιοσδήποτε πρώτος αριθμός, μεγαλύτερος και από τον ρ και από τον q, είναι κατάλληλος.
3. Παίρνουμε ως κλειδί αποκρυπτογράφησης d το μοναδικό "πολλαπλασιαστικό αντίστροφο" του ακεραίου υπολοίπου της διαίρεσης του e με το (p - 1) * (q - 1), δηλαδή:
d * e = 1 modulo (
p - 1 )
* ( g -
1 )
Ο αλγόριθμος για τον υπολογισμό του d με δεδομένα τα e, p, και q είναι απλός
4. Γνωστοποιούνται οι ακέραιοι r και e, όχι όμως ο d.
Ο μηχανισμός RSA λειτουργεί με τον εξής τρόπο:
Για να κρυπτογραφηθεί ένα απόσπασμα απλού κειμένου Ρ (που θεωρούμε για λόγους απλότητας ότι είναι ένας ακέραιος μικρότερος από τον r), αντικαθίσταται από το κρυπτογραφικό κείμενο C που υπολογίζεται με τον εξής τρόπο:
C = Pe modulo r
6. Για να αποκρυπτογραφηθεί ένα απόσπασμα κρυπτογραφικού κειμένου C, αντικαθίσταται από το απλό κείμενο Ρ που υπολογίζεται με τον εξής τρόπο:
Ρ = Cd modulo r
H αποκρυπτογράφηση του C με χρήση του d πραγματικά αποκαθιστά το αρχικό Ρ. Όμως, ο υπολογισμός του d με γνωστά μόνο τα r και e (και όχι τα ρ και q) είναι ανέφικτος
Παράδειγμα 10.2
Κρυπτογραφήστε τον χαρακτήρα Μ του προηγούμενου κώδιακα των 27 χαρακτήρων με τον αλγόριθμο RSA για p=3 και q=5.
Λύση.
Έστω p= 3 και q = 5, τότε r = 15, και το γινόμενο (p -1) * (q -1) =8
Έστω e = 11
Το e είναι ένας πρώτος αριθμός μεγαλύτερος και από το p και από το q και ο πλησιέστερος προς το γινόμενό τους.
Για να υπολογίσουμε το d, πρέπει να βρούμε το εξής: Ποίος είναι αυτός ο αριθμός ο οποίος αν πολλαπλασιαστεί με το e=11 και διαιρεθεί με το (p -1) * (q -1)=8 θα δώσει υπόλοιπο διαίρεσης ίσο με την μονάδα;
(d * 11) modulo 8 = 1
από το οποίο προκύπτει d = 3.
Έστω τώρα ότι το απλό κείμενο Ρ αποτελείται από το γράμμα Μ του προηγούμενου κώδικα των 27 χαρακτήρων που αντιστοιχεί στον ακέραιο αριθμό 13.
Τότε, το κρυπτογραφικό κείμενο C προκύπτει από τις παρακάτω πράξεις:
C = Pe modulo r = 1311 modulo 15 =
1.792.160.394.037 modulo 15 = 7
Τώρα, το αρχικό απλό κείμενο Ρ προκύπτει από τις πράξεις:
Ρ = Cd modulo r
= 73 modulo 15
= 343 modulo 15
= 13
Παράδειγμα 10.3
Παράδειγμα
Αποφυγής Πλαστογράφησης
Πώς οι μηχανισμοί κρυπτογράφησης με δημόσιο κλειδί επιτρέπουν τα κρυπτογραφημένα μηνύματα να είναι "υπογεγραμμένα", ώστε ο παραλήπτης να μπορεί να είναι βέβαιος ότι το μήνυμα προέρχεται από το άτομο που υποτίθεται ότι προέρχεται (δηλαδή, οι "υπογραφές" δεν μπορούν να πλαστογραφηθούν).
Λύση.
Έστω ότι οι αλγόριθμοι κρυπτογράφησης είναι οι ECA και ECB (για την κρυπτογράφηση των μηνυμάτων που θα στέλνονται στον Α και στον Β, αντίστοιχα)
Έστω ότι οι αντίστοιχοι αλγόριθμοι αποκρυπτογράφησης είναι οι DCA και DCB, αντίστοιχα.
Οι αλγόριθμοι ECA και DCA είναι αντίστροφοι μεταξύ τους, όπως και οι ECB και DCB.
Ο Α εφαρμόζει πρώτα τον αλγόριθμο αποκρυπτογράφησης DCA στο Ρ, και στη συνέχεια κρυπτογραφεί το αποτέλεσμα και το μεταδίδει ως κρυπτογραφικό κείμενο C:
C = ECB ( DCA ( P ) )
Μόλις πάρει το C, ο χρήστης Β εφαρμόζει τον αλγόριθμο αποκρυπτογράφησης DCB και στη συνέχεια τον αλγόριθμο κρυπτογράφησης ECA, ώστε να προκύψει το τελικό αποτέλεσμα Ρ:
ECA ( DCB ( C ) )
= ECA ( DCB ( ECB ( DCA ( Ρ ) ) ) )
= ECA ( DCA ( Ρ ) ) επειδή τα DCB και ECB αναιρούνται
= Ρ επειδή τα ECA και DCA αναιρούνται
Τώρα, ο Β ξέρει ότι το μήνυμα προέρχεται πραγματικά από τον
Α, επειδή ο αλγόριθμος ECA θα δώσει το Ρ μόνο αν χρησιμοποιήθηκε ο αλγόριθμος
DCA στη διαδικασία κρυπτογράφησης, και αυτός ο αλγόριθμος είναι γνωστός μόνο
στον Α. Κανένας, ούτε ακόμα και ο Β, δεν μπορεί να πλαστογραφήσει την υπογραφή
του Α.
Κεφάλαιο 11. XML
(Extensible
Markup Language)
Η γλώσσα XML
(Extensible Markup Language)
είναι μια γλώσσα για έγγραφα που περιέχουν δομημένες πληροφορίες. Είναι
εύχρηστη στο Internet,
υποστηρίζει μεγάλη ποικιλία από εφαρμογές, και είναι εύκολη στον
σχεδιασμό. Στο κεφάλαιο αυτό
παρουσιάζονται οι εντολές της XML,
η διαχείριση των XML
δεδομένων με τεχνικές βάσεων δεδομένων καθώς και η ανταλλαγή μορφοποιημένων
δεδομένων από RDBMS ως XML έγγραφα.
Με την τεράστια εξάπλωση του παγκόσμιου ιστού, η ανάγκη για ανταλλαγή δεδομένων μεταξύ διαφορετικών συστημάτων και πλατφορμών έγινε επιτακτική . Το κύριο πρόβλημα είναι ότι η μορφή και ο τύπος των δεδομένων ποικίλλει. Μπορεί να είναι αρχεία κειμένου, δεδομένα βάσεων δεδομένων, μεταδεδομένα κτλ. . Επιτακτική ανάγκη για ένα κοινό πρότυπο αναπαράστασης και ανταλλαγής δεδομένων, κοινό για όλες τις πλατφόρμες
Ηανάπτυξη του XML (eXtensive Markup Language) ξεκίνησε το
1996 και το 1998 εντάχθηκε στο W3C . Βασίζεται στην SGML (Standard Generalized Markup Language) και είναι ένα υποσύνολό
της. Διατήρησε τα λειτουργικά χαρακτηριστικά της, αλλά απέβαλε τα στοιχεία
εκείνα που την έκαναν δύσχρηση στο προγραμματισμό . Ραγδαία εξάπλωση τα
τελευταία χρόνια, ανάλογη με αυτή του παγκοσμίου ιστού
H XML ονομάστηκε έτσι από τα αρχικά των eXtensive Markup
Language. . Είναι ένα σύνολο από κανόνες για τη δημιουργία ετικετών (tags) που
περιγράφουν τα δεδομένα ενός εγγράφου καθώς και προσδιορίζουν και τα διάφορα
μέρη από τα οποία αποτελείται ένα έγγραφο. . Είναι μια μεταγλώσσα, με την οποία
μπορούμε να ορίσουμε άλλες γλώσσες σήμανσης.
Με την XML μπορεί κάποιος να δημιουργήσει ένα σύνολο από ετικέτες που
επιθυμεί να χρησιμοποιήσει όπως αυτός επιθυμεί.
ΠΛΕΟΝΕΚΤΗΜΑΤΑ ΤΗΣ XML. Κοινό πρότυπο μεταξύ διαφορετικών
πλατφορμών . Αυτο-περιγραφική γλώσσα . Αποθήκευση σε ASCII κείμενο . Ευελιξία
στη δομή καθώς ο καθένας δημιουργεί όσες και όποιες ετικέτες θέλει .
Ευανάγνωστα αρχεία . Πληθώρα τεχνολογιών και εργαλείων . Οι περισσότερες
εφαρμογές υποστηρίζουν την εξαγωγή και εισαγωγή στοιχείων από έγγραφα XML
ΧΡΗΣΗ ΤΗΣ XML . Επιχειρηματικά δεδομένα (πωλήσεις, τιμολόγια,
παραγγελίες) . Στοιχεία από βάσεις δεδομένων (όλα τα σύγχρονα RDBMS
υποστηρίζουν εξαγωγή και εισαγωγή από XML) . Δημιουργία γλωσσών σήμανσης
σχετικά με έναν τομέα . Οικονομικά δεδομένα (οικονομικές και λογιστικές
εφαρμογές) . Human Resources XML (HR-XML)
ΧΑΡΑΚΤΗΡΙΣΤΙΚΑ ΤΗΣ XML. Υπάρχουν κάποια χαρακτηριστικά, τα
οποία βοήθησαν στην ραγδαία εξάπλωση της XML, λόγω της ευκολίας χρήσης της . Τα
χαρακτηριστικά αυτά είναι: .
- Δεν
κάνει υπόθεση για τον τρόπο παρουσίασης των εγγράφων .
- Δεν
ορίζονται τύποι στα δεδομένα της .
- Δεν
υπάρχει περιορισμός στον τρόπο μετάδοσης των XML εγγράφων
11.3
Τρόπος Παρουσίασης Δεδομένων
Η XML περιγράφει μόνο τη δομή και το περιεχόμενο των δεδομένων και όχι τον τρόπο παρουσίασης τους. Αντίθετα η HTML περιγράφει τον τρόπο παρουσίασης κάποιων δεδομένων. Οι ετικέτες του εγγράφου συνήθως σχετίζονται με την οντότητα στην οποία αναφέρονται. Οι σημαντικότερες αλλαγές που επέφερε η XML είναι αλλαγές στα Δεδομένα, στην Αρχιτεκτονική, στο Λογισμικό .
Δεδομένα: Αποδέσμευση των δεδομένων από τις εφαρμογές. Δημιουργία επιχειρηματικών λεξικών. Ανάπτυξη της Β2Β επικοινωνίας .
Αρχιτεκτονική:. Ανάπτυξη κατανεμημένων υπολογιστικών συστημάτων. Χρήση της XML και του διαδικτύου (TCP/IP) για επικοινωνία και ανταλλαγή δεδομένων και πληροφοριών .
Λογισμικό: Με τη χρήση της XML επεκτείνεται η δυνατότητα επικοινωνίας διαφόρων υποπρογραμμάτων και εφαρμογών μεταξύ τους . Προγράμματα βασισμένα σε modules για τη λύση συγκεκριμένων προβλημάτων. Υπάρχει απλότητα και ευελιξία στον κώδικα.
Ένα XML έγγραφο μοιάζει με ένα HTML έγγραφο. Αποτελείται από
tags, τα οποία είναι υποχρεωτικό να κλείνονται (σε αντίθεση με την HTML).
Π.χ <ΟΝΟΜΑ> ΓΙΑΝΝΗΣ </ΟΝΟΜΑ>
Επιτρέπονται άπειρα επίπεδα εμφωλευμένων tags . Απαγορεύεται όμως οι ετικέτες αυτές να ξεκινούν με τη λέξη ‘XML’ είτε σε πεζά είτε σε κεφαλαία.
Σε αυτήν την παράγραφο θα
παραθέσουμε τα δομικά στοιχεία της γλώσσας XML έτσι ώστε να διευκολύνουμε την κατανόηση της διαδικασίας της
μετατροπής των οντοτήτων σε κώδικα γραφής XML.
Element: To βασικό δομικό στοιχείο ενός XML εγγράφου
<book> XML Language </book> .
Attribute: Ιδιότητα ενός element
<book
author=“John”> XML Language </book>
Τα attributes
μπορούν να γραφούν και με τη μορφή εμφωλευμένων elements. Π.χ
<book>
<author> John </author>
<title> XML Language </title>
</book>
Η χρήση attributes κάνει το έγγραφο πιο δυσανάγνωστο και συνήθως αποφεύγεται.
Entity: Οι οντότητες είναι αφλαριθμητικά που χρησιμοποιούνται ως συντομογραφίες άλλων αλφαριθμητικών. <!Entity message “Welcome”> Με αυτόν τον τρόπο, όταν γράφουμε &message θα ισοδυναμεί με “Welcome”
11.3.2
DTD (Document Type Definition)
Ο ορισμός των ετικετών που θα χρησιμοποιηθούν είναι
προαιρετικός και γίνεται μέσω του σχήματος DTD (Document Type Definition) . Ένα
DTD αρχείο περιέχει ένα λεξικό για κάποια συγκεκριμένα XML έγγραφα. Στο DTD
αρχείο ορίζονται ποιες ετικέτες θα χρησιμοποιηθούν καθώς και οι σχέσεις μεταξύ
ετικετών (π.χ ποιες περιέχουν ποιες κτλ).
11.13.3 Παρουσίαση XML Εγγράφων.
H XML δεν ορίζει τον τρόπο με τον οποίο θα παρουσιαστούν τα δεδομένα που περιγράφει . Για την παρουσίαση, χρησιμοποιούνται άλλες γλώσσες ή εργαλεία όπως: CSS (Cascading Style Sheets) , XSL (eXtensive Style sheets Language), XForms.
Τα μειονεκτήματα που παρουσιάζουν τα CSS είναι καταρχήν ότι απαιτείται DTD. Επίσης εξαρτάται από τον browser για την παρουσίαση του στυλ του εγγράφου. Τα πλεονεκτήματα που παρουσιάζουν τα φύλλα XSL είναι ότι γίνεται αλαγή στη σειρά εμφάνισης των στοιχείων και είναι ανεξάρτητα από το browser που παρουσιάζει τις πληροφορίες. Περισσότερες λειτουργίες και δυνατότητες επιτυγχάνονται με τα XForms. Στα XForms γίνεται αντικατάσταση των HTML φορμών και επιτυγχάνεται διαχωρισμός εμφάνισης και λειτουργικότητας, δίνοντας το τελικό αποτέλεσμα σε XML
Καταρχάς ακολουθούμε μια ιεραρχική δομή μέσα στην οποία δηλώνουμε το βασικό στοιχείο με τις ετικέτες σήμανσης για να επιτύχουμε τις διαδικασίες αναζήτησης και επεξεργασίας των δεδομένων που μας αφορούν.
Υπάρχουν κάποιοι σημαντικοί περιορισμοί όπως :
- Ξεκινάμε
με τον πρόλογο του εγγράφου στον οποίο δηλώνεται ο ορισμός τύπου εγγράφου
(document type
declaration, DTD)
ο οποίος καθορίζει τη δομή του εγγράφου. Η δήλωση έχει τη μορφή :
<!DOCTYPE Όνομα DTD>
όπου Όνομα DTD είναι το όνομα του στοιχείου εγγράφου.
- μέσα στο στοιχείο εγγράφου δηλώνουμε τους τύπους των στοιχείων που το αποτελούν. Η δήλωση γίνεται ως εξής:
<!ELEMENT
Όνομα contentspec>
όπου Όνομα είναι το όνομα του τύπου στοιχείου και contentspec είναι η προδιαγραφή περιεχομένου που καθορίζει τι ακριβώς περιέχει το στοιχείο.
- Υπάρχουν όμως και ιδιότητες που μπορούμε να ενσωματώσουμε σε ένα τύπο εγγράφου DTD οι οποίες προσδίδουν κάποια ιδιαίτερα χαρακτηριστικά στον εκάστοτε τύπο στοιχείου στον οποίο ανήκουν. Για να δηλώσουμε μια λίστα ιδιοτήτων ακολουθούμε την εξής γενική σύνταξη:
<!ATTLIST Ονομα
AttDefs>
το Όνομα χαρακτηρίζει το όνομα του στοιχείου που σχετίζεται με την ιδιότητα και AttDefs είναι το σύνολο από έναν ή περισσότερους περιορισμούς που αφορούν την ιδιότητα. Τώρα η δήλωση του ορισμού μιας ιδιότητας έχει τη μορφή Όνομα AttType DefaultDecl, όπου Όνομα είναι τώρα το όνομα της ιδιότητας, ο AttType αναφέρεται στο τύπο της ιδιότητας και η DefaultDecl είναι η δήλωση προεπιλογής που μας δείχνει αν η ιδιότητα είναι απαραίτητη καθώς και άλλες πληροφορίες .
- Σύμφωνα με τη δομή του DTD δημιουργούμε το υπόλοιπο έγγραφο.
- Θα πρέπει να επισημάνουμε κάποιους κανόνες σύνταξης της γλώσσας XML για την αποφυγή λαθών. Aυτοί είναι οι παρακάτω:
- To έγγραφο πρέπει να περιέχει ένα μόνο στοιχείο ανωτάτου επιπέδου που είναι το στοιχείο εγγράφου ή το βασικό στοιχείο.
- Η
ένθεση των στοιχείων γίνεται με τη σειρά .Αφού τελειώσει το ένα στοιχείο
ορίζεται το επόμενο.
- Η
ετικέτα αρχής και τέλους έχει ακριβώς το ίδιο όνομα.
- Γίνεται διάκριση κεφαλαίων και πεζών χαρακτήρων.
Οι οντότητες ταξινομούνται σε διάφορες κατηγορίες ανάλογα με τη λειτουργία που ζητούνται να επιτελέσουν κάθε φορά. Έτσι διακρίνονται στις :
- Γενικές (general) και παραμέτρων (parameter).
- Εσωτερικές (internal) και εξωτερικές (external).
- Αναλυόμενες (parsed) και μη αναλυόμενες (unparsed).
Στην Εικόνα 11.1 φαίνεται το το μονοπάτι που ακολουθείται στη διάταξη των οντοτήτων :
Εικόνα 11.1 Μονοπάτι διάταξης οντοτήτων
Έχουμε 5 τύπους οντοτήτων
όπως μπορούμε να διαπιστώσουμε και από το παραπάνω σχήμα:
· Γενική εσωτερική, αναλυόμενη οντότητα.
· Γενική εξωτερική, αναλυόμενη οντότητα.
· Γενική εξωτερική, μη αναλυόμενη οντότητα.
· Εσωτερική αναλυόμενη οντότητα, παραμέτρου.
· Εξωτερική αναλυόμενη οντότητα, παραμέτρου.
Να δούμε τη μορφή των δηλώσεων για κάθε τύπο ξεχωριστά.
1.Γενική εσωτερική, αναλυόμενη οντότητα
Δήλωση
<!ENTITY EntityName EntityValue>
2.Γενική εξωτερική, αναλυόμενη οντότητα
Δήλωση
<!ENTITY EntityName SYSTEM SystemLeteral >
3.Γενική εξωτερική οντότητα, μη
αναλυόμενη
Δήλωση
<!ENTITY EntityName SYSTEM SystemLeteral NDATA NotationName>
4.Εσωτερική αναλυόμενη οντότητα,
παραμέτρου
Δήλωση
<!ENTITY % EntityName EntityValue>
5.Εξωτερική αναλυόμενη οντότητα, παραμέτρου
Δήλωση
<!ENTITY % EntityName SYSTEM SystemLeteral >
Στον πίνακα που ακολουθεί δίνονται οι έννοιες που περιλαμβάνονται στις δηλώσεις .
|
EntityName |
Είναι το όνομα τη οντότητας. |
|
EntityValue |
Είναι η τιμή της οντότητας. |
|
SYSTEM |
Είναι δεσμευμένη λέξη που αναφέρεται για να προετοιμάσει την υποδοχή της θέσης του αρχείου που ακολουθεί. |
|
SystemLeteral |
Καθορίζει το URI που είναι μια τυπική διεύθυνση Internet. Με απλά λόγια προσδιορίζει μια τοποθεσία σχετική με τη θέση του εγγράφου XML που περιέχει το URI. |
|
NDATA |
Είναι λέξη-κλειδί που δείχνει ότι το αρχείο της οντότητας περιέχει μη-αναλυόμενα δεδομένα. |
|
NotationName |
Είναι το όνομα της σημειογραφίας που δηλώνετε στο DTD. |
|
% |
Μορφή αναφοράς οντότητας παραμέτρου |
Πίνακας 11.1 Τύποι οντοτήτων
Σε αυτό το σημείο θα πρέπει να κάνουμε μια αναφορά στην έννοια της σημειογραφίας που αναφέρεται παραπάνω.
Η δήλωση της σημειογραφίας είναι η εξής:
<!NOTATION NotationName SYSTEM SystemLiteral>
όπου NotationName περιγράφει το όνομα της συγκεκριμένη σημειογραφίας, και το SystemLiteral αποτελεί ένα URL είτε είναι κάποιου προγράμματος είτε ενός ηλεκτρονικού εγγράφου είτε μια απλή περιγραφή ενός εγγράφου.
Θα πρέπει να ξεκαθαρίσουμε ότι ο επεξεργαστής XML μεταβιβάζει στην εφαρμογή τις πληροφορίες της σημειογραφίας.
Ακολουθούν μερικά παραδείγματα των τύπων οντοτήτων ώστε να κατανοήσουμε τον τρόπο λειτουργίας τους. Κάθε τύπος οντότητας δηλώνεται στο DTD του εγγράφου.
Πως μπορεί να γραφεί σε XML τα στοιχεία της βάσης δεδομένων ΒΙΒΛΙΟΘΗΚΗ που έχει τους παρακάτω πίνακες.
ΒΙΒΛΙΑ
|
ΙSBN |
ΤΙΤΛΟΣ |
ΣΥΓΓΡΑΦΕΑΣ |
|
0-07-228363-7 |
Συστήματα Βάσεων Δεδομένων |
Korth,Silberschatz |
ΑΡΘΡΑ
|
ΚΩΔ |
ΤΙΤΛΟΣ |
ΣΥΓΓΡΑΦΕΑΣ |
ΕΚΔΟΣΗ |
|
15-15-1001 |
Storing and
Querying XML |
FLorescou,
Kossman |
IEE Data,
1999 |
Λύση
<ΒΙΒΛΙΟΘΗΚΗ>
<ΒΙΒΛΙΑ>
<ISBN> 0-07-228363-7 </ISBN>
<ΤΙΤΛΟΣ> Συστήματα Βάσεων Δεδομένων </ΤΙΤΛΟΣ>
<ΣΥΓΓΡΑΦΕΑΣ> Korth,Silberschatz </ ΣΥΓΓΡΑΦΕΑΣ>
</ΒΙΒΛΙΑ>
<ΑΡΘΡΑ>
<ΚΩΔ> 15-15-1001 </ΚΩΔ>
<ΤΙΤΛΟΣ> Storing and Querying XML </ΤΙΤΛΟΣ>
<ΣΥΓΓΡΑΦΕΑΣ> FLorescou, Kossman </ ΣΥΓΓΡΑΦΕΑΣ>
<ΕΚΔΟΣΗ> IEE Data, 1999 </ΕΚΔΟΣΗ>
</ΑΡΘΡΑ>
</ΒΙΒΛΙΟΘΗΚΗ>
Έστω ότι έχουμε την οντότητα client(πελάτης) με γνωρίσματα code(κωδικός), name(όνομα), thl(τηλέφωνο).

Ορίστε μια γενική εσωτερική αναλυόμενη οντότητα στο DTD που ακολουθεί με την ονομασία client.
Λύση
<!DOCTYPE CLIENTS
[
<!ELEMENT CLIENTS (CODE,NAME,THL)*>
<!ELEMENT CODE ( #PCDATA)>
<!ELEMENT NAME (#PCDATA)>
<!ELEMENT THL (#PCDATA)>
<!ENTITY CLIENTS
“1234”
“ΙΟΑΝΝΙΔΗΣ ΣΩΤΗΡΗΣ”
“2321055555” >
]
>
Η οντότητα CLIENTS περιέχει δεδομένα χαρακτήρων τα οποία δηλώνονται με το μοντέλο περιεχομένου #PCDATA(parsed character data-αναλυμένα δεδομένα χαρακτήρων). Το όνομα του DTD συμπίπτει με το όνομα της οντότητας. Αυτό μη σας προβληματίζει διότι δεσμεύουν διαφορετικούς χώρους ονομάτων. Το σύμβολο * στο τέλος της παρένθεσης υποδηλώνει ότι τα γνωρίσματα (στοιχεία) της οντότητας μπορούν να επαναληφθούν καμία ή περισσότερες φορές. Συνεπώς μπορούμε να δηλώσουμε για παράδειγμα δύο αριθμούς τηλεφώνου ή και κανένα.
11.5 Εμφάνιση της xml στον ιστό
Ξεκινώντας τον πρόλογο ενός εγγράφου xml οι βασικές εντολές σύνταξης είναι οι ακόλουθες:
<? xml version=”1.0”?>
<! -- File Name : School.xml -- >
Στην πρώτη γραμμή έχουμε τη δήλωση xml στην οποία ενημερώνουμε στον μεταγλωττιστή ότι θα ακολουθήσει ένα έγγραφο xml και αναφέρουμε τον αριθμό της έκδοσης της .Η επόμενη γραμμή είναι κενή για να είναι ευανάγνωστο το έγγραφο, είναι προαιρετική και μπορούμε να προσθέσουμε όσες εμείς επιθυμούμε. Τέλος, η γραμμή εισάγει κάποιο σχόλιο στο έγγραφο, το οποίο είναι και αυτό προαιρετικό με τη σειρά του και είναι συνήθως τακτική του συντάκτη ώστε να διευκολυνθεί στην ανάγνωση του εγγράφου.
Η διάθεση του εγγράφου xml σε μια εφαρμογή όπως είναι ο Internet Explorer γίνετε μέσω κάποιας εντολής επεξεργασίας. Η σύνδεση ενός φύλλου στυλ μέσα στο έγγραφο xml δηλώνετε στο τέλος του προλόγου του εγγράφου. Έτσι ο επεξεργαστής xml διαβάζει το έγγραφο και μέσω μιας εφαρμογής επιτυγχάνουμε την προσπέλαση των δεδομένων του όπως ακριβώς αυτά περιγράφονται στο CSS. Για παράδειγμα γράφοντας την παρακάτω εντολή επεξεργασίας προσθέτουμε ένα φύλλο στυλ στο έγγραφό μας:
<? xml
–stylesheet type =”text/css” href=”Student.css”?>
Σε περίπτωση που δεν εισαγάγουμε κάποιο φύλλο στυλ, η εφαρμογή θα μας εμφανίσει απλά το έγγραφο αυτούσιο όπως ακριβώς το έχουμε γράψει στον κειμενογράφο μας, με τη διαφορά ότι θα το έχει κωδικοποιήσει χρωματίζοντας διαφορετικά κάθε μέρος του εγγράφου.
Ένα ενδιαφέρον ζήτημα είναι η εντόπιση των σφαλμάτων από τον ενσωματωμένο αναλυτή της xml. Ο αναλυτής λοιπόν ελέγχει τα δεδομένα του εγγράφου, τη συντακτική δομή και σε συνεργασία με την εφαρμογή δεν εμφανίζει το έγγραφο όπως θα αναμέναμε, αλλά παρουσιάζει μια σελίδα σφάλματος ανεξαρτήτως της ύπαρξης του φύλλου στυλ. Θα πρέπει να ξεκαθαρίσουμε όμως ότι ο αναλυτής δεν ελέγχει αν το συγκεκριμένο έγγραφο xml είναι έγκυρο.
Παρακάτω θα δείξουμε ένα παράδειγμα σε συνδυασμό με ένα φύλλο στυλ καθώς και πώς αυτό θα εμφανιστεί έπειτα, χρησιμοποιώντας την εφαρμογή Internet Explorer.
Έστω ότι έχουμε μια βάση δεδομένων με όνομα School που περιέχει την οντότητα Students( μαθητές ), με τα εξής γνωρίσματα:
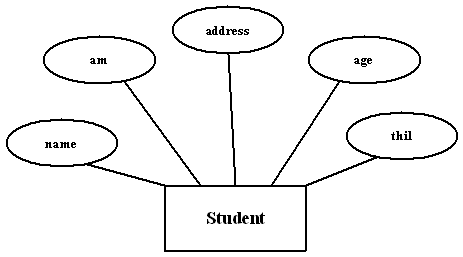
Μετατρέψτε τον παραπάνω πίνακα δεδομένων σε κώδικα xml και να εμφανίζεται με ένα συγκεκριμένο στυλ από το αρχείο school.css.
Λύση
Θα τη μετατρέψουμε σε κώδικα xml ως εξής:
1.Δημιουργούμε
το έγγραφο xml μέσα σε
έναν κειμενογράφο π.χ στο σημειωματάριο, το οποίο θα αποτελείται από τον
πρόλογο και το βασικό στοιχείο. Έχουμε λοιπόν:
Student.xml
<? xml version=”1.0”?>
<!
-- File Name : Student.xml -- >
<? xml
–stylesheet type =”text/css” href=”Student.css”?>
<School>
<Student>
<am>
1234</am>
<name>
PAPAS NIKOS </name>
<address>
Delfon 13 </address>
<age>
21 </age>
<thl> 2321099999 </thl>
</Student>
<Student>
<am> …</am>
<name>
… </name>
<address> … </address>
<age> … </age>
<thl> ….. </thl>
</Student>
</School>
11.6
Τρόποι εμφάνισης εγγράφων XML
Μπορούμε να εμφανίσουμε κάποιο έγγραφο xml σε ένα φυλλομετρητή ιστού χρησιμοποιώντας διάφορους τρόπους. Εμείς σε αυτήν την παράγραφο θα επικεντρωθούμε σε μια μέθοδο που είναι τα φύλλα επάλληλων στυλ( CSS ).
Σύμφωνα με τη μέθοδο αυτή δημιουργούμε σε κάποιο διορθωτή κειμένου το CSS δηλαδή ένα φύλλο το οποίο θα περιέχει την μορφοποίηση που επιθυμούμε να εφαρμοστεί στα δεδομένα χαρακτήρων των στοιχείων και το αποθηκεύουμε με το όνομα του εγγράφου χρησιμοποιώντας την επέκταση .css.
Για να συνδέσουμε το CSS με το έγγραφο xml συντάσσουμε την κατάλληλη εντολή επεξεργασίας, η οποία καθιστά δυνατή την εμφάνιση του περιεχομένου του εγγράφου σε κάποιο φυλλομετρητή ιστού.
Η εντολή επεξεργασίας η οποία μπορεί να προστεθεί στο τέλος του προλόγου του εγγράφου είναι η παρακάτω:
<? xml-stylesheet type=”text/css” href=”όνομα_εγγράφου.css”?>
Να σημειώσουμε ότι αν δεν ενσωματώσουμε στο έγγραφο xml ένα φύλλο επάλληλων στυλ τότε όταν θα το εμφανίσουμε στον Internet Explorer αυτός θα μας παρουσιάσει το πλήρες έγγραφο μαζί με τη σήμανση(όπως ετικέτες, σχόλια) και τα στοιχεία χαρακτήρων αφού πρώτα κωδικοποιήσει χρωματίζοντας τα διάφορα μέρη του εγγράφου, δίνοντας μια εύκολα αναγνώσιμη μορφή στο έγγραφο.
Ας δούμε ένα απλό παράδειγμα κατασκευής CSS και να αναλύσουμε τα συστατικά του μέρη.
/* File Name: όνομα_εγγράφου.css */
όνομα_στοιχείου
{
display:block;
margin-top:12pt;
font-size:10pt;
font-style:italic;
font-weight:bold;
}
Λύση
Ξεκινάμε με ένα σχόλιο στο οποίο αναφέρουμε το όνομα του εγγράφου με το οποίο θα το αποθηκεύσουμε. Έπειτα παραθέτουμε το στοιχείο του εγγράφου(εδώ χάριν απλότητας αναφέρουμε μόνο ένα στοιχείο) με τους κανόνες που θέλουμε να ακολουθήσουν κατά την εμφάνιση του στοιχείου αυτού στον Internet Explorer.
Όπως παρατηρούμε οι κανόνες αυτοί περιέχονται μέσα σε άγκιστρα και διαχωρίζονται μεταξύ τους με ελληνικό ερωτηματικό.
Ο πρώτος κανόνας λέει να εμφανιστεί κάθε στοιχείο με περιθώριο 12 στιγμών από πάνω(margin-top:12pt) και με μια αλλαγή γραμμής πάνω και κάτω(display:block) σε γραμματοσειρά 10 στιγμών (font-size:10pt) όπου να εμφανίζεται με έντονους(font-weight:bold) και πλάγιους χαρακτήρες(font-style:italic).
Παράδειγμα 11.5
Πως ορίζεται ένα XML έγγραφο μέσω σχήματος DTD;
Λύση
<?xml
version="1.0"?>
<!DOCTYPE
note [
<!ELEMENT note (to,from,heading,body)>
<!ELEMENT to (#PCDATA)>
<!ELEMENT from (#PCDATA)>
<!ELEMENT heading (#PCDATA)>
<!ELEMENT body (#PCDATA)>
]>
<note>
<to>Tove</to>
<from>Jani</from>
<heading>Reminder</heading>
<body>Don't forget me this
weekend</body>
</note>
Κάθε XML έγγραφο μπορεί να θεωρηθεί ως μια πηγή πληροφορίας
και δεδομένων. Πρέπει να υποστηρίζονται πράξεις αναζήτησης πληροφορίας. Κάθε
XML έγγραφο μπορεί να θεωρηθεί ως ένα μη κατευθυνόμενο δέντρο
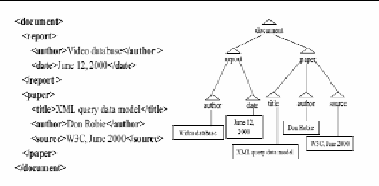
Οι λειτουργίες που θα πρέπει να υποστηρίζονται σε ένα XML έγγραφο είναι . Εύρεση σχέσης πατέρα-γιου . Εύρεση σχέσης πρόγονου – απόγονου . Έλεγχος τιμής χαρακτηριστικού . Καμία, μία ή περισσότερες εμφανίσεις ενός κόμβου. Twig patter matching. Ταίριασμα υποδέντρου
11.8.1
Γλώσσες XML Query.
Η XML Query 1.0 Συναντάει τους Κόσμους Βάσεων Δεδομένων και Εγγράφων. Η XML Query (XQuery) περιγράφει μια γλώσσα αναζήτησης βάσεων δεδομένων για δεδομένα XML.
"Η XQuery θα υπηρετήσει ως διεπαφή συνδυασμού πρόσβασης σε δεδομένα XML, όπως περίπου έκανε η SQL για συσχετισμένα δεδομένα," είπε ο Don Chamberlin από το IBM Almaden Research Center, συν-εφευρέτης της αρχικής γλώσσας SQL Query και ένας από τους συγγραφείς της XQuery 1.0. "Επειδή σχεδόν όλα τα είδη πληροφοριών μπορούν να αναπαρασταθούν χρησιμοποιώντας XML, περιμένω ότι η XQuery θα παίξει κεντρικό ρόλο στο συνδυασμό πληροφοριών από πολλούς διαφορετικούς πόρους. Εταιρείες από εύρος βιομηχανιών μπορούν να χρησιμοποιήσουν την XQuery για να φέρουν κοντά δομημένες και ημι-δομημένες πληροφορίες για επεξεργασία με ομοιόμορφο τρόπο."
Η Ομάδα Εργασίας XML Query κατηγοριοποίησε περισσότερες από σαράντα εφαρμογές της XQuery και ανέφερε πώς δεκατέσσερις από αυτές ικανοποιούν το σύνολο δοκιμών που αποτελείται από περισσότερες από 14.000 περιπτώσεις δοκιμών, επιδεικνύοντας άφταστα μέχρι πρότινος επίπεδα δια-λειτουργικότητας. Η XML Query είναι ήδη διαθέσιμη σε προϊόντα, από σχεσιακές βάσεις δεδομένων μέχρι τοπικά συστήματα βάσεων δεδομένων σε XML, middleware, συστήματα XML και σε πλήθος προϊόντων ανοιχτού κώδικα.
11.8.2 Αποθήκευση XML Εγγράφων.
Οι τρόποι αποθήκευσης των XML εγγράφων είναι απευθείας σε φυσικά αρχεία κειμένου. Ο τρόπος αυτός αν και μπορεί να αναγνωρισθεί και να προσπελασθεί σε οποιοδήποτε λειτουργικό σύστημα έχει το μειονέκτημα ότι παρουσιάζει αργή πρόσβαση στα δεδομένα. Η απουσία δομών δεικτοδότησης κάνουν την αποθήκευση απλή αλλά αργή. Σε αντίθεση με τις σχεσιακές βάσεις δεδομένων όπου υπάρχουν δομές ευρετηρίων για γρήγορη ανάκτηση των δεδομένων. Σε περίπτωση που ένα σχήμα XML μετατραπεί σε σχεσιακό θα πρέπει να γίνει μετατροπή σε πίνακες και στήλες. Στην συνέχεια με την επιβολή δομών δεικτοδότησης και με την χρήση της SQL για ερωτήσεις η ανάκτηση γίνεται ταχύτατα. Αυτό βέβαια προϋποθέτει την ύπαρξη ενός σχήματος DTD Schema και όχι ενός ελεύθερου XML αρχείου.
11.9 Χαρτογράφηση Σχήματος XML Σε Σχήμα Βάσης Δεδομένων.
Για να αποθηκευτεί ένα XML έγγραφο σε μια βάση δεδομένων, πρέπει το schema του να μετατραπεί σε ένα ανάλογο schema βάσης δεδομένων. Πρέπει να γίνει ο απαραίτητος διαχωρισμός elements, attributes και κειμένου. Δεν παίρνουμε υπόψιν την σειρά των elements και attributes . Τα είδη χαρτογράφησης που επικρατούν είναι : α. Βασισμένη σε πίνακα . β. Αντικειμενοστραφής
11.9.1 Χαρτογράφηση Βασισμένη Σε Πίνακα.
Μπορεί ένα XML έγγραφο να αποθηκευτεί είτε ως ένας πίνακας είτε ως πολλοί . Ανάλογα με το λογισμικό που χρησιμοποιείται, τα στοιχεία αποθηκεύονται είτε ως ξεχωριστοί πίνακες είτε ως στήλες ενός πίνακα. Απαιτείται το XML έγγραφο να έχει την εξής μορφή:
<database>
<table>
<row>Onoma</row>
<row>asd</row>
</table>
…
</database>Τα
α attributes αποθηκεύονται αυτόματα ως στήλες στους αντίστοιχους πίνακες . Το πλεονεκτήματα είναι η εύκολη υλοποίηση. Δεν απαιτείται DTD. Τα μειονεκτήματα που παρουσιάζονται ξεκινούν από το ότι δεν υποστηρίζονται όλα τα XML έγγραφα (πολλαπλές εμφωλεύσεις).
11.9.2 Αντικειμενοστραφής Χαρτογράφηση.
Χρησιμοποιείται από όλες τις σύγχρονες σχεσιακές βάσεις δεδομένων. Απαιτείται DTD σχήμα για την αναπαραγωγή του. Οι τύποι στοιχείων και οι ιδιότητές τους δημιουργούνται ως κλάσεις. Τα απλά στοιχεία (που έχουν μόνο τιμή κειμένου) διαμορφώνονται ως scalar ιδιότητες. Τέλος, οι κλάσεις αποθηκεύονται σε πίνακες και οι scalar ιδιότητες σε στήλες των αντίστοιχων πινάκων. Οι ιδιότητες χαρτογραφούνται σε ζευγάρια πρωτεύοντος/ξένου κλειδιού. Το πλεονέκτημα είναι ότι α. υποστηρίζονται όλα τα XML έγγραφα. β. Διατηρούνται οι ιδιότητες των πεδίων. γ. Μπορούμε να ανακτήσουμε το DTD σχήμα από το σχήμα της βάσης δεδομένων
Εξηγήστε την παρακάτω αντικειμενοστραφή χαρτογράφηση ενός XML εγγράφου.
DTD Σχήμα:
<!ELEMENT Order (OrderNum, Date, CustNum, Item*)>
<!ELEMENT OrderNum (#PCDATA)>
<!ELEMENT Date (#PCDATA)>
<!ELEMENT CustNum (#PCDATA)>
<!ELEMENT Item (ItemNum, Quantity, Part)>
<!ELEMENT ItemNum (#PCDATA)>
<!ELEMENT Quantity (#PCDATA)>
<!ELEMENT Part (PartNum, Price)>
<!ELEMENT PartNum (#PCDATA)>
<!ELEMENT Price (#PCDATA)>
Λύση
Βήμα 1 . Για κάθε σύνθετο στοιχείο, δημιουργείται ένας πίνακας και ένα αυτόματο πρωτεύον κλειδί . Π.χ Δημιουργία Πίνακων Order, Item, Part και των αντίστοιχων PK: OrderPK, ItemPK, PartPK .
Βήμα 2 . Για κάθε απλό στοιχείο δημιουργείται μια στήλη στον αντίστοιχο πίνακα. Π.χ Δημιουργία των στηλών. OrderNum, Date, CustNum (πίνακας Order) . ItemNum,Quantity (πίνακας Item) . PartNum, Price (πίνακας Part) .
Βήμα 3 . Παραγωγή ξένων κλειδιών για αναφορά στα σύνθετα στοιχεία . Π.χ Δημιουργία ξένου κλειδιού OrderFK (πίνακας Item), ItemFK (πίνακας Part)
11.10 Ερωτήσεις XMLσε Σχεσιακές Βάσεις Δεδομένων .
Για την επεξεργασία αποθηκευμένων XML εγγράφων υπάρχουν δύο τεχνικές. Χρήση SQL και μετατροπή των αποτελεσμάτων σε XML. Χρήση XML Query γλώσσας και μετατροπή της σε SQL statements .
Το ευρετήριο (index) είναι ένα αρχείο με εγγραφές, μία για κάθε εγγραφή δεδομένων. Κάθε εγγραφή του ευρετηρίου περιέχει την τιμή του κλειδιού κάθε εγγραφής και ένα δείκτη (pointer) που επιτρέπει άμεση προσπέλαση σ' αυτή την εγγραφή. Αυτό βέβαια προϋποθέτει ότι τα εξωτερικά μέσα, όπου είναι αποθηκευμένο το αρχείο, υποστηρίζουν τέτοιου είδους προσπέλαση. Τέτοια μέσα είναι οι δίσκοι και οι δισκέτες. Το ευρετήριο είναι ταξινομημένο (sorted) σύμφωνα με το χαρακτηριστικό κλειδί του αρχείου, για να γίνονται εύκολα οι αναζητήσεις, και είναι ανάλογο με το ευρετήριο ενός βιβλίου, που σχετίζει λέξεις και φράσεις με αριθμούς σελίδων. Στα ευρετήρια υπάρχουν διάφορες βελτιώσεις. Μία από αυτές είναι η δυνατότητα να κρατάμε μόνο την πρώτη λογική εγγραφή κάθε φυσικής εγγραφής. Έτσι δημιουργείται το ευρετήριο των φυσικών εγγραφών, με αριθμό εγγραφών = (αριθμό εγγραφών αρχείου) / (συντελεστή ομαδοποίησης). Για παράδειγμα, αν το αρχείο έχει n=1000 εγγραφές και συντελεστή ομαδοποίησης (blocking factor) b=10, το ευρετήριο θα έχει n/b=1000/10=100 εγγραφές. Τα πλεονεκτήματα των ευρετηρίων αυτών είναι το μικρότερο πλήθος εγγραφών και η γρήγορη προσπέλαση στις φυσικές εγγραφές. Οι μεμονωμένες εγγραφές μπορεί να προσπελασθούν εύκολα με αναζήτηση μέσα στις φυσικές εγγραφές. Έτσι οι λογικές εγγραφές του ευρετηρίου αποτελούν σημεία αναφοράς για τις φυσικές εγγραφές του αρχείου. Σε μία τέτοια οργάνωση δεν είναι δυνατό να προσδιοριστεί αν μία συγκεκριμένη εγγραφή βρίσκεται μέσα στο αρχείο. Πρέπει να εξεταστεί αν βρίσκεται μέσα στην αντίστοιχη φυσική εγγραφή. Αν νέες εγγραφές προστίθενται στο τέλος του αρχείου, είναι πιο εύχρηστο να κρατηθεί το κλειδί της τελευταίας, αντί της πρώτης, λογικής εγγραφής. Τα τελευταία φαίνονται στο σχήμα
Η μεγαλύτερη
διαφορά μεταξύ των διαφόρων μεθόδων οργάνωσης διαδοχικών αρχείων με
ευρετήρια βρίσκεται στον τρόπο εισαγωγής
νέων εγγραφών. Είναι σπατάλη να υπάρχει ελεύθερος χώρος για κάθε πιθανή
εγγραφή, αλλά δεν είναι δυνατόν να ξαναγραφτεί το αρχείο για κάθε νέα εγγραφή.
Το πρόβλημα αυτό είναι γνωστό ως υπερχείλιση (overflow). Κάποιος χώρος αφήνεται
πάντα ελεύθερος, με σκοπό οι νέες εγγραφές να τοποθετούνται όσο το δυνατόν
πλησιέστερα στην σωστή τους θέση.
Οι Τύποι Ευρετηρίων που μπορεί να χρησιμοποιηθούν στις βάσεις δεδομένων μπορούν να χωριστούν στις παρακάτω μεγάλες κατηγορίες:
· Πρωτεύοντα Ευρετήρια
· Ευρετήρια Συστάδων
· Δευτερεύοντα Ευρετήρια
·
Ευρετήρια Πολλών Επιπέδων
12.1 Ευρετήρια σαν Μέθοδοι
Προσπέλασης
Ένα ευρετήριο ενός επιπέδου είναι ένα βοηθητικό αρχείο που κάνει πιο αποτελεσματική την αναζήτηση μιας εγγραφής σε ένα αρχείο δεδομένων. Το ευρετήριο συνήθως ορίζεται σε ένα πεδίο του αρχείου (αν και μπορεί να ορισθεί σε πολλά πεδία). Μια μορφή ευρετηρίου είναι ένα αρχείο με καταχωρήσεις <τιμή πεδίου, δείκτης στην εγγραφή>, που είναι ταξινομημένο με βάση την τιμή του πεδίου. Το ευρετήριο λέγεται αλλιώς και δρόμος προσπέλασης προς στο πεδίο. Το αρχείο του ευρετηρίου συνήθως καταλαμβάνει σημαντικά μικρότερο πλήθος μπλοκ από ότι το αρχείο δεδομένων επειδή οι καταχωρήσεις του είναι κατά πολύ μικρότερες. Μια δυαδική αναζήτηση στο ευρετήριο παράγει ένα δείκτη στην εγγραφή του αρχείου.
Τα ευρετήρια μπορούν επίσης να χαρακτηρισθούν σαν πυκνά ή αραιά
Ένα πυκνό ευρετήριο έχει μια καταχώρηση ευρετηρίου για κάθε αναζήτηση τιμής κλειδιού (και επομένως κάθε εγγραφή) στο αρχείο δεδομένων.
Ένα αραιό (ή μη πυκνό) ευρετήριο, από την άλλη, έχει καταχωρήσεις ευρετηρίου μόνο για κάποιες από τις τιμές αναζήτησης.
Τύποι Ευρετηρίων ενός Επιπέδου
Ορίζεται σε ένα ταξινομημένο αρχείο δεδομένων. Το αρχείο δεδομένων είναι ταξινομημένο σε ένα πεδίο κλειδί. Περιλαμβάνει μια καταχώρηση ευρετηρίου για κάθε μπλοκ στο αρχείο δεδομένων· η καταχώρηση ευρετηρίου έχει την τιμή του πεδίου κλειδιού για την πρώτη εγγραφή στο μπλοκ (Εικόνα 12.1), που ονομάζεται άγκυρα του μπλοκ. Ένα παρόμοιο σχήμα μπορεί να χρησιμοποιεί την τελευταία εγγραφή σε ένα μπλοκ.
Ένα πρωτεύον ευρετήριο είναι ένα μη πυκνό (αραιό) ευρετήριο, αφού έχει μια καταχώρηση για κάθε μπλοκ του αρχείου δεδομένων στο δίσκο και στα κλειδιά των εγγραφών άγκυρα παρά για κάθε τιμή αναζήτησης.

Εικόνα 12.1 Πρωτεύον ευρετήριο
Έστω ένα αρχείο με: rA = 10000 διατεταγμένες εγγραφές, σταθερού μεγέθους εγγραφής SA = 250 bytes, με μέγεθος block SB = 1024 bytes και με ολόκληρες πλειάδες σε κάθε block. Βρείτε τα block του αρχείου δεδομένων καθώς και του αρχείου ευρετηρίου.
Λύση
Σε κάθε block χωράνε SB/SA=4 πλειάδες
Μέγεθος αρχείου δεδομένων SF= 10000/4=2500 blocks
Κατασκευάζουμε το πρωτεύον ευρετήριο ως εξής:
Έστω ότι το μέγεθος του πεδίου κλειδιού είναι SK = 10 bytes
Και το μέγεθος δείκτη block P = 6 bytes
Σε κάθε block ευρετηρίου χωράνε [SB/(SK+P)]=[1024/16]=64 εγγραφές
Μέγεθος αρχείου ευρετηρίου SI=[2500/64]= 40 blocks
Κόστος αναζήτησης
Αν θεωρήσουμε ότι το αρχείο δεδομένων είναι διατεταγμένο ως προς το πεδίο αναζήτησης μπορούμε να εφαρμόσουμε δυαδική αναζήτηση.
Χωρίς το ευρετήριο:
Θα πρέπει να φορτώσουμε:log2(SF)
blocks = log2(2500)=11,28 à12 blocks αρχείου και να συγκρίνουμε τις πλειάδες.
Αν υπάρχει ευρετήριο: Θα πρέπει να φορτώσουμε:log2(SΙ)
blocks = log2(40)=5,32à 6 blocks ευρετηρίου και 1 block αρχείου (αυτό που θα μας υποδείξει η αναζήτηση στο ευρετήριο).
Χωρίς ευρετήριο: log2(2500)=12
Με ευρετήριο: log2(40)+1=7
Κόστος ενημέρωσης
Κατά την εισαγωγή εγγραφής σε πίνακα μιας βάσης δεδομένων με πρωτεύον ευρετήριο συνεπάγονται αλλαγές στο αρχείο άρα και στο ευρετήριο. Οι αλλαγές μπορούν να αποθηκεύονται σε ξεχωριστό αρχείο υπερχείλισης (χωρίς διάταξη) ή σε συνδεδεμένη λίστα εγγραφών υπερχείλισης και το ευρετήριο να ενημερώνεται περιοδικά.
Στην περίπτωση διαγραφής μιας εγγραφής συνεπάγονται ξανά αλλαγές στο ευρετήριο. Συνήθως η περίπτωση αυτή αντιμετωπίζεται με σημάδια διαγραφής στην συγκεκριμένη εγγραφή.
12.3 Ευρετήριο Συστάδων (Clustering Index)
Ορίζεται σε ένα ταξινομημένο αρχείο. Το αρχείο δεδομένων είναι ταξινομημένο σε ένα πεδίο που δεν είναι κλειδί, σε αντίθεση από το πρωτεύον ευρετήριο, που απαιτεί ότι το πεδίο ταξινόμησης στο αρχείο δεδομένων έχει μια διακριτή τιμή για κάθε εγγραφή.
Περιλαμβάνει μια καταχώρηση ευρετηρίου για κάθε διακριτή τιμή του πεδίου η καταχώρηση ευρετηρίου δείχνει στο πρώτο μπλοκ δεδομένων που περιέχει εγγραφές με αυτή την τιμή πεδίου όπως φαίνεται και στην Εικόνα 12.2. Είναι ένα ακόμη παράδειγμα μη πυκνού ευρετηρίου όπου η εισαγωγή και η διαγραφή είναι σχετικά εύκολη με ένα ευρετήριο συστάδα.
Έστω ένα αρχείο με: rA = 10000 διατεταγμένες εγγραφές, σταθερού μεγέθους SA = 250 bytes, μέγεθος block SB = 1024 bytes με μη εκτεινόμενη καταχώρηση (ολόκληρες πλειάδες σε κάθε block) Και 500 διαφορετικές τιμές στο πεδίο ευρετηρίασης με ομοιόμορφη κατανομή των πλειάδων σε αυτές. Βρείτε τα block του αρχείου δεδομένων καθώς και του αρχείου ευρετηρίου.
Λύση
Σε κάθε block χωράνε 1024/250= 4 πλειάδες
Μέγεθος αρχείου δεδομένων SF= 10000/4=2500 blocks
Κατασκευάζουμε ευρετήριο συστάδων (μη εκτεινόμενη καταχώρηση):
Έστω μέγεθος του πεδίου ευρετηρίασης είναι SK = 10 bytes
Μέγεθος δείκτη block P = 6 bytes
500 διαφορετικές τιμές στο πεδίο ευρετηρίασης με ομοιόμορφη κατανομή των πλειάδων σε αυτές
Σε κάθε block ευρετηρίου χωράνε όπως πριν 1024/16=64 εγγραφές
Μέγεθος αρχείου ευρετηρίου SI= 500/64 =7,8 à8 blocks
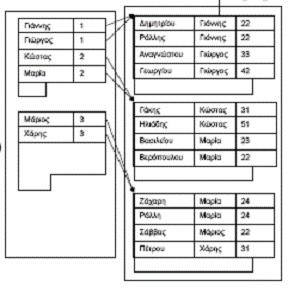
Εικόνα 12.2 Ευρετήριο Συστάδων
Κόστος αναζήτησης
Θεωρούμε ότι το αρχείο δεδομένων είναι διατεταγμένο ως προς το πεδίο αναζήτησης
μπορούμε να εφαρμόσουμε δυαδική αναζήτηση. Τα στοιχεία που έχουμε είναι: 500 διαφορετικές τιμές, 10000/500=20 πλειάδες με την ίδια τιμή πεδίου αναζήτησης
20/4=5 block αντιστοιχούν σε κάθε τιμή
Χωρίς το ευρετήριο: Θα πρέπει να φορτώσουμε
log2(SF) blocks = log2(2500)=11,28à 12 blocks αρχείου και 5 block για τις πλειάδες που έχουν την τιμή αναζήτησης
Αν υπάρχει ευρετήριο: Θα πρέπει να φορτώσουμε
log2(SΙ) blocks = log2(8)=5,32à 3 blocks ευρετηρίου και 5 block αρχείου (για τις πλειάδες που έχουν την τιμή αναζήτησης)
Χωρίς ευρετήριο: log2(2500)+5=17
Με ευρετήριο: log2(8)+5=8
Ένα δευτερεύον ευρετήριο υποστηρίζει ένα δευτερεύοντα τρόπο προσπέλασης ενός αρχείου για το οποίο υπάρχει ήδη πρωτεύουσα οργάνωση. Το δευτερεύον ευρετήριο μπορεί να είναι σε ένα πεδίο που είναι υποψήφιο κλειδί και έχει μοναδική τιμή σε κάθε εγγραφή, ή ένα πεδίο που δεν είναι κλειδί με πολλαπλές τιμές. Το ευρετήριο είναι ένα ταξινομημένο αρχείο με δύο πεδία. Το πρώτο πεδίο είναι ίδιου τύπου δεδομένων με κάποιο πεδίο που δεν είναι κλειδί του αρχείου δεδομένων και είναι το πεδίο ευρετηρίου.
Το δεύτερο πεδίο είναι δείκτης μπλοκ δείκτης εγγραφής . Μπορεί να υπάρχουν πολλά δευτερεύοντα ευρετήρια (και επομένως, πεδία ευρετηρίασης) για το ίδιο αρχείο. Περιλαμβάνει μια καταχώρηση για κάθε εγγραφή στο αρχείο δεδομένων· επομένως, είναι ένα πυκνό ευρετήριο.
Δευτερεύον κλειδί: Το πεδίο ευρετηρίασης είναι κλειδί αλλά όχι πεδίο διάταξης με μοναδικές τιμές. Το αρχείο περιέχει: rA = 10000 διατεταγμένες εγγραφές, σταθερού μεγέθους SA = 250 bytes, με μέγεθος block SB = 1024 bytes με μη εκτεινόμενη καταχώρηση (ολόκληρες πλειάδες σε κάθε block). Βρείτε τα block του αρχείου δεδομένων καθώς και του αρχείου ευρετηρίου.
Λύση
Σε κάθε block χωράνε 1024/250= 4 πλειάδες
Μέγεθος αρχείου δεδομένων SF= 10000/4=2500 blocks
Κατασκευάζουμε δευτερεύον ευρετήριο (μη εκτεινόμενη καταχώρηση):
Έστω μέγεθος του πεδίου ευρετηρίασης είναι SK = 10 bytes
Μέγεθος δείκτη block P = 6 bytes
Σε κάθε block ευρετηρίου χωράνε όπως πριν 1024/16=64 εγγραφές
Μέγεθος αρχείου ευρετηρίου SI= 10000/64 =156,25à157 blocks
Κόστος αναζήτησης
Αναζήτηση χωρίς ευρετήριο (σειριακή αναζήτηση, γιατί το αρχείο δεδομένων δεν είναι
ταξινομημένο): 2500/2 = 1250 blocks
Αναζήτηση με ευρετήριο: Δυαδική αναζήτηση στο δευτερεύον ευρετήριο
Ανάγνωση του block από το αρχείο δεδομένων
log 2(157)+ 1 = 9 blocks
12.5 Ευρετήρια Πολλών
Επιπέδων
Επειδή ένα ευρετήριο ενός επιπέδου είναι ένα ταξινομημένο αρχείο, μπορούμε να δημιουργήσουμε ένα πρωτεύον ευρετήριο στο ίδιο το ευρετήριο·
Στην περίπτωση αυτή, το αρχικό αρχείο ευρετηρίου ονομάζεται πρώτο επίπεδο ευρετηρίου και το ευρετήριο του ευρετηρίου ονομάζεται δεύτερο επίπεδο ευρετηρίου.
Μπορούμε να επαναλάβουμε τη διαδικασία αυτή, δημιουργώντας ένα τρίτο, τέταρτο ... επίπεδο, μέχρι που όλες οι καταχωρήσεις στο ψηλότερο επίπεδο να χωράνε σε ένα μπλοκ μνήμης.
Ένα ευρετήριο πολλών επιπέδων μπορεί να δημιουργηθεί οποιοδήποτε τύπο ευρετηρίου πρώτου επιπέδου (πρωτεύον, δευτερεύον, συστάδα) όσο το πρώτο επίπεδο ευρετηρίου αποτελείται από περισσότερα από ένα μπλοκ δίσκου.
Ένα τέτοιο ευρετήριο πολλών επιπέδων είναι μια μορφή δένδρου αναζήτησης. Ωστόσο, η εισαγωγή και η διαγραφή καταχωρήσεων στο ευρετήριο αποτελεί σοβαρό πρόβλημα επειδή κάθε επίπεδο του ευρετηρίου είναι ένα ταξινομημένο αρχείο.
Τα περισσότερα ευρετήρια πολλών επιπέδων χρησιμοποιούν δομές δεδομένων B-δένδρων ή B+ δένδρων λόγω του προβλήματος εισαγωγής και διαγραφής. Αυτό αφήνει σε κάθε κόμβο του δένδρου (μπλοκ στο δίσκο) ελεύθερο χώρο για νέες καταχωρήσεις. Αυτές οι δομές δεδομένων αποτελούν παραλλαγές των δένδρων αναζήτησης που υποστηρίζουν αποτελεσματική εισαγωγή και διαγραφή νέων τιμών αναζήτησης
Στις δομές δεδομένων B-δένδρων και B+-δένδρων, κάθε κόμβος αντιστοιχεί σε ένα μπλοκ του δίσκου. Κάθε κόμβος είναι από γεμάτος ή μέχρι τη μέση. Περισσότερα για τα δένδρα θα αναφέρουμε στο επόμενο κεφάλαιο.
Δομές Δεδομένων
Τα δεδομένα που χρησιμοποιεί ένα πρόγραμμα
οργανώνονται με συγκεκριμένους τρόπους ώστε να διευκολύνεται η χρήση τους και η
αποδοτικότητα των αλγορίθμων που τα χρησιμοποιούν. Οι τρόποι αυτοί ονομάζονται
δομές δεδομένων (data structures).
Οι βασικές δομές δεδομένων είναι
οι εξής:
·
Στίβα (stack)
·
Ουρά (queue)
·
Ουρά προτεραιότητας (priority queue)
·
Λίστα (list)
·
Δέντρο (tree)
·
Σύνολο (set)
·
Σάκος (bag, multiset)
·
Απεικόνιση (map)
·
Γράφος (graph)
Οι δομές δεδομένων
(data structures) είναι τύποι αντικειμένων που μπορούν να χρησιμοποιηθούν σε
αλγόριθμους για την επίλυση προβλημάτων. Συγκεκριμένα, στις δομές δεδομένων
τοποθετούνται τα δεδομένα του προβλήματος. Επίσης, για κάθε δομή δεδομένων
ορίζεται ένα σύνολο πράξεων που μπορούν να εφαρμοστούν. Έτσι, η επίλυση του
προβλήματος επιτυγχάνεται με την τοποθέτηση των δεδομένων στην κατάλληλη δομή
δεδομένων και την εφαρμογή των αντίστοιχων πράξεων σε αυτή.
Οι δομές δεδομένων χρησιμοποιούνται επειδή
επιτρέπουν την προσπέλαση και επεξεργασία δεδομένων με εύκολο τρόπο. Κάθε δομή
δεδομένων και οι πράξεις της παρουσιάζουν ιδιαίτερα χαρακτηριστικά. Η καταλληλότητα
μιας δομής δεδομένων για την επίλυση ενός προβλήματος εξαρτάται από τη φύση του
προβλήματος και τον χρησιμοποιούμενο αλγόριθμο επίλυσης.
Οι βασικές πράξεις
που εφαρμόζονται στις δομές δεδομένων είναι οι ακόλουθες:
·
Εισαγωγή
·
Διαγραφή
·
Αναζήτηση
·
Ταξινόμηση
·
Ενημέρωση
(συνήθως περιλαμβάνει διαδοχικά αναζήτηση-διαγραφή-εισαγωγή)
Ένας κύριος διαχωρισμός των δομών δεδομένων
είναι σε γραμμικές και μη γραμμικές:
- Γραμμικές:
Γραμμικές είναι οι
δομές εκείνες για τις οποίες μπορεί
να οριστεί διάταξη για δυο στοιχεία τους, δηλαδή κάποιο στοιχείο
είναι πρώτο και κάποιο τελευταίο, ενώ οποιοδήποτε από τα υπόλοιπα θα έχει
ένα προηγούμενο, από το οποίο έπεται και ένα επόμενο, από το οποίο
προηγείται. Χαρακτηριστικά είδη γραμμικών δομών είναι οι πίνακες, οι λίστες, οι στοίβες και οι ουρές
- Μη
γραμμικές: Στις μη γραμμικές δομές, οι σχέσεις
των δεδομένων είναι πιο περίπλοκες και όχι μονοδιάστατες. Κάθε στοιχείο
μιας τέτοιας δομής μπορεί να έχει πολλά επόμενα στοιχεία. Χαρακτηριστικό
είδος μη γραμμικής δομής είναι τα δέντρα.
Χωρικά δεδομένα (Spatial Data)
Ονομάζουμε τα
πολυδιάστατα δεδομένα με το γενικό όρο χωρικά
δεδομένα και τις αντίστοιχες βάσεις δεδομένων, που αποθηκεύουν χωρικά
δεδομένα, με τον όρο χωρικές βάσεις δεδομένων (ΧΒΔ).
|
|
|
|
(α) VLSI
δεδομένα |
(β)
Χαρτογραφικά δεδομένα |
Εικόνα 13.1: Παραδείγματα χωρικών βάσεων δεδομένων
Στα χωρικά δεδομένα ένα στοιχείο μπορεί να
είναι σημείο, γραμμή, πολύγωνο, ή να απαρτίζεται από πλήθος γραμμών ή
πολύγωνων. Γεωμετρία ονομάζεται ένα σύνολο από ένα ή περισσότερα
στοιχεία. Τα στοιχεία της γεωμετρίας δεν είναι απαραίτητο να είναι του ίδιου
τύπου, για παράδειγμα μπορείς να έχεις μια γεωμετρία που αποτελείται από σημεία
και πολύγωνα.
Τα ερωτήματα στις
χωρικές βάσεις δεδομένων συνήθως έχουν να κάνουν με τα χωρικά χαρακτηριστικά
των δεδομένων π.χ. τη θέση τους στο χώρο. Τυπικές χωρικές ερωτήσεις είναι οι
ακόλουθες:
· ερώτηση σημείου (point query): δοθέντος ενός σημείου p,
βρες όλα τα αντικείμενα που περιέχουν το p.
· ερώτηση περιοχής (range query): δοθέντος μιας ακτίνας r,
βρες όλα τα αντικείμενα με όλα τα αντικείμενα, που περικλείονται από την ακτίνα
r.
· ερώτηση κατεύθυνσης (direction query): δοθέντος ενός αντικειμένου o και μιας κατευθυντήριας σχέσης R (π.χ. βόρεια, αριστερά), βρες όλα τα αντικείμενα που βρίσκονται
στην κατεύθυνση R σχετικά με το o.
·
ερώτηση κοντινότερου γείτονα (Nearest Neighbor Query): δοθέντος ενός
αντικειμένου o, βρες όλα τα
αντικείμενα που απέχουν ελάχιστη απόσταση από το o.
Για την αποδοτική υποστήριξη των χωρικών δεδομένων και των χωρικών σχέσεων
έχουν προταθεί την τελευταία δεκαετία διάφορες επεκτάσεις στα μοντέλα
δεδομένων, τις γλώσσες ερωταποκρίσεων και τις δομές δεδομένων.
Τα δένδρα (trees) είναι δομές που εκφράζουν κόμβους δεδομένων με ιεραρχική διάταξη. Είναι
δομές δεδομένων στις οποίες κάθε στοιχείο, εκτός από ένα στοιχείο, τη ρίζα,
έχει έναν ακριβώς πρόδρομο. Επομένως ένα χαρακτηριστικό γνώρισμα των δένδρων
είναι ότι υπάρχει μία και μόνο διαδρομή από τη ρίζα προς ένα οποιαδήποτε
στοιχείο.
Τα δένδρα ονομάζονται και ιεραρχικές δομές δεδομένων, επειδή καθορίζουν σχέσεις
υπαγωγής των κατώτερων στα ανώτερα στοιχεία. Τα δένδρα είναι μια μαθηματική
αφαίρεση η οποία παίζει κεντρικό ρόλο στη σχεδίαση και την ανάλυση των αλγορίθμων
επειδή:
·
Χρησιμοποιούμε δένδρα για να περιγράψουμε τις δυναμικές ιδιότητες
των αλγορίθμων.
·
Κατασκευάζουμε και χρησιμοποιούμε ρητές δομές δεδομένων που
αποτελούν συμπαγείς υλοποιήσεις δένδρων.
Τα δένδρα απαντώνται συχνά τόσο
στην πληροφορική όσο και στην καθημερινή ζωή. Δομή δένδρου έχει ο πίνακας
περιεχομένων ενός βιβλίου, αλλά και το οργανόγραμμα μιας εταιρίας ή δημόσιας
υπηρεσίας, όταν κάθε υπάλληλος έχει ακριβώς ένα προϊστάμενο. Αλλά και όταν
αναλύουμε με το νου μας ένα αντικείμενο στα συστατικά του μέρη, παράγουμε
νοητικά ένα δένδρο.
Δένδρρο (Tree): Ένα δένδρο είναι ένα σύνολο από κόμβους (nodes) που ενώνονται με ακμές (edges) και εκπληρεί την ακόλουθη ιδιότητα: Αν ορίσουμε ως
μονοπάτι (path) ένα σύνολο
κόμβων ενωμένων με ακμές και ένα συγκεκριμένο κόμβο ως ρίζα (root) του δέδρου τότε κάθε άλλος κόμβος
ενώνεται με τη ρίζα με ένα και μόνο ένα μονοπάτι.
Στο πρώτο επίπεδο υπάρχει μόνο
ένας κόμβος, η ρίζα. Κάθε
κόμβος μπορεί να συνδέεται προς έναν ή περισσότερους κόμβους, τους κόμβους παιδιά του. Κάθε κόμβος έχει
μόνο έναν κόμβο πατέρα, εκτός
από τη ρίζα, η οποία είναι ο μόνος κόμβος χωρίς κόμβο πατέρα. Οι κόμβοι που δεν
έχουν κόμβους παιδιά ονομάζονται ονομάζονται
τερματικοί κόμβοι (terminal nodes)
ή εξωτερικοί κόμβοι (external nodes)
ή φύλλα (leaves). Κόμβοι με
παιδιά ονομάζονται μη τερματικοί κόμβοι (non-terminal
nodes) ή εσωτερικοί κόμβοι (internal
nodes) ή κλαδιά (branches).
Επίπεδο (Level):
Επίπεδο ενός κόμβου ορίζεται ως ο αριθμός των κόμβων στο μονοπάτι από τον
κόμβο μέχρι τη ρίζα.
Μήκος μονοπατιού ενός κόμβου είναι ο αριθμός των κόμβων που πρέπει να περάσουμε για να
φθάσουμε από τη ρίζα του δένδρου στο κόμβο .
Εσωτερικό μήκος μονοπατιού ενός δένδρου είναι το άθροισμα του μήκους των μονοπατιών
όλων των κόμβων του δένδρου.
Μέσο μήκος μονοπατιού είναι το πηλίκο του εσωτερικού μήκους μονοπατιού δια το
πλήθος των κόμβων.
Βάθος (depth) ή Υψος (height): Το μεγαλύτερο επίπεδο στο οποίο μπορεί να βρίσκεται ένας
κόμβος του δέντρου είναι το βάθος ή ύψος
του δέντρου.
Βαθμός (Degree) ενός κόμβου του δέντρου ονομάζεται το πλήθος των κόμβων παιδιών του.
Βαθμός
(Degree) ενός δένδρου: Ο μέγιστος από τους βαθμούς όλων των κόμβων του δένδρου
ονομάζεται βαθμός του
δένδρου.
Στην
εικόνα 2 δίνεται ένα παράδειγμα
δένδρου. Επιπλέον, μπορείτε να ξεχωρίσετε τα στοιχεία που το αποτελούν και που
ορίσαμε παραπάνω.
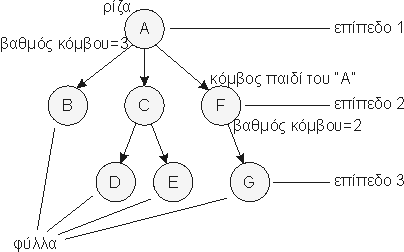
Εικόνα 13.2: Παράδειγμα δένδρου
Στο
παραπάνω παράδειγμα το "Α" είναι η ρίζα του δένδρου. Έχει τρεις
κόμβους παιδιά, το "Β", το "C" και το "F",
οπότε ο βαθμός της ρίζας είναι 3. Ο κόμβος "C" έχει δύο κόμβους παιδιά
(βαθμός κόμβου 2), το "D" και το "E". Ο κόμβος "F" έχει
ένα κόμβο παιδί, το "G". Οι κόμβοι "B", "D",
"E" και "G" είναι κόμβοι φύλλα (δεν έχουν κόμβους παιδιά). Ο
βαθμός του δένδρου είναι 3 και το βάθος επίσης 3.
Υποδένδρο (Subtree):
Κάθε κομμάτι του δένδρου από έναν κόμβο και κάτω ονομάζεται υποδένδρο του δένδρου.
Στην εικόνα 3 ορίζεται ένα υποδένδρο στο δένδρο του παραπάνω παραδείγματος, της εικόνας 2.
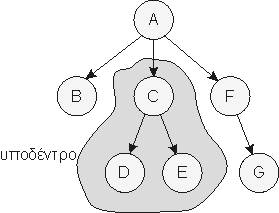
Εικόνα 13.3: Παράδειγμα υποδένδρου
Δάσος
(Forest):
Δάσος ονομάζεται ένα σύνολο από δένδρα και σχηματίζεται αν κόψουμε ένα δένδρο
σε έναν κόμβο με παιδιά.
13.1.2 Το Δυαδικό δένδρο - Binary
Tree
Ένα δένδρο ονομάζεται δυαδικό αν όλοι οι κόμβοι του έχουν
βαθμό ≤ 2.
Ως δυαδικό δένδρο ορίζεται ένα δένδρο το οποίο είτε είναι κενό,
είτε αποτελείται από μια ρίζα και δύο δυαδικά υπόδενδρα, το καθένα διακριτό από
το άλλο και από τη ρίζα. Αναφερόμαστε στα δύο υπόδενδρα ως το αριστερό και το
δεξιό υπόδενδρο.
Εικόνα 13.4: Παράδειγμα δυαδικού δένδρου
Το ύψος ενός δυαδικού δένδρου με n κόμβους
μπορεί να είναι το πολύ n – 1 και το λιγότερο log2(n)
Γεμάτο (full): Ένα δυαδικό δένδρο είναι γεμάτο, αν κάθε εσωτερικός του κόμβος
έχει δύο παιδιά. Δηλαδή αν έχει βάθος k θα πρέπει να έχει 2k − 1 κόμβους. Για παράδειγμα, για k = 3, ο αριθμός των κόμβων θα είναι = 2k − 1 = 23 −
1 = 8 − 1 = 7. Ένα γεμάτο δυαδικό δένδρο βάθους k = 4 φαίνεται στην εικόνα 5.
Εικόνα 13.5: Γεμάτο ή πλήρες δυαδικό δένδρο
Χρησιμοποιούμε του αριθμούς από το κ ως το 2k − 1 ως ετικέτες για τους κόμβους του δένδρου.
Τέλειο (perfect): Ένα δυαδικό δένδρο είναι τέλειο (perfect), αν είναι γεμάτο
και όλα τα φύλλα έχουν το ίδιο βάθος.
Πλήρες (complete): Ένα δυαδικό δένδρο είναι πλήρες (complete) αν
1. έχει βάθος 0 και ένα κόμβο,
2. έχει βάθος 1 και η ρίζα του έχει είτε δύο
παιδιά είτε ένα αριστερό παιδί.
3. έχει βάθος κ και η ρίζα του έχει ένα
τέλειο αριστερό υπόδενδρο ύψους κ-1
και ένα πλήρες δεξιό υπόδενδρο ύψους κ-1
4. έχει βάθος κ και η ρίζα του έχει ένα
πλήρες αριστερό υπόδενδρο ύψους κ-1 και ένα τέλειο δεξιό υπόδενδρο ύψους κ-2.
Ένα πλήρες (complete) δυαδικό δένδρο
βάθους k = 4 φαίνεται στην εικόνα 6.
Εικόνα 13.6: Πλήρες δυαδικό δένδρο βάθους k = 4
Ισοζυγισμένο ή Ισορροπημένο (Balanced): Ισοζυγισμένο λέγεται το δυαδικά δένδρο που
το δεξί και το αριστερά υποδένδρο έχουν διαφορά 1 το πολύ κόμβο. Συνήθως
επιδιώκεται η δημιουργία ισοζυγισμένων δένδρων γιατί μειώνεται κατά πολύ ο
χρόνος αναζήτησης ενός συγκεκριμένου κόμβου (μειώνεται το εσωτερικά μήκος
μονοπατιού και το ύψος). Αποδεικνύεται ότι οι απαιτούμενες συγκρίσεις σε ένα
δυαδικά δένδρο που δημιουργείται με κόμβους, οι οποίοι φθάνουν με τυχαία σειρά,
είναι περίπου 39% περισσότερες από αυτές που απαιτούνται σε ένα ισοζυγισμένο
δένδρο.
Ένα δυναμικό δυαδικό δένδρο λόγω διαδοχικών
εισαγωγών και διαγραφών, μπορεί στην ακραία περίπτωση να εκφυλιστεί σε μία
γραμμική λίστα. Τότε ο χρόνος επεξεργασίας από Ο(log n) καταλήγει σε Ο(n).
Συνεπώς, πρέπει το δένδρο μετά από κάθε λειτουργία να παραμείνει όσο το δυνατόν
πιο ισορροπημένο και μάλιστα η διαδικασία εξισορρόπησης να μην είναι δαπανηρή
σε υπολογιστικούς πόρους.
Ένα δυαδικό δένδρο λέγεται ισορροπημένο κατά ύψος
(height balanced tree) αν το ύψος του αριστερού και του δεξιού υποδένδρου κάθε
κόμβου διαφέρει το πολύ κατά ένα.
Ένα δυαδικό δένδρο λέγεται τέλεια ισορροπημένο
(perfectly balanced tree) όταν το πλήθος των κόμβων του αριστερού και του
δεξιού υποδένδρου κάθε κόμβου διαφέρει το πολύ κατά ένα.
α)
Εκφυλισμένο δένδρο β)
Ισορροπημένο γ) Τέλεια
ισορροπημένο κατά ύψος
Εικόνα 13.7 Τύποι δυαδικών δένδρων
13.1.3 Διάσχιση δυαδικών δένδρων
Υπάρχουν τέσσερα είδη διάσχισης δυαδικών
δέντρων. Για την παρουσίαση τους θα χρησιμοποιήσουμε το παράδειγμα της
ακόλουθης εικόνας.
Εικόνα 13.8: Παράδειγμα δένδρου που θα χρησιμοποιηθεί στην εξήγηση
των μεθόδων διάσχισης
Προδιατεταγμένη διάσχιση (preorder traversal):
Κατά την
προδιατεταγμένη διάσχιση (preorder traversal) πραγματοποιούνται
τα ακόλουθα:
1. Επίσκεψη της
ρίζας
2. Επίσκεψη
αριστερού υποδένδρου
3. Επίσκεψη δεξιού
υποδένδρου
Το αποτέλεσμα της
λειτουργίας της προδιατεταγμένης διάσχισης στο
παράδειγμα του παραπάνω σχήματος, είναι: A, B, C, D,
E, F, G.
Μεταδιατεταγμένη διάσχιση (Postorder traversal):
Κατά
την μεταδιατεταγμένη διάσχιση πραγματοποιούνται
τα ακόλουθα:
1.
Επίσκεψη αριστερού υποδένδρου
2. Επίσκεψη δεξιού
υποδένδρου
3. Επίσκεψη της
ρίζας
Το αποτέλεσμα της
λειτουργίας της μεταδιατεταγμένης διάσχισης στο
παράδειγμα του παραπάνω σχήματος, είναι: C, E, F, D, B, G, A.
Ενδοδιατεταγμένη διάσχιση (Inorder traversal)
Κατά
την ενδοδιατεταγμένη διάσχιση πραγματοποιούνται τα ακόλουθα:
1.
Επίσκεψη αριστερού υποδένδρου
2.
Επίσκεψη της ρίζας
3.
Επίσκεψη δεξιού υποδένδρου
Τα
αποτέλεσμα της λειτουργίας της ενδοδιατεταγμένη διάσχισης, στο παράδειγμα του παραπάνω σχήματος, είναι: C, B, D, E,
F, A, G.
Κατά σειρά επιπέδων
Κατά την σειρά
επιπέδων διάσχιση επισκεπτόμαστε τα στοιχεία κατά επίπεδα από πάνω προς τα
κάτω. Σε κάθε επίπεδο επισκεπτόμαστε τα στοιχεία από τα αριστερά προς τα δεξιά.
Τα
αποτέλεσμα της λειτουργίας της κατά
σειρά επιπέδων διάσχισης, στο παράδειγμα του
παραπάνω σχήματος, είναι Α, B, G,
C, D, E,
F.
Οι όροι δυαδική
αναζήτηση και
δυαδικό δένδρο αναζήτησης ( Binary Search - Tree) συχνά συγχέονται.
Λόγω του ότι στο επόμενο κεφάλαιο θα μελετήσουμε τα δυαδικά δένδρα αναζήτησης
στο σημείο αυτό θα εξηγήσουμε τον όρο δυαδική αναζήτηση.
Η δυαδική αναζήτηση βασίζεται στην ιδέα ότι, αν οι αριθμοί του πίνακα
είναι ταξινομημένοι, μπορούμε να
παραλείπουμε από τη εξέταση τους μισούς από αυτούς, συγκρίνοντας κάθε φορά τον
αριθμό που αναζητάμε με εκείνον τον αριθμό που βρίσκεται στη μεσαία θέση του
πίνακα. Αν είναι ίσος, έχουμε μια επιτυχή αναζήτηση. Αν είναι μικρότερος,
εφαρμόζουμε την ίδια μέθοδο στο αριστερό μισό του πίνακα. Αν είναι μεγαλύτερος,
εφαρμόζουμε την ίδια μέθοδο στο δεξιό μισό του πίνακα. Ακολουθεί ένα παράδειγμα
της λειτουργίας αυτής της μεθόδου σε ένα δεδομένο σύνολο αριθμών. Για να εξετάσουμε κατά πόσο
περιλαμβάνεται ο αριθμός 5025 στον παρακάτω πίνακα αριθμών, αρχικά τον συγκρίνουμε
με τον αριθμό 6504.Αυτό μας οδηγεί στην εξέταση του πρώτου μισού του πίνακα.
Στη συνέχεια, τον συγκρίνουμε με τον αριθμό 4548 (τον μεσαίο του πρώτου μισού
του πίνακα), κάτι που μας οδηγεί στο δεύτερο μισό του πρώτου μισού. Συνεχίζουμε
με αυτόν τον τρόπο, εργαζόμενοι πάντοτε σε έναν υποπίνακα ο οποίος θα πρέπει να
περιέχει τον αριθμό που αναζητάμε, εφόσον βέβαια ο αριθμός αυτός υπάρχει στον
πίνακα. Τελικά, καταλήγουμε σε έναν πίνακα με ένα μόνο στοιχείο, το οποίο δεν
είναι ίσο με τον αριθμό 5025, οπότε αντιλαμβανόμαστε ότι ο αριθμός 5025 δεν
περιλαμβάνεται στον πίνακα.
Ο ταξινομημένος
πίνακας για το παράδειγμα της δυαδικής αναζήτησης:
1488 1488
1578 1578
1973 1973
3665 3665
4426 4426
4548 4548
5435 5435 5435 5435
5435
5446 5446 5446 5446
6333 6333 6333
6385 6385 6385
6455 6455 6455
6504
6937
6965
7104
7230
8340
8950
9210
9363
9550
6945
6989
13.2 Το Binary Search – Tree
13.2.1 Παρουσίαση της λειτουργίας του BS – Tree ή B-Tree
Στα τέλη του 1960 κατασκευαστές
συστημάτων υπολογιστών καθώς και ανεξάρτητες ερευνητικές ομάδες ανέπτυξαν
ανταγωνιστικά συστήματα αρχείων (file-systems) και τα αποκάλεσαν “μεθόδους προσπέλασης - access methods”. Στην εταιρία Sperry
Univac (σύμπραξη με το
πανεπιστήμιο Case Western Reserve) οι H. Chiat, M.
Schwartz, και άλλοι
ανέπτυξαν και υλοποίησαν ένα σύστημα το οποίο εκτελούσε εργασίες εισόδου και
εύρεσης με τρόπο όμοιο της μεθόδου Binary Search – Tree, την οποία θα
περιγράψουμε παρακάτω.
Τα δυαδικά δένδρα αναζήτησης (Binary
Search – Tree) αποτελούν ειδική κατηγορία των δυαδικών δένδρων. Είναι διατεταγμένα, δηλαδή δένδρα στα οποία η διάταξη των παιδιών κάθε κόμβου έχει
σημασία. Στα δυαδικά δένδρα αναζήτησης κάθε κόμβος έχει μεγαλύτερη τιμή από όλους τους κόμβους που βρίσκονται
στα αριστερά του και μικρότερη από την τιμή όλων των κόμβων δεξιά του.
Το δένδρο της εικόνας 11 είναι ένα δυαδικό δένδρο αναζήτησης:
Εικόνα 13.9: Binary Search – Tree
Ένα μη κενό δυαδικό δένδρο αναζήτησης ικανοποιεί τις εξής ιδιότητες:
- Κάθε
στοιχείο (κόμβος) έχει μια τιμή και δεν υπάρχουν δυο στοιχεία με την ίδια
τιμή. Κατά συνέπεια όλα τα στοιχεία είναι διακριτά.
- Οι κόμβοι
(αν υπάρχουν) στο αριστερό υποδένδρο της ρίζας είναι μικρότεροι από τη
τιμή της ρίζας.
- Οι κόμβοι
(αν υπάρχουν) στο δεξιό υποδένδρο της ρίζας είναι μεγαλύτεροι από τη τιμή
της ρίζας.
- Το
αριστερό και το δεξιό υποδένδρο είναι επίσης δυαδικά δένδρα αναζήτησης.
Η υποκείμενη δομή δεδομένων μας επιτρέπει να αναπτύξουμε αλγόριθμους με
υψηλές επιδόσεις κατά την εκτέλεση των λειτουργιών αναζήτησης, εισαγωγής,
επιλογής, και ταξινόμησης μιας συλλογής δεδομένων, στη μέση περίπτωση. Αποτελεί
την καλύτερη μέθοδο για πολλές εφαρμογές και θέτει υποψηφιότητα ως ένας από
τους πιο θεμελιώδεις αλγόριθμους της επιστήμης των υπολογιστών.
13.2.2 Παρουσίαση της διαδικασίας εισαγωγής/ διαγραφής/ αναζήτησης
Αναζήτηση κόμβου:
Ο αλγόριθμος αναζήτησης σε
δυαδικό δένδρο αναζήτησης, με ρίζα το Β, αποσκοπεί στον εντοπισμό του κόμβου
που έχει μια δεδομένη τιμή Χ (value).
Ξεκινώντας από τη ρίζα σε κάθε
κόμβο γίνεται σύγκριση της τιμής Χ με το περιεχόμενο του κόμβου. Αν βρεθούν ίσα
η αναζήτηση σταματά. Αν η τιμή είναι μικρότερη της ρίζας η αναζήτηση
συνεχίζεται στο αριστερό υποδένδρο αλλιώς συνεχίζεται στο δεξιό υποδένδρο. Ο
αλγόριθμος επίσης σταματά αν φθάσουμε σε κάποιο τερματικό κόμβο (φύλλο) χωρίς
να βρεθεί η τιμή Χ σε κάποιο κόμβο του δένδρο.
Αλγόριθμος Αναζήτησης Κόμβου Search_Node (ψευδικώδικας)
// Δεδομένα Root:
ρίζα δένδρου, Χ: ζητούμενος κόμβος, Ω : λογική μεταβλητή, Β : βοηθητική μεταβλητή
Ξεκίνα
Var Β := Root, Ω:= false
Όσο Β <> τιμή Χ και Ω = Ψευδής
Κάνε
Ξεκίνα
Εαν Β = Χ τότε
Ω
= true
Διαφορετικά
Εαν Χ>B Τοτε
B=(Δεξιό παιδί του Β)
Διαφορετικά
B=(Αριστερό παιδί του Β)
Τέλος Εαν
Τέλος Εαν
Τέλος
Τέλος
Εισαγωγή κόμβου:
Ο αλγόριθμος με
βάση τον οποίο εισάγουμε μια τιμή σε δυαδικό δένδρο αναζήτησης είναι ο εξής:
Για την εισαγωγή ενός στοιχείου Χ σε ένα δυαδικό δένδρο αναζήτησης, πρέπει
πρώτα να επιβεβαιώσουμε ότι το στοιχείο είναι διαφορετικό από τα ήδη υπάρχοντα
στοιχεία, εκτελώντας μια αναζήτηση. Αν η αναζήτηση είναι ανεπιτυχής τότε το
στοιχείο εισάγεται στο σημείο όπου τερματίστηκε η αναζήτηση.
Στην εικόνα 13.10 βλέπουμε το παράδειγμα
δημιουργίας ενός δυαδικού δένδρου αναζήτησης με διαδοχικές εισαγωγές τιμών. Οι
τιμές που εισάγονται είναι: 37, 24, 42, 6, 40, 60.
Εικόνα 13.10: Παράδειγμα δημιουργίας BS - Tree
Διαγραφή κόμβου:
Η διαδικασία της διαγραφής σε δυαδικό δένδρο
αναζήτησης είναι πιο σύνθετη από τη διαδικασία της εισαγωγής. Αν ο κόμβος που
πρόκειται να διαγραφεί είναι τερματικός (φύλλο), τότε η περίπτωση είναι εύκολη,
απλά διαγράφουμε τον κόμβο. Σχετικά εύκολη είναι και η περίπτωση, όπου ο
διαγραφόμενος κόμβος έχει μόνο έναν απόγονο, απλά αντικαθίσταται από το παιδί
του. Η δυσκολία του προβλήματος παρουσιάζεται όταν το στοιχείο που θα διαγραφεί
έχει δύο απογόνους. Στην περίπτωση αυτή ο διαγραφόμενος κόμβος αντικαθίσταται είτε
από τον δεξιότερο κόμβο του αριστερού υποδένδρου είτε από τον αριστερότερο
κόμβο του δεξιού υποδένδρου.
Στην εικόνα 13.11 βλέπουμε το παράδειγμα
αφαίρεσης του κόμβου με τιμή 37 από ένα δυαδικό δένδρο αναζήτησης:
Εικόνα 13.11: Παράδειγμα αφαίρεσης της τιμής 37
13.2.3 Διάσχιση του B - Tree
Ουσιαστικά, ισχύει ότι ακριβώς και για το Binary - Tree. Υπάρχουν τρία είδη διάσχισης η προδιατεταγμένη
(preorder), η μεταδιατεταγμένη (postorder), και η
ενδοδιατεταγμένη (inorder). Είναι προφανές ότι αν διασχίσουμε το δένδρο
με τον ενδοδιατεταγμένο τρόπο το αποτέλεσμα που θα προκύψει θα είναι
ταξινομημένο, από το μικρότερο στο μεγαλύτερο. Φυσικά η ταξινόμηση δεν ισχύει
για τη διάσχιση του δένδρου με κάποιο από τους άλλους τρόπους.
13.2.4 Χαρακτηριστικά επιδόσεων του B - Tree
Οι χρόνοι εκτέλεσης των αλγορίθμων σε δένδρα
δυαδικής αναζήτησης εξαρτώνται από το σχήμα των δένδρων. Το κόστος κάθε
διαδικασίας είναι ανάλογο του βάθους (ύψους) του δένδρου. Στην καλύτερη
περίπτωση, το δένδρο μπορεί να είναι πλήρως ισορροπημένο (ισοζυγισμένο) με
περίπου lοg2(Ν) κόμβους ανάμεσα στη ρίζα και κάθε εξωτερικό κόμβο, αλλά στη
χειρότερη περίπτωση μπορεί να υπάρχουν Ν κόμβοι στη διαδρομή αναζήτησης. Θα
μπορούσαμε να αναμένουμε από τους χρόνους εκτέλεσης να επίσης λογαριθμικοί στη
μέση περίπτωση (υποθέτοντας πως όλα τα δεδομένα είναι εξίσου πιθανά) επειδή το
πρώτο στοιχείο που εισάγεται γίνεται ρίζα του δένδρου – αν πρέπει να εισαχθούν
Ν κλειδιά τυχαία αυτό το στοιχείο θα χωρίζει τα κλειδιά στη μέση(κατά μέσο όρο),
κάτι που θα οδηγήσει σε λογαριθμικούς χρόνους αναζήτησης (με την ίδια λογική
στα υποδένδρα). Αυτή η περίπτωση θα ήταν η καλύτερη γι’ αυτόν τον αλγόριθμο με εγγυημένο
λογαριθμικό χρόνο εκτέλεσης για όλες τις αναζητήσεις. Σε μια πραγματικά τυχαία
κατάσταση, η ρίζα έχει την ίδια πιθανότητα να είναι οποιαδήποτε κλειδί,
επομένως ένα τέτοιο τέλεια ισορροπημένο δένδρο είναι εξαιρετικά σπάνιο και δεν
μπορούμε εύκολα να διατηρήσουμε το δένδρο τέλεια ισορροπημένο μετά από κάθε
εισαγωγή. Πάντως, επειδή και τα δένδρα που είναι μη ισορροπημένα σε υψηλό βαθμό
σπάνια εμφανίζονται για τυχαία κλειδιά, τα δένδρα μάλλον είναι καλά
ισορροπημένα κατά μέσο όρο.
Στη χειρότερη
περίπτωση (Worst case behavior) μια αναζήτηση σε δένδρο δυαδικής
αναζήτησης με Ν κόμβους μπορεί να απαιτεί Ν συγκρίσεις. Αυτή η συμπεριφορά
χειρότερης περίπτωσης δεν είναι απίθανη
στην πράξη, εμφανίζεται όταν εισάγουμε τα στοιχεία με ταξινομημένη σειρά ή με αντίστροφη σειρά ταξινόμησης σε ένα
αρχικά κενό δένδρο χρησιμοποιώντας τον καθιερωμένο αλγόριθμο. Στην χειρότερη
περίπτωση, το δυαδικό δένδρο εκφυλίσετε σε μια μορφή η οποία είναι ισοδύναμη με
αυτή της απλά συνδεδεμένης λίστας, κάτι που οδηγεί σε τετραγωνικό χρόνο
κατασκευής του δένδρου και γραμμικό χρόνο αναζήτησης. Το δένδρο σε αυτή την
περίπτωση ονομάζεται λοξό (Skewed – Tree), ένα παράδειγμα
λοξού δένδρου φαίνεται στην εικόνα 13.12
.
Εικόνα
13.12: Ένα
Δυαδικό δένδρο αναζήτησης χειρότερης περίπτωσης (Skewed
tree)
Το πρόβλημα της κακής
επίδοσης στην χειρότερη περίπτωση του δυαδικού δένδρου αναζήτησης, εξαλείφεται
αν έχουμε τέλεια ισορροπημένο δένδρο (ισοζυγισμένο).
13.2.5 Άλλες εκδοχές του BS - Tree (Variations)
AVL - Trees
Η ονομασία των δένδρων αυτών προέκυψε από τα
ονόματα των δύο Ρώσων ερευνητών που τα πρότειναν: του Adelson - Velskii και του
Landis το 1962. Η δομή αυτή συναντάται στη βιβλιογραφία και με την ονομασία ισοζυγισμένα
δένδρα κατά ύψος (height balanced trees).
Ένα δυαδικό δένδρο αναζήτησης λέγεται δένδρο
AVL αν για κάθε κόμβο του δένδρου ικανοποιούνται οι εξής δύο συνθήκες:
·
Η
διαφορά των υψών των δύο υποδένδρων του κόμβου είναι μικρότερη από ένα.
- Τα δύο
υποδένδρα του κόμβου είναι επίσης δένδρα AVL.
Παρατηρούμε ότι ο ορισμός είναι αναδρομικός και
παρέχει ευκαιρίες για ανάλυση. Η αναζήτηση στα δένδρα AVL γίνεται ακριβώς όπως
και στα απλά δυαδικά δένδρα αναζήτησης. Η διαφορά των δύο δόμων έγκειται στους
σύνθετους αλλά και κομψούς αλγορίθμους εισαγωγής/διαγραφής κλειδιών στα δένδρα
AVL, οι οποίοι εκτελούν περιστροφές (rotations), ώστε να μην παραβιάζεται ο
ανωτέρω ορισμός.
K-D - Tree
Το K-D – Tree παρουσιάστηκε το 1975 από τον Bentley και ουσιαστικά
είναι ένα πολυδιάστατο δυαδικό δένδρο αναζήτησης (multidimensional binary search tree)
όπου Κ ο αριθμός των διαστάσεων
(Dimensions) του διαστήματος αναζήτησης. Το K-D - Tree είναι μια δομή για αποθήκευση πολυδιάστατων σημείων
στο χώρο. Διαιρεί τον χώρο σε δύο υπό-χώρους και αποθηκεύει τα σημεία του ενός υπό-χώρου
στο αριστερό υποδένδρο και του άλλου στο δεξί. Στην εικόνα 13.13 βλέπουμε το
διαμοιρασμό ενός δυσδιάστατου χώρου με βάση το K-D
- Tree. Αρχικά, ένας
μοναδικός κόμβος, ο 1, υπάρχει στο σύστημα και αναλαμβάνει όλο το χώρο,
αντιστοιχώντας σε έναν κόμβο. Όταν φτάνει ο επόμενος κόμβος, ο 2, ο χώρος
διαμοιράζεται σε δυο μέρη με ίσο φορτίο ως προς την πρώτη διάσταση και κάθε
ένας αναλαμβάνει από ένα τμήμα. Αυτό οδηγεί σε διάσπαση του μοναδικού κόμβου
του δένδρου στα δύο. Καθώς νέοι κόμβοι εισέρχονται, η διαδικασία συνεχίζεται με
ανάλογο τρόπο, με διάσπαση υπαρχόντων φύλλων του δένδρου και αντίστοιχων
τμημάτων του χώρου δεδομένων. Σημειώνεται ότι κατά το διαμοιρασμό
χρησιμοποιούνται κυκλικά οι διαστάσεις. Αυτός α τύπος δένδρρου θα εξηγηθεί με
λεπτομέρεια παρακάτω.
Εικόνα 13.13: Ο διαμοιρασμός
του δυσδιάστατου χώρου
13.2.6 Χρήσεις του BS - Tree
To Binary
Search - Tree είναι μια πολύ χρήσιμη δομή δεδομένων. Η
πιο συνήθης χρήση του Binary Search – Tree είναι για
αποθήκευση και προσπέλαση δεδομένων (Information Storage
and Retrieval) σε συστήματα αρχείων ή συστήματα βάσεων δεδομένων, στα οποία
ενσωματώνετε. Συνήθως χρησιμοποιείται για την γρήγορη και αποδοτική
αναζήτηση ενός στοιχείου σε μια συλλογή δεδομένων. Για παράδειγμα, αν είχαμε
μια συνδεδεμένη λίστα από 1000 στοιχεία και θέλαμε να μάθουμε αν ένα συγκεκριμένο στοιχείο υπάρχει μέσα στην
λίστα αυτό θα απαιτούσε να αναζητήσουμε
σειριακά ένα προς ένα τα στοιχεία ξεκινώντας από την αρχή και προχωρώντας προς
το τέλος της λίστας. Αν ήμασταν τυχεροί, ίσως το βρίσκαμε στην αρχή της λίστας.
Εξίσου πιθανό θα ήταν το στοιχείο να βρίσκεται στο τέλος της λίστας, το οποίο
θα σήμαινε ότι θα έπρεπε να ψάξουμε όλα τα στοιχεία πριν από αυτό. Αυτό μπορεί
να μην φαντάζει ως μεγάλο πρόβλημα, ειδικά στις μέρες μας όπου οι υπολογιστές
έχουν γίνει πολύ γρήγοροι, αλλά φανταστείτε αν η λίστα ήταν πολύ μεγαλύτερη και
οι αναζητήσεις επαναλαμβάνονταν πολλές φορές. Αυτού του είδους οι αναζητήσεις
συμβαίνουν συχνά σε web servers και τεράστιες βάσεις δεδομένων,
το οποίο δημιουργεί την ανάγκη για πολύ γρήγορες τεχνικές αναζήτησης.
Τα
δυαδικά δένδρα αναζήτησης βασίζονται
στις αρχές τις περιοδικά επαναλαμβανόμενης διάσπασης (recursive
decomposition) οι οποίες είναι
παρόμοιες με τις μεθόδους διαίρει κα βασίλευε και μειώνουν τον χρόνο αναζήτησης
σημαντικά κάνοντας τα αρκετές φορές πιο γρήγορα από οποιαδήποτε δομή σειριακής
αναζήτησης.
13.3 Το Quad – Tree
3.3.1 Παρουσίαση της λειτουργίας του Quad - Tree
Τα Quad-Trees προτάθηκαν από τους R.Finkel και J.L.Bentley το 1974. Πρόκειται για
μια από τις πιο έντονα μελετημένες δομές δεδομένων η οποία στηρίζεται στις
αρχές της περιοδικά επαναλαμβανόμενης διάσπασης divide and
conquer methods)
Στην απλούστερη
του μορφή το Quad –Tree είναι όμοιο με το δυαδικό δένδρο, με εξαίρεση
ότι κάθε κόμβος-γονέας έχει τέσσερις απογόνους (κάποιοι από τους οποίους μπορεί
να είναι κενοί), για αυτό και ονομάζεται τετραδικό (Quad) δένδρο. To Quad – Tree είναι μια μη ισορροπημένη (unbalanced) χωρική δομή δεδομένων η οποία διασπάει περιοδικά τον χώρο (δυσδιάστατο
χώρο) σε τέσσερα ίσου μεγέθους ασυνάρτητα τεταρτημόρια, μέχρι κάθε κόμβος φύλλο
να περιέχει ένα μόνο σημείο. Η περιοχή στην οποία διασπάτε ο χώρος μπορεί να
είναι τετράγωνη, ορθογώνια ή να έχει αυθαίρετα σχήματα ανάλογα με την εκδοχή του
Quad – Tree. To Quad – Tree το συναντάμε συχνά
στην βιβλιογραφία και ως Q
- Tree. Υπάρχουν πολλές
παραλλαγές του Quad –
Tree, όλες όμως έχουν
κάποια κοινά χαρακτηριστικά:
·
Διασπούν
τον χώρο σε προσαρμόσιμα κελιά
·
Κάθε κελί
έχει μια μέγιστη χωρητικότητα. Όταν το κελί φθάσει την μέγιστη χωρητικότητα του
διασπάτε.
- Ο
δενδρικός κατάλογος ακολουθεί τη χωρική διάσπαση του Quad – Tree.
13.3.2 Παρουσίασης της διαδικασίας δημιουργίας ενός Quad – Tree
Η πιο συνηθισμένη μέθοδος απόδοσης
τιμών στα τεταρτημόρια ενός Quad – Tree είναι αυτή της εικόνας 13.14 (c
ordering) όπου οι αριθμοί
παρατάσσονται με σειρά αντίθετη αυτής των δεικτών του ρολογιού. Άλλη γνωστή
μέθοδος απόδοσης τιμών στα τεταρτημόρια ενός Quad Tree είναι της εικόνας 13.15 (Z ordering) όπου οι αριθμοί παρατάσσονται έτσι ώστε να σχηματίζεται ένα νοητό Z.
Εικόνα 13.14: C ordering Εικόνα 13.15: Z ordering
Στις παρακάτω
εικόνες παρουσιάζεται το παράδειγμα της δημιουργίας ενός Quad – Tree. Στην πρώτη
εικόνα φαίνονται τα σημεία που έχουν επιλεχθεί για την δημιουργία του Quad – Tree. Η πρώτη εικόνα
αποτελεί την ρίζα του δένδρου. Στην συνέχεια χωρίζεται σε τεταρτημόρια όπου
σε κάθε ένα από αυτά αντιστοιχεί ένας
αριθμός (1, 2, 3, 4). Στα τεταρτημόρια που έχουμε περισσότερα του ενός σημεία η
διαδικασία συνεχίζεται έως κάθε σημείο να ανήκει σε διαφορετικό τεταρτημόριο, εικόνα
13.19.

Εικόνα 13.16: Τα
σημεία που επιλέχθηκαν Εικόνα 13.17: Επίπεδο 1
Στην εικόνα 13.17 παρατηρούμε ότι τα τεταρτημόρια
1 και 4 περιέχουν περισσότερα του ενός σημεία. Η διαδικασία συνεχίζεται, εικόνα 13.18, όπου τα τεταρτημόρια αυτά
έχουν χωριστεί εκ νέου σε τέσσερα νέα αλλά το τεταρτημόριο 1.1 συνεχίζει να
περιέχει περισσότερα του ενός σημεία. Για το λόγω αυτό η διαδικασία συνεχίζεται
και ολοκληρώνεται στην εικόνα 13.19
όπου κάθε σημείο ανήκει σε διαφορετικό τεταρτημόριο.
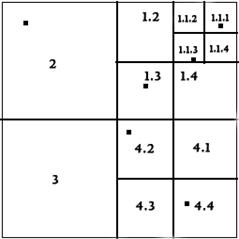
Εικόνα 13.18: Επίπεδο 2 Εικόνα
13.19: Επίπεδο 3
Το τετραδικό
δένδρο (Quad - Tree) που σχηματίζεται
από την εφαρμογή του αλγορίθμου στα σημεία της εικόνας 8, φαίνεται στην εικόνα 13.20.
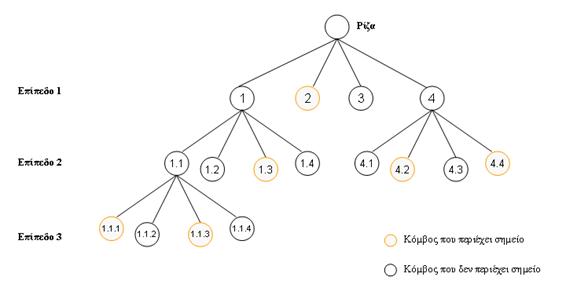
Εικόνα 13.20: Το Quad – Tree των σημείων της εικόνας 18
13.3.3 Άλλες εκδοχές του Quad-Tree (Variations)
Oct – Tree
Τα Quad – Tree μπορούν να επεκταθούν
σε περισσότερες από δύο διαστάσεις χωρίς καμία διαφορά στον τρόπο λειτουργίας
του αλγόριθμου. Ένα Quad -
Tree τριών διαστάσεων
ονομάζεται Oct – tree (οκταδικό δένδρο) επειδή κάθε εσωτερικός
του κόμβος έχει 8 παιδιά. Αντίστοιχα ένα Quad – Tree d διαστάσεων ονομάζεται 2d –Tree , αφού κάθε κόμβος θα έχει 2d παιδιά.
Εικόνα 13.21: Παράδειγμα Oct - Tree
Region Quad - Tree
Το region Quad - Tree είναι το πιο
δημοφιλές μέλος της οικογένειας μεθόδων προσπέλασης Quad - Tree και χρησιμοποιείται για την αναπαράσταση
δυαδικών εικόνων. Κάθε κόμβος αντιστοιχεί σε ένα τετράγωνο πίνακα από Pixels(η ρίζα αντιστοιχεί σε ολόκληρη την εικόνα). Εάν όλα
τα pixel έχουν το ίδιο χρώμα (μαύρο ή άσπρο), τότε ο
κόμβος είναι φίλο αυτού του χρώματος. Διαφορετικά ο κόμβος είναι χρώματος
γκρίζου και έχει τέσσερα παιδιά. Κάθε ένα από τα παιδιά του κόμβου αυτού
αντιστοιχεί σε ένα υπό-πίνακα στον οποίο ο πίνακας του κόμβου έχει τεμαχιστεί.
Κάθε Region Quad – Tree μπορεί να
χρησιμοποιηθεί για την αναπαράσταση μιας εικόνας 2n * 2n pixels, όπου η τιμή κάθε pixel μπορεί να είναι 0 ή 1. O
κόμβος της ρίζας αντιπροσωπεύει όλη την περιοχή της εικόνας. Αν τα pixel σε μια περιοχή της εικόνας δεν είναι
εντελώς 0 ή 1 τότε η περιοχή διασπάτε.
Αν το region Quad – Tree χρησιμοποιηθεί για να αναπαραστήσει ένα σύνολο από δεδομένα σημείων,
όπως για παράδειγμα το γεωγραφικό πλάτος και μήκος ενός συνόλου πόλεων, η
περιοχές υποδιαιρούνται μέχρι κάθε φύλλο να περιέχει ένα σημείο.
Η εικόνα δείχνει ένα 8 Χ 8 πίνακα pixel και το αντίστοιχο Quad - Tree. Παρατήρηση: Τα μαύρα - άσπρα τετράγωνα
αντιπροσωπεύουν μαύρα - άσπρα φύλλα, ενώ οι κύκλοι αντιπροσωπεύουν γκρίζους
κόμβους.
Εικόνα 13.22: Το Region Quad -
Tree
Point
Region Quad - Tree
Ένα Point Region (PR) Quad – Tree είναι μια εκδοχή του Quad – Tree όπου κάθε κόμβος
πρέπει να έχει ακριβώς τέσσερα παιδιά, η φύλλο, το οποίο δεν έχει παιδιά. Το PR Quad – Tree αντιπροσωπεύει μια συλλογή από σημειακά δεδομένα (data
points) σε δυο διαστάσεις
διασπώντας την περιοχή που περιέχει τα σημειακά δεδομένα σε τέσσερα ίσα
τεταρτημόρια (quadrants), υπό-τεταρτημόρια, και συνεχίζει μέχρι κανένας κόμβος - φύλλο να μην
περιέχει περισσότερα από ένα σημεία.
13.3.4 Χρήσεις του Quad-Tree
Το Quad – Tree και οι παραλλαγές του
έχουν πολλές εφαρμογές, οι περισσότερες από τις οποίες σχετίζονται με τον
τομέα της εικόνας. Ειδικότερα το Quad - Tree χρησιμοποιείται:
·
Στον
τομέα των Computer Graphics για την αναπαράσταση μιας εικόνας ή
φωτογραφίας. Επιτρέπει την αναπαράσταση μιας εικόνας σε διαφορετικά επίπεδα
ανάλυσης.
·
Στον
τομέα της ψηφιακής επεξεργασίας εικόνας (Image Processing)
για την σύμπτυξη (Compact)
ή συμπίεση (Compress) μιας εικόνας. Με τον όρο compact εννοούμε την συμπίεση χωρίς απώλειες:
Μπορούμε να ανακτήσουμε ακριβώς την πρωτότυπη εικόνα. Αντίθετα, με τον όρο Compress εννοούμε την συμπίεση με απώλειες: Μπορούμε
να ανακτήσουμε μια κοντινή προσέγγιση της πρωτότυπης εικόνας.
Άλλες χρήσεις στον τομέα αυτό είναι για τον
τεμαχισμό μίας εικόνας με βάση το χρώμα ή το σχήμα των αντικειμένων που
περιέχει ή για τον εντοπισμό αντικειμένων σε μια εικόνα (Object Modeling).
·
Το Quad – Tree χρησιμοποιείται από αρκετές μεθόδους για την βάση-περιεχομένου ανάκτηση
εικόνας (Content-Based Image Retrieval), με σκοπό την σύλληψη των χωρικών χαρακτηριστικών της
εικόνας, για παράδειγμα χρώμα, υφή, σχήμα. Χαρακτηριστικά ερευνητικά πρωτότυπα
των μεθόδων αυτών είναι : DISIMA (Lin et al., 2001) , IKONA (Malki et al., 1999) και Virage Image Engine (Gupta & Jain, 1997).
·
Χρησιμοποιείται
από σχεδιαστικά προγράμματα τύπου CAD - Computer-Aided
Design.
·
Χρησιμοποιείται
στα γεωγραφικά συστήματα πληροφορίας - Geographical
Information Systems (GIS).
·
Χρησιμοποιείται
από στον τομέα της χαρτογράφηση.
·
Χρησιμοποιείται
από βάσεις δεδομένων εικόνων (Image databases).
·
Υλοποιούνται
από αρκετά συστήματα διαχείρισης βάσεων δεδομένων (ΣΔΒΔ) όπως την DB2 (Adler,
2001) και την Oracle (Kothuri et al.,
2002)
Τα τελευταία δεκαπέντε χρόνια το Quad – Tree έχει ενσωματωθεί σε πολλές εφαρμογές, είναι αντικείμενο συνεχής έρευνας
και ανάπτυξης και έχει πολλά να προσφέρει ακόμα στον τομέα της εικόνας.
13.4. Το R – TREE
13.4.1. Παρουσίαση της λειτουργίας του R-Tree
Τα R - Trees προτάθηκαν από τον Guttman ως κατ’
ευθείαν επέκταση των B+ - Trees σε n-διαστάσεις. Η δομή είναι ένα ισοζυγισμένο δέντρο που αποτελείται από
ενδιάμεσους και τερματικούς κόμβους. Ένας τερματικός
κόμβος είναι του τύπου:
(oid, R)
όπου oid είναι η ταυτότητα (identifier) του
αντικειμένου και χρησιμοποιείται για να αναφερόμαστε στο αντικείμενο που είναι
αποθηκευμένο στη Βάση δεδομένων. Το R είναι η προσέγγιση MBR (Minimum Bounding Rectangle) του αντικειμένου, δηλαδή είναι του τύπου
(pl-1,
pl-2, …, pl-n, pu-1,
pu-2, …, pu-n)
ο οποίος
αναπαριστά τις 2n συντεταγμένες τις
κάτω-αριστερής (pl) και της πάνω-δεξιάς (pu) γωνίας του n - διάστατου ορθογωνίου p. Ένας ενδιάμεσος κόμβος είναι
του τύπου
(ptr, R)
όπου ptr είναι ένας δείκτης (pointer) σε έναν κόμβου κατωτέρου επιπέδου του δέντρου και R είναι η αναπαράσταση
του ορθογωνίου που περικλείει τα στοιχεία του κόμβου αυτού.
Έστω M το μέγιστο πλήθος στοιχείων ενός
κόμβου και έστω ![]() μια
παράμετρος που καθορίζει το ελάχιστο πλήθος στοιχείων ενός κόμβου[1].
μια
παράμετρος που καθορίζει το ελάχιστο πλήθος στοιχείων ενός κόμβου[1].
Ένα R - Τree έχει τις ακόλουθες ιδιότητες :
1. Κάθε τερματικός κόμβος περιέχει μεταξύ m και M στοιχεία εκτός
εάν είναι η ρίζα του δέντρου.
2. Σε κάθε στοιχείο (oid, R) ενός τερματικού κόμβου, το R είναι το ελάχιστο ορθογώνιο που περιέχει το αντικείμενο που αναπαρίσταται
από το oid.
3. Κάθε ενδιάμεσος κόμβος περιέχει μεταξύ m και M παιδιά εκτός εάν είναι η ρίζα του δέντρου.
4. Σε κάθε στοιχείο (ptr, R) ενός ενδιάμεσου κόμβου, το R είναι το ελάχιστο
ορθογώνιο που περιέχει τα ορθογώνια που βρίσκονται στον κόμβο-παιδί.
5. Η ρίζα έχει τουλάχιστον δύο παιδιά εκτός εάν είναι τερματικός κόμβος.
6. Όλοι οι τερματικοί κόμβοι (φύλλα) βρίσκονται στο ίδιο επίπεδο του δέντρου.
Η εικόνα 13.23 απεικονίζει ένα σύνολο
ορθογωνίων και το αντίστοιχο R - Tree που χτίζεται πάνω σε αυτά τα ορθογώνια (υποθέτουμε μέγιστη χωρητικότητα
κόμβου M = 4).
Εικόνα 13.23: Ορισμένα ορθογώνια, οργανωμένα σε ένα R - Tree και το αντίστοιχο R - Tree
13.4.2. Παρουσίασης της διαδικασίας
εισαγωγής/αναζήτησης
Η διαδικασία
αναζήτησης είναι απλή και λειτουργεί με τρόπο αντίστοιχο όπως στο B+ - Τree: Δοθέντος ενός
ορθογωνίου Q, ο αλγόριθμος αναζήτησης διατρέχει το δέντρο, ξεκινώντας από τη ρίζα και
επιλέγοντας σε κάθε επίπεδο τα υποδένδρα (ίσως περισσότερα από ένα) που
αναπαριστώνται από ορθογώνια που επικαλύπτονται με το Q.
Αλγόριθμος Αναζήτησης.
Βρες
όλα τα αντικείμενα των οποίων τα ορθογώνια τέμνουν ένα ορθογώνιο ερώτησης Q.
Βήμα1 Θέτουμε N να είναι η ρίζα.
Βήμα 2 Εάν N δεν είναι τερματικός κόμβος,
ελέγχουμε κάθε στοιχείο E του N του οποίου το ορθογώνιο E.R τέμνει
το Q.
Για όλα τα τεμνόμενα E
εκτελούμε τον Αλγόριθμο Αναζήτησης στο υποδένδρο του οποίου η ρίζα δείχνεται από τον δείκτη E.ptr.
Βήμα 3 Εάν N είναι
τερματικός κόμβος,
ελέγχουμε κάθε στοιχείο E του N για να εντοπίσουμε αν
το E.R τέμνει
το Q.
Εάν αυτό ισχύει, το E είναι
απάντηση στην ερώτηση.
Όπως η
διαδικασία αναζήτησης, έτσι και η διαδικασία εισαγωγής είναι παρόμοια με αυτήν
του B+ - Τree: τα νέα δεδομένα προστίθενται στα φύλλα, οι κόμβοι που υπερχειλίζουν
διασπώνται και οι διασπάσεις μεταφέρονται προς τα ανώτερα επίπεδα του δέντρου.
Όταν ένα νέο ορθογώνιο εισάγεται στη δεντρική δομή, ο αλγόριθμος ChooseSubtree επιλέγει τον κόμβο που είναι ο πιο κατάλληλος για την ανάθεση σε αυτόν του
νέου στοιχείου.
Αλγόριθμος
ChooseSubtree. Επέλεξε
έναν τερματικό κόμβο στον οποίο να εισαχθεί ένα νέο στοιχείο I.
Βήμα 1 Θέτουμε N να είναι η ρίζα.
Βήμα 2 Εάν N είναι τερματικός κόμβος,
επιστρέφουμε το N.
αλλιώς
Επιλέγουμε το στοιχείο E του N του οποίου το ορθογώνιο E.R απαιτεί
ελάχιστη αύξηση εμβαδού για να συμπεριλάβει το I.R.
Επιλύουμε τις ισοπαλίες επιλέγοντας το
στοιχείο με το μικρότερο εμβαδόν.
Βήμα 3 Θέτουμε N να είναι
ο κόμβος-παιδί που δείχνεται από τον δείκτη E.ptr του επιλεγμένου κόμβου και
επαναλαμβάνουμε από το Βήμα 2.
Αφού η απόφαση για το αν θα επισκεφθούμε έναν κόμβο κατά τη διάρκεια της
διαδικασίας αναζήτησης εξαρτάται από το εάν το ορθογώνιο που περιβάλλει τον
κόμβο αυτόν επικαλύπτεται με την περιοχή αναζήτησης, πρέπει να επιδιώκουμε την
ελάχιστη αύξηση του εμβαδού (area) του κόμβου
που επιλέγεται για τη νέα εισαγωγή Αυτό το κριτήριο είναι αποφασιστικό για την
απόδοση του R - Tree. Διαφορετικά κριτήρια οδηγούν σε τελείως διαφορετικές δεντρικές δομές.
Εάν ο κόμβος που επιλέχθηκε για την εισαγωγή υπερχειλίσει τότε ο αλγόριθμος
Split διαιρεί τον κόμβο
αυτόν σε δύο νέους κόμβους. Ο Guttman πρότεινε τρεις διαφορετικές μεθόδους διάσπασης με διαφορετικά κόστη εκτέλεσης:
τον Linear - Split, τον Quadratic - Split και τον Exhaustive - Split αλγόριθμο. Στην πράξη εφαρμόζονται οι δύο πρώτοι μόνο καθώς ο Εxhaustive - Split είναι πολύ αργός για
ρεαλιστικές εφαρμογές (απαιτεί τον υπολογισμό περίπου 2M πιθανών ομαδοποιήσεων για να επιλέξει την πιο κατάλληλη από αυτές).
Σημειώνουμε εδώ ότι το ίδιο κριτήριο (ελάχιστη αύξηση εμβαδού) χρησιμοποιείται
τόσο στους παραπάνω αλγορίθμους Split όσο και στον
αλγόριθμο ChooseSubtree που
παρουσιάσαμε προηγουμένως.
Εάν μελετήσουμε
τη διαδικασία αναζήτησης στο R - Τree θα συμπεράνουμε ότι οι παράγοντες κάλυψη
(coverage) και επικάλυψη (overlap) είναι σημαντικοί. Η κάλυψη για
ένα επίπεδο του R - Tree ορίζεται ως το συνολικό εμβαδόν όλων των ορθογωνίων που χαρακτηρίζουν τους
κόμβους του επιπέδου αυτού. Η επικάλυψη
για ένα επίπεδο του R - Tree ορίζεται ως το συνολικό εμβαδόν του χώρου που ανήκει σε δύο ή
περισσότερους επικαλυπτόμενους κόμβους. Είναι προφανές ότι η αποδοτική
αναζήτηση με τα R - Τrees προϋποθέτει ελαχιστοποίηση και των δύο παραγόντων. Η ελαχιστοποίηση της
κάλυψης συνεπάγεται μείωση της ‘νεκρής’ περιοχής (δηλαδή του κενού χώρου)
μεταξύ των κόμβων. Η ελαχιστοποίηση της επικάλυψης είναι ακόμη πιο σημαντική
για γρήγορη αναζήτηση: όταν το παράθυρο ερώτησης πέφτει μέσα στον κοινό χώρο k
επικαλυπτόμενων κόμβων στο επίπεδο h-l, h το ύψος του δέντρου, πρέπει να ακολουθηθούν, στη χειρότερη περίπτωση, k μονοπάτια προς
τα φύλλα (ένα μονοπάτι για κάθε έναν από τους επικαλυπτόμενους κόμβους), με
αποτέλεσμα την καθυστέρηση της διαδικασίας αναζήτησης. Για παράδειγμα, αν
θεωρήσουμε ένα παράθυρο ερώτησης που βρίσκεται στην κοινή περιοχή των κόμβων A και B του R-tree της εικόνας 24 και τα
δύο υποδένδρα που έχουν ως ρίζες τους κόμβους A και B πρέπει να ελεγχθούν,
έστω και αν ένα μόνο από αυτά περιλαμβάνει κάποια απάντηση στην ερώτηση.
13.4.3
Άλλες εκδοχές του R - Tree (Variations)
Ο αριθμός των παραλλαγών του R - Tree που έχουν εμφανιστεί στην βιβλιογραφία
είναι πολύ μεγάλος. Εμείς θα παρουσιάσουμε τις δύο πιο σημαντικές
παραλλαγές του R - Tree το R+ - Tree και το R* - Tree
R+ - Tree
Το R+ - Tree προτάθηκε από τους Sellis κ.α. στην εργασία
[Sell87] και μπορεί να θεωρηθεί ως μια επέκταση της δομής K-D-B - Tree για διαχείριση μη σημειακών αντικειμένων.
Οι κόμβοι του R+ - Tree σε κάθε επίπεδο, δεν
καλύπτουν υποχρεωτικά όλο το χώρο εργασίας. Από την άλλη πλευρά, σε αντίθεση με
το R - Tree, το R+ - Tree εγγυάται μηδενική επικάλυψη μεταξύ των
ενδιάμεσων κόμβων σε κάθε επίπεδο του δέντρου. Τα ορθογώνια που τέμνουν
περισσότερους από έναν κόμβους αποθηκεύονται (σε κατάλληλα κομμάτια) σε όλους
αυτούς τους κόμβους. Η δομή του μοιάζει με αυτή του R - Tree: οι τερματικοί κόμβοι είναι του τύπου (oid,
R) και οι ενδιάμεσοι κόμβοι είναι του τύπου (ptr, R).
Το R+ - Tree έχει τις ακόλουθες ιδιότητες:
- Για
κάθε στοιχείο (ptr, R) ενός τερματικού κόμβου, το υποδέντρο
που έχει ως ρίζα τον κόμβο στον οποίο δείχνει ο ptr περιέχει ένα
ορθογώνιο R’ εάν και μόνο εάν το R’ καλύπτεται πλήρως από το
R. Η μόνη εξαίρεση είναι όταν το R’ είναι ορθογώνιο
τερματικού κόμβου: σε τέτοια περίπτωση το R’ πρέπει απλά να τέμνει
το R.
- Για
κάθε ζεύγος στοιχείων (ptr1, R1) και (ptr2, R2)
ενός ενδιάμεσου κόμβου, η επικάλυψη μεταξύ των ορθογωνίων R1 και R2
ισούται με μηδέν.
- Η ρίζα
έχει τουλάχιστον δύο παιδιά εκτός εάν είναι φύλλο.
- Όλα τα
φύλλα βρίσκονται στο ίδιο επίπεδο του δέντρου.
Η λειτουργία
αναζήτησης είναι παρόμοια με αυτήν των R - Trees. Η κύρια διαφορά είναι ότι οι υποπεριοχές
των R+ - Trees δεν
επικαλύπτονται, οπότε έχουμε συνήθως γρηγορότερη αναζήτηση.
R* - Tree
Το R* - Tree παρόλο που προτάθηκε το 1990 θεωρείται
ακόμα και σήμερα ως μία κυριαρχική δομή όσον αφορά την απόδοση. Είναι μια παραλλαγή του R - Tree η οποία, σε αντίθεση με το R+ - Tree, δεν αλλάζει τις ιδιότητες της δομής, αλλά
χρησιμοποιεί έναν πολύπλοκο αλγόριθμο (forced reinsertion) για να οργανώσει τα ορθογώνια στους
κόμβους, επιτυγχάνοντας έτσι βελτιωμένη απόδοση. Όπως εξάγεται από τους
αλγόριθμους κατασκευής του R - Tree, η ελάχιστη αύξηση εμβαδού είναι το κριτήριο που αποφασίζει για τον
κόμβο που θεωρείται ως ο πιο κατάλληλος για την εκχώρηση ενός νέου στοιχείου
(αλγόριθμος ChooseSubtree) ή τον τρόπο με τον οποίο θα ομαδοποιηθούν σε δύο
κόμβους τα στοιχεία ενός κόμβου που υπερχειλίζει (αλγόριθμος Split). Το R* - Tree προτείνει συνδυασμούς περισσοτέρων
κριτηρίων: ελάχιστη αύξηση εμβαδού (area), ελάχιστη αύξηση περιμέτρου (margin)
και ελάχιστη αύξηση επικάλυψης (overlap).
13.4.4. Χρήσεις του R - Tree
Από τις πρώτες μελέτες του R - Tree ήταν φανερό ότι μπορούσε να βρει εφαρμογές σε
πολλά πεδία. Τρεις από τους σημαντικότερους τομείς που χρησιμοποιείται είναι τα
γεωγραφικά συστήματα πληροφορίας (GIS), ο τομέας σχεδίασης ολοκληρωμένων
κυκλωμάτων (σχεδίαση VLSI) και ο τομέας
σχεδίασης CAD.
Άλλα πεδία διαχείρισης μη παραδοσιακών δεδομένων
(πολυδιάστατων) που χρησιμοποιούν R – Tree είναι οι Βάσεις δεδομένων Εικόνων
και Πολυμέσων. Σε εφαρμογές Πολυμέσων, για παράδειγμα, τα αντικείμενα που
συμμετέχουν μπορούν να θεωρηθούν ως ορθογώνια παραλληλεπίπεδα στο τρισδιάστατο
χώρο-χρονικό (spatio-temporal) σύστημα συντεταγμένων, 3D R - Tree (δύο διαστάσεις για τη χωρική θέση του
αντικειμένου συν μία διάσταση για τη χρονική διάρκεια του) και, άρα, να
οργανωθούν με χρήση χωρικών δομών δεδομένων. Επιπλέον, χρησιμοποιείται στην
διαχείριση γεωδαιτικών δεδομένων
(geodetic data), δηλαδή δεδομένα που αντιπροσωπεύουν γεωγραφικό μήκος και
πλάτος. Τέλος, έχει ενσωματωθεί σε προτάσεις για ειδικευμένες γλώσσες
χωρικών ερωταποκρίσεων (π.χ. PSQL, Spatial SQL).
13.5 Εξωτερικά συμπεράσματα για
την απόδοση των αλγορίθμων
Για την απόδοση του Binary Search – Tree μιλήσαμε νωρίτερα, σχολιάζοντας και την χειρότερη περίπτωση λειτουργίας
του, στο σημείο αυτό θα σχολιάσουμε την απόδοση των χωρικών δομών δεδομένων που
μελετήσαμε, του Quad –
Tree και R – Tree. Άλλωστε δεν έχει νόημα η σύγκριση του Binary Search – Tree με χωρικές δομές δεδομένων.
Η απόδοση μιας χωρικής δομής δεδομένων
συνήθως αξιολογείται από την ικανότητα της να απαντά σε χωρικές ερωτήσεις. Στο
παρελθόν έχουν προταθεί αρκετές δομές που επιδιώκουν τη βέλτιστη ανάκτηση
τέτοιων ερωτήσεων, καμία από αυτές, όμως, δεν έχει αποδειχτεί ότι είναι ανώτερη
από τις υπόλοιπες για όλες τις περιπτώσεις. Αυτό οφείλεται στην ύπαρξη πολλών
παραμέτρων που καθορίζουν την αποδοτικότητα μιας δομής αλλά και στην έλλειψη
ενός τυποποιημένου δοκιμαστηρίου (testbed / benchmark) για χωρικές δομές
δεδομένων. Οι κύριοι παράγοντες που καθορίζουν την αποδοτικότητα μιας χωρικής
δομής δεδομένων :
·
Η
Πυκνότητα των δεδομένων : Αν τα δεδομένα
είναι κατανεμημένα πολύ αραιά η επιλογή της μεθόδου γίνεται λιγότερο σημαντική
·
Η
κατανομή των δεδομένων : Υπάρχει εξάρτηση,
το πού τίθεται ένα ερώτημα, σε σχέση με την κατανομή των δεδομένων.
·
Το
μέγεθος της γεωμετρίας : Εάν η γεωμετρία είναι μεγάλη σε σχέση με το ερώτημα
τότε η επιλογή της μεθόδου έχει λιγότερη σημασία.
·
Ευθυγράμμιση
της γεωμετρίας : το πώς η γεωμετρία είναι ευθυγραμμισμένη σε σχέση με του άξονες X και Y πιθανώς να
επηρεάσει την απόδοση της μεθόδου.
·
Το σχήμα
της γεωμετρίας : Εάν οι γεωμετρίες είναι συμμετρικές σε σχήμα (π.χ. ορθογώνιο) τότε η
μέθοδος R – Tree μπορεί να είναι
πιο αποτελεσματική.
·
Το
είδος του ερωτήματος : Για παράδειγμα τα R- Trees φαίνονται ιδιαίτερα αποτελεσματικά στα
ερωτήματα κοντινότερου γείτονα
Λίγα θεωρητικά αποτελέσματα ως προς την
απόδοση των R –Trees και Quad - Trees έχουν παρουσιασθεί σχετικά πρόσφατα, και τα οποία επικεντρώνονται τόσο
στα χαρακτηριστικά τους όσο και στην απόδοση τους σε χωρικές ερωτήσεις.
Τα συμπεράσματα τα οποία παρουσιάζουμε,
βασίζονται στην πλατφόρμα της Oracle η οποία έχει ενσωματώσει τις χωρικές δομές δεδομένων που μελετήσαμε:
- Τα Quad
Trees είναι μόνο για
αντικείμενα δύο διαστάσεων ενώ τα R-Trees για αντικείμενα μέχρι τεσσάρων
διαστάσεων στην υλοποίηση της Oracle, ενώ θεωρητικά μπορούν να χρησιμοποιηθούν και για περισσότερες
διαστάσεις.
- Τα Quad – Trees αποδίδουν αρκετά καλά σχεδόν για κάθε
είδους σύνολο δεδομένων. Αντίθετα υπάρχουν σύνολα δεδομένων στα οποία τα R – Trees δεν αποδίδουν καλά
- Το R – Tree απαιτεί λιγότερο αποθηκευτικό χώρο για
τη δομή, σε σχέση με τα Quad - Trees. Παρατήρηση: Εκτός αν πρόκειται για
σημειακά δεδομένα όπου δεν υπάρχει διαφορά.
- Τα R – Trees εκτελούν γρηγορότερα ερωτήματα
κοντινότερου γείτονα σε σχέση με Quad - Trees. Αυτό συμβαίνει, γιατί η μέθοδος R – Tree αποθηκεύει
τα χωρικά δεδομένα (δημιουργεί την δενδρική δομή) με βάση την τοποθεσία
των αντικειμένων, αυτός είναι και ο βέλτιστος τρόπος για ερωτήματα
κοντινότερου γείτονα. Επιπλέον, τα Quad – Trees δεν μπορούν
να απαντήσουν σε ερωτήματα αυξητικού κοντινότερου γείτονα (Incremental NN Query). Τέλος, η
απόδοση του Quad – Tree σε ερωτήματα κοντινότερου γείτονα,
κρίνεται πολύ υψηλή σε σχέση με άλλες δομές, όπως και η επίδοση τους σε
ορισμένες ερωτήσεις χωρικής διάσπασης, όπως για παράδειγμα Point-in-Polygon search.
- Τα R – Trees μπορούν να χρησιμοποιηθούν για
γεωδαιτικά δεδομένα (geodetic data), δηλαδή
δεδομένα που αντιπροσωπεύουν γεωγραφικό μήκος και πλάτος. Τα δεδομένα αυτά
συνήθως περιέχουν και μία τρίτη διάσταση για το λόγω αυτό τα Quad – Trees δεν προτείνονται για αυτού του τύπου τα δεδομένα.
- To R-Tree μπορεί να είναι αργό στις διαδικασίες
ενημέρωσης, εισόδου ή εξόδου των δεδομένων. Εάν η επίδοση στις παραπάνω
διαδικασίες είναι σημαντική το Quad – Tress είναι καλύτερη επιλογή, αφού εκτελεί
γρηγορότερα αυτές τις διαδικασίες.
- Αν γίνονται συνεχείς ενημερώσεις (updates) στα δεδομένα, τα R-Trees γίνονται
λιγότερο αποδοτικά. Αν για παράδειγμα έχουμε συνεχής προσθήκη δεδομένων με
το χρόνο το R – Tree θα χάσει την αποδοτικότατα του. Ένας τρόπος
για να ξεπεράσουμε το πρόβλημα αυτό είναι να ξανά δημιουργήσουμε το R – Tree από την
αρχή. Τα Quad – Trees συνεχίζουν να είναι αποδοτικά ακόμα και
μετά από πολλές ενημερώσεις.
Σε αυτή την παράγραφο
περιγράφεται ο αλγόριθμος συσχέτισης διαστάσεων KD-tree. Αρχικά δίνεται μια
γενική περιγραφή των βασικών ιδεών του αλγορίθμου και αναφέρονται διάφορα
ζητήματα γύρω από αυτόν. Στην συνέχεια αναλύονται οι λειτουργίες του και τέλος
το κεφάλαιο ολοκληρώνεται με την υλοποίηση του αλγορίθμου και την ανάλυση των
συναρτήσεων που χρησιμοποιήθηκαν.
13.6.1 Θεωρητική
προσέγγιση του KD-tree
Το K-διαστάσεων
δυαδικό δένδρο αναζήτησης (KD-tree) είναι μια ιδιαίτερα ευπροσάρμοστη μέθοδος,
που έχει γίνει θέμα πολλών ερευνών. Το δένδρο αυτό πρωτοπαρουσιάστηκε από τον
Bentley[13][14] το 1975. Υπάρχουν δύο ειδών κόμβοι στο KD-tree, οι
τερματικοί και οι εσωτερικοί. Οι εσωτερικοί έχουν δύο παιδιά, το δεξί και το
αριστερό. Τα παιδιά αυτά αντιπροσωπεύουν ένα διαμέρισμα μίας εκ των Ν
διαστάσεων του επιπέδου. Τα σημεία της μίας πλευράς του υπο-δένδρου
αποθηκεύονται στο αριστερό υποδένδρο και τα υπόλοιπα στο δεξί. Οι κόμβοι
τερματισμού περιέχουν ένα σημείο ή περισσότερα. Το μονοδιάστατο KD-tree είναι
στην ουσία ένας απλός αλγόριθμος, ο quick-sort.
13.6.2 Ταξινόμηση με τη μέθοδο KD-tree
Η κατασκευή του
KD-tree ξεκινά, βρίσκοντας πρώτα ποια από τις διαστάσεις (ποιος άξονας) έχει τη
μεγαλύτερη διασπορά -δηλαδή τη μεγαλύτερη διαφορά μεταξύ του μέγιστου και του
ελάχιστου- και ορίζεται ως άξονας αποκοπής. Έπειτα γίνεται ταξινόμηση κατά
μήκος αυτού του άξονα στα σημεία του πρώτου κόμβου. Εκτελείται ένας αλγόριθμος
γρήγορης επιλογής σε χρόνο Μ για Μ σημεία και βρίσκει τον μέσο των σημείων
αυτών (τιμή αποκοπής). Ακολουθεί η ταξινόμηση των δεδομένων στα φύλλα με τρόπο
τέτοιο, ώστε αυτά που είναι μεγαλύτερα από τον μέσο, να πηγαίνουν στο ένα κλαδί
(δεξί) και τα υπόλοιπα στο άλλο (αριστερό). Έτσι καταφέρνουμε να χωρίζουμε τα
δεδομένα μας σε δυο μικρότερα ισομεγέθη σετ. Αυξάνεται ο άξονας αποκοπής κατά
ένα και ακολουθεί η ίδια διαδικασία για κάθε κόμβο ώστε να καθοριστεί ποια
σημεία βρίσκονται στους κόμβους-παιδιά. Όταν ο αριθμός των σημείων δεδομένων
που περιέχονται σε κάθε κόμβο είναι μικρότερος ή ίσος αυτών που αρχικά
καθορίσαμε, η διαδικασία σταματά. Συνήθως ο αριθμός αυτός είναι ένα σημείο σε
κάθε φύλλο. Παρακάτω ακολουθεί ο ψευδοκώδικας της ταξινόμησης και ένα
παράδειγμα που δείχνει τον τρόπο με τον οποίο τα σημεία στο επίπεδο
αντιστοιχούν στο KD-δένδρο (Εικόνα 13.24 και Εικόνα 13.25)
Ψευδοκώδικας Ταξινόμησης KD-tree:
1. Έλεγχος εάν ο points είναι κενός.
2. points:= πίνακας σημείων
3. Ν:= πλήθος σημείων του points
4. level=1
5. axis:= Εύρεση άξονα (διάστασης) με τη μεγαλύτερη
διασπορά.
6. median:= μέσος του points κατά τη διάσταση axis.
7. Για level από 1 έως log2N
Για κάθε τιμή d της τρέχουσας διάστασης
(axis) του points
i. d (left_sub_tree:= αν d≤median
ii. d( right_sub_tree:= αν d>median
iii. axis++
iv. level++
Εικόνα 13.24 Σημεία χωρισμένα με τη μέθοδο KD-tree
Εικόνα 13.25 To KD-δένδρο που προκύπτει από την ταξινόμηση των σημείων
13.6.3 Αναζήτηση
κοντινότερης γειτονιάς
Η αναζήτηση
κοντινότερης γειτονιάς μπορεί να επιτευχθεί με δύο τρόπους.
• Μπορεί να πραγματωθεί, ως μια από πάνω προς τα κάτω
επαναλαμβανόμενη διαδικασία που διασχίζει το δένδρο. Σε κάθε κόμβο, ο κόμβος
που αναζητούμε συγκρίνεται με την τιμή αποκοπής κατά τον άξονα αποκοπής. Εάν το
ζητούμενο σημείο είναι μικρότερο από την τιμή αποκοπής, τότε κατεβαίνουμε στο
αριστερό φύλλο, αλλιώς πάμε στο δεξί. Όταν φτάσουμε σε ένα κόμβο, όλα τα σημεία
του κόμβου συγκρίνονται για να διαπιστωθεί εάν κάποιο από αυτά είναι
κοντινότερο από την ήδη κοντινότερη γειτονιά μας. Όταν το «κατέβασμα»
ολοκληρωθεί, σε κάθε κόμβο που βρέθηκε, αν η απόσταση της κοντινότερης γειτονιάς
που βρέθηκε είναι μεγαλύτερη της απόστασης αποκοπής, τότε θα πρέπει να
προσπελαστεί το άλλο παιδί του κόμβου. Η αναζήτηση σταματά όταν δεν χρειάζεται
να προσπελαστούν άλλα κλαδιά.
• Ο Bentley συνιστά τη χρήση κόμβων-γονέων για
κάθε κόμβο στη δομή δένδρου. Η αναζήτηση τότε μπορεί να πραγματοποιηθεί
χρησιμοποιώντας από κάτω προς τα πάνω προσπέλαση, ξεκινώντας με τον κόμβο που
περιέχει το ζητούμενο σημείο και ψάχνοντας σε μικρό αριθμό κόμβων μέχρι οι
κατάλληλες γειτονιές να βρεθούν. Για αναζητήσεις κοντινότερης γειτονιάς o
χρόνος υπολογισμού μειώνεται από O(logM) σε O(1).
Δοκιμές των δυο
τρόπων (πάνωκάτω και κάτωπάνω) δείχνουν ότι οι διαφορές σε ταχύτητα είναι αμελητέες.
Αυτό συμβαίνει επειδή η περισσότερη υπολογιστική ισχύ, σπαταλάται σε υπολογισμούς
απόστασης και ο μειωμένος αριθμός υπολογισμών είναι αμελητέος.
Στο πρόγραμμα,
χρησιμοποιήθηκε ο δεύτερος τρόπος αναζήτησης κοντινότερης γειτονιάς (κάτω-πάνω), ανεβαίνοντας
όμως κατά ένα κόμβο μόνο. Αυτού του είδους η αναζήτηση είναι η πιο γρήγορη, αλλά
κρύβει κάποια παγίδα. Το σημείο που βρίσκεται στον ίδιο κόμβο – πατέρα με το
σημείο που αναζητούμε, δεν είναι αναγκαία και το κοντινότερο. Το παράδειγμα της
Εικόνας 13.26 αναπαριστά μια κακή κατανομή και αποδεικνύει τα παραπάνω.
Παρατηρήστε ότι το σημείο 9 με το σημείο 10 ανήκουν στον ίδιο κόμβο – πατέρα (Εικόνα
13.25), αλλά κοντινότερο του 9 είναι το σημείο 11.
Εικόνα 13.26 Αναζήτηση
κοντινότερου γείτονα
13.6.4 Αναζήτηση με χρήση
ακτίνας
Η αναζήτηση με
χρήση ακτίνας επιστρέφει όλα τα σημεία που βρίσκονται εντός μιας συγκεκριμένης
ακτίνας από το σημείο του οποίου ψάχνουμε τους κοντινότερους γείτονες. Και αυτή
η αναζήτηση γίνεται από κάτω προς τα πάνω στη δομή του δένδρου. Ξεκινά με τον
κόμβο που περιέχει το ζητούμενο σημείο και ψάχνει ανεβαίνοντας ορισμένα επίπεδα
στο δένδρο, εωσότου να συγκεντρωθεί ένας αριθμός σημείων. Τον αριθμό των
επιπέδων που θα ανεβούν, τον καθορίζει ο χρήστης. Έχοντας τώρα τα σημεία αυτά,
εξετάζει εάν η Ευκλείδεια απόσταση τους από το ζητούμενο σημείο είναι ίση ή
μικρότερη της ακτίνας. Η αναζήτηση ολοκληρώνεται επιστρέφοντας τα σημεία που
βρίσκονται εντός της ακτίνας αυτής.
Έστω ότι έχουμε τα
σημεία της Εικόνας 13.24 και επιθυμούμε να βρούμε τα σημεία που
βρίσκονται σε ακτίνα Ν από το σημείο 9. Κάνοντας αναζήτηση βάθους ενός επιπέδου,
(δηλαδή να ανεβούμε ένα επίπεδο πάνω, στη δομή του δένδρου), το μόνο σημείο που
θα βρεθεί είναι το σημείο 10. Αυτό συμβαίνει, επειδή η μέχρι τώρα περιοχή που
ελέγχεται είναι αυτή με το πορτοκαλί χρώμα στην Εικόνα 13.27. Θα
μετρηθεί η ευκλείδεια απόσταση μεταξύ του σημείου 9 και του σημείου 10, και
αφού διαπιστωθεί ότι το 10 βρίσκεται εντός ακτίνας, θα επιστραφεί ως το
μοναδικό αποτέλεσμα.
Εικόνα 13.27 Αναζήτηση με χρήση
ακτίνας βάθους ενός επιπέδου
Με αναζήτηση βάθους
δύο επιπέδων, η πορτοκαλί περιοχή μεγαλώνει και τα σημεία που περιέχονται σε
αυτή, τώρα είναι περισσότερα (Εικόνα 13.27). Έτσι εφαρμόζεται ξανά η
ευκλείδεια απόσταση και διαπιστώνεται ότι τα σημεία 10, 5 και 14 είναι εντός
ακτίνας. Προσέξτε ότι το σημείο 11, παρόλο που είναι το κοντινότερο στο σημείο
9, δεν έχει συμπεριληφθεί ακόμα στα αποτελέσματα της αναζήτησης. 
Εικόνα 13.28 Αναζήτηση με χρήση
ακτίνας βάθους δύο επιπέδων
Προχωρώντας σε
αναζήτηση βάθους τριών επιπέδων η περιοχή μεγαλώνει ακόμα περισσότερο. Αυτή τη φορά,
οχτώ σημεία βρίσκονται μέσα στην περιοχή, δηλαδή οχτώ σημεία πρέπει να
εξεταστούν εάν βρίσκονται εντός ακτίνας. Όπως φαίνεται στην Εικόνα 13.27,
τα σημεία 5, 10, 11 και 14, βρίσκονται εντός ακτίνας, και τα σημεία 6, 8 και 12
βρίσκονται εκτός, οπότε δεν θα συμπεριληφθούν στα αποτελέσματα
13.7 Box assisted
Ο Box assisted (Εικόνα
13.29) δεν είναι δενδρική δομή όπως οι προηγούμενοι, αλλά στηρίζεται στη
χρήση πλέγματος (grid). Τοποθετεί δηλαδή ένα πλέγμα πάνω στο επίπεδο και προσδιορίζει
ποια σημεία βρίσκονται σε κάθε κουτί (box) του πλέγματος. Για να βρει
πληροφορίες για ένα συγκεκριμένο σημείο, αρκεί να εξετάσει σε ποιο κουτί
βρίσκεται.
Εικόνα 13.29 Παράδειγμα Box
assisted
Κεφάλαιο
14. Σύνδεση βάσεων δεδομένων με εφαρμογές.
Στο κεφάλαιο αυτό παρουσιάζονται οι πιο
δημοφιλής τρόποι σύνδεσης βάσεων δεδομένων με γλώσσες προγραμματισμού μέσω ODBC, DAO, ADO κλπ . Με
τους τρόπους αυτούς επιτυγχάνεται η ανεξαρτησία μεταξύ βάσεων δεδομένων και
εφαρμογών καθώς η μέγιστη δυνατή επικοινωνία μεταξύ τους. Επίσης αναφέρονται τα
βασικά χαρακτηριστικά των τριών σημαντικότερων RDBMS, του SQL Server, της Oracle και της My SQL. Στο τέλος
αναφέρονται τρόποι ανάθεσης δικαιωμάτων πρόσβασης στους χρήστες μιας
βάσης.
Όταν ένας προγραμματιστής αποφασίσει να υλοποιήσει μία εφαρμογή η οποία θα επικοινωνεί με μία βάση δεδομένων καλείται να αποφασίσει με ποιόν τρόπο θα επιτύχει αυτή την επικοινωνία.
Διαχρονικά έγιναν πολλές προσπάθειες για να επιτευχθεί η ανεξαρτησία μεταξύ εφαρμογών και βάσεων δεδομένων. Πολλές εταιρείες της πληροφορικής παρουσίασαν τους δικούς τους τρόπους και συναρτήσεις επικοινωνίας με βάσεις δεδομένων αλλά δεν καθιερώθηκαν όλοι αυτοί οι τρόποι.
Στην Εικόνα 14.1 παρουσιάζονται οι πιο γνωστοί τρόποι πρόσβασης σε βάσεις δεδομένων και θα εξηγήσουμε τους σημαντικότερους από αυτούς και ειδικότερα θα δώσουμε μεγαλύτερη έμφαση στο ODBC, BDE, DAO, RDO, OLE DB, JDBC και ADO. Από τους τρόπους αυτούς έχουν επικρατήσει το ODBC, JDBC και ADO.

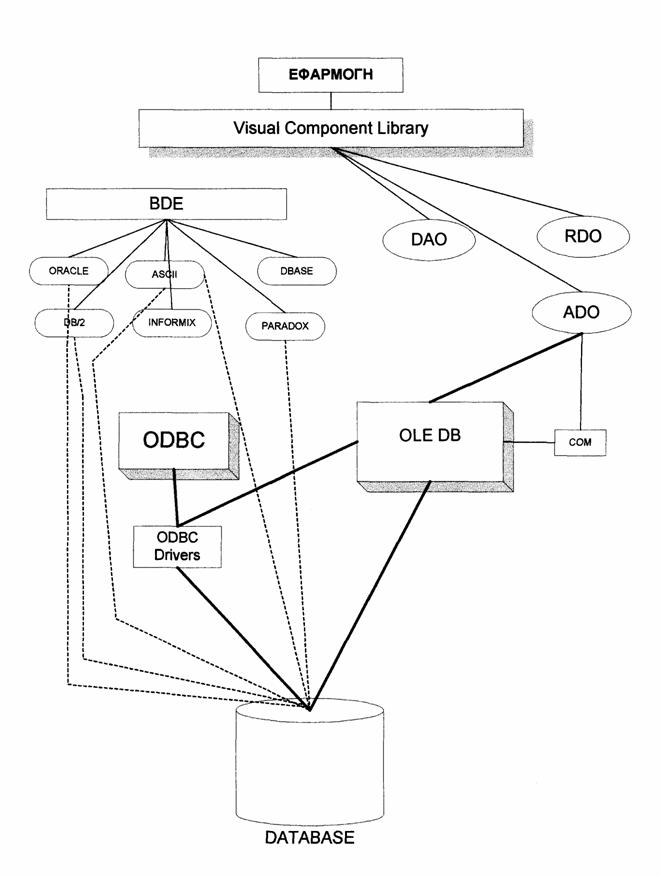
Εικόνα
14.1. Επικοινωνία μεταξύ Βάσεων Δεδομένων και
εφαρμογών.
Το 1991 η Microsoft παρουσίασε μια νέα μέθοδο για πρόσβαση σε δεδομένα που καλείται ODBC (Open Database Connectivity), ανοιχτή συνδεσιμότητα βάσεων δεδομένων. Το ODBC δίνει στους προγραμματιστές την δυνατότητα να έχουν πρόσβαση σε κάποιους από τους διαφορετικούς τύπους πηγών δεδομένων. Η μέθοδος αυτή έγινε γνωστή μεταξύ των προγραμματιστών της C και της C++ και στην πραγματικότητα υιοθετήθηκε σαν ένα διεθνές πρότυπο.
Όταν ένας προγραμματιστής θέλει να έχει πρόσβαση στις υπηρεσίες βάσεων δεδομένων μέσα από τον κώδικα του πρέπει να μάθει πώς να χειρίζεται τη βάση. Αυτό δεν είναι τόσο δύσκολο γιατί οι περισσότερες βάσεις παρέχουν βιβλιοθήκες που μπορεί να ενσωματωθούν στο πρόγραμμα. Αυτά ισχύουν με την προϋπόθεση ότι χρησιμοποιείται μία συγκεκριμένη βάση. Τη στιγμή που υπάρξει ανάγκη για πρόσβαση σε μία διαφορετική βάση δεδομένων, ο εκάστοτε προγραμματιστής, όχι μόνο θα πρέπει να μάθει ένα σύνολο από εντολές και διαδικασίες, αλλά θα πρέπει να αλλάξει τα σενάρια (script) έτσι ώστε να προσαρμοστεί με τη νέα βάση. Αυτό συνήθως σημαίνει να ξαναγραφτεί όλος ο κώδικας από την αρχή. Υποθέτουμε όμως ότι πρέπει να γίνει μία εφαρμογή βάσεων δεδομένων που θα δουλεύει με οποιοδήποτε ΒΔ έχει ο πελάτης. Αν είναι γνωστό ποια βάση χρησιμοποιεί ο πελάτης θα χρειαστεί να γραφούν πολλές παραλλαγές του ίδιου σεναρίου για να υπάρχει δυνατότητα χειρισμού όλων των πιθανών ΒΔ. Αν αυτό δεν αρκεί απλά φανταστείτε πως θα ήταν να συντηρηθούν όλα αυτά τα πιθανά σενάρια. Θα ήταν καλύτερα λοιπόν να χρησιμοποιείται ένα σενάριο που θα λειτουργούσε σε όλα τα συστήματα βάσεων δεδομένων. Εδώ είναι που εισέρχεται το ODBC (open database connectivity), ανοιχτή συνδεσιμότητα βάσεων δεδομένων.
Το ODBC είναι μία πρωτοβουλία που η βιομηχανία των βάσεων την έχει δεχτεί ως τη πλέον τυποποιημένη διεπαφή. Η Microsoft ήταν υπέρ του συγκεκριμένου API και ήταν μία από τις πρώτες εταιρίες που εργάστηκαν για την υλοποίηση του. Παρόλα αυτά η προγραμματιστική τυποποίηση της διεπαφής σχεδιάστηκε από μία κοινοπραξία οργανισμών όπως X/Open SQL Access Group, ANSI, ISO και διάφορες εταιρίες πληροφορικής όπως IBM, Novell, Oracle, Sybase, Digital, και Lotus. To πρότυπο σχεδιάστηκε να είναι ένα ανεξάρτητο σύνολο προδιαγραφών και υλοποιήθηκε στο Win32, UNIX, Macintosh, και OS/2 λειτουργικό σύστημα. To ODBC είναι πλέον ευρέως αποδεκτό σε τέτοιο σημείο που μερικοί κατασκευαστές όπως IBM, Informix, και Watcom σχεδίασαν τις δικές τους βάσεις δεδομένων βασιζόμενοι στο ODBC
Η ανοικτή συνδεσιμότητα βάσεων δεδομένων (ODBC) είναι μια διεπαφή για την πρόσβαση των δεδομένων ακόμη και σε ένα ετερογενές περιβάλλον των σχεσιακών συστημάτων διαχείρισης βάσεων δεδομένων. Ακόμα κι αν το ODBC έχει την υποστήριξη της βιομηχανίας, έχουν εμφανιστεί διάφορες αναφορές κακής απόδοσης από τους επαγγελματίες, τους αναλυτές, μηχανικούς κά. Οι περισσότερες από αυτές τις αναφορές είναι βασισμένες στην έλλειψη κατανόησης της αρχιτεκτονικής του ODBC, ανάρμοστη χρήση του ODBC μέσα στις εφαρμογές, και στους μη βελτιστοποιημένους οδηγούς (drivers) ODBC.
Πολλοί αναλυτές καθώς και ανεξάρτητοι προμηθευτές λογισμικού (ISVs), θεωρούν ότι η απόδοση της ανοικτής συνδεσιμότητας βάσεων δεδομένων (ODBC) είναι χαμηλή.
Η αντίληψη αυτή είναι λανθασμένη και οφείλεται σε μεμονωμένες περιπτώσεις κατασκευαστών οδηγών ODBC που δεν δώσανε μεγάλη προσοχή στον σχεδιασμό των οδηγών αυτών. Μερικοί δεν βελτιστοποιήθηκαν και κάλυψαν έτσι ολόκληρο το ζήτημα απόδοσης.
Επίσης μια ακατάλληλη επιλογή των εργαλείων ανάπτυξης πιθανόν να μειώσει το επιθυμητό επίπεδο λειτουργίας της εφαρμογής.
Περαιτέρω σύγχυση προκλήθηκε από τις θεωρίες πολλών αναλυτών. Υποθέτουν ότι επειδή το ODBC προσθέτει περισσότερα επίπεδα, είναι επομένως πιο αργό από ότι χρησιμοποιώντας μια αυτοσχέδια διεπαφή επικοινωνίας με ΒΔ. Ενώ μερικοί οδηγοί προσθέτουν επιπλέον επίπεδα με τη καταγραφή στην αυτοσχέδια διεπαφή, άλλοι οδηγοί, όπως ο Microsoft SQL Server, προσπερνούν την αυτοσχέδια διεπαφή και στέλνουν εντολές άμεσα στο πρωτόκολλο βάσεων δεδομένων. Ακόμη και με την χρήση περισσοτέρων επιπέδων ο επιπλέον φόρτος σε μια δικτυακή εφαρμογή τύπου client-server μεταθέτει προς την πλευρά του server, τον φόρτο από οποιονδήποτε client μειώνοντας έτσι τη έννοια της συνολικής απόδοσης. Για τον λόγο αυτό η χρήση περισσοτέρων επιπέδων δεν θεωρείται ότι παρέχει σημαντική μείωση στην απόδοση.
Μερικοί δημιουργοί έχουν ανακοινώσει ότι η απόδοση του ODBC είναι χαμηλή. Αναφέρουν την έλλειψη στατικής υποστήριξης SQL (δομημένη γλώσσα ερωτημάτων) στο ODBC ως αιτία της κακής απόδοσης. Χωρίς αυτό το χαρακτηριστικό γνώρισμα καταλήγουν στο συμπέρασμα ότι το ίδιο επίπεδο απόδοσης δεν μπορεί να επιτευχθεί.
Υπάρχει βέβαια και ο αντίθετος ισχυρισμός. Δηλαδή ότι η απόδοση ODBC είναι πάντα ίδια εάν όχι καλύτερη από όλες τις άλλες λύσεις είναι ψεύτικος. Υπάρχουν μερικές περιπτώσεις όπου το ODBC μπορεί να είναι πιο αργό. Παραδείγματος χάριν, ανάλογα με την εφαρμογή του οδηγού για τη φόρτωση και τη σύνδεση, το ODBC μπορεί να πάρει περισσότερο χρόνο για να συνδέσει με την πηγή δεδομένων από ότι χρησιμοποιώντας ένα ιδιόκτητο API. Αυτό έχει σχέση με την δουλειά που γίνεται από κάτω κατά τη διάρκεια της σύνδεσης προκειμένου να υποστηριχθούν οι ικανότητες του ODBC.
Συγκεκριμένα, απαιτείται κάποιος ο χρόνος για το διαχειριστή οδηγών ώστε να φορτώσει τον οδηγό DLL (δυναμική βιβλιοθήκη -σύνδεσης). Αυτή η χρονική περίοδος ποικίλει ανάλογα με τη σειρά που πρέπει να φορτωθούν τα τμήματα οδηγών, όπως τα όρισε ο προγραμματιστής.
Μπορείτε να θεωρήσετε το ODBC σαν ένα μηχανισμό μετάφρασης για τα συστήματα προγραμματισμού εφαρμογών (API) διαφόρων DBMS. Οποιοσδήποτε κατασκευαστής μπορεί να παρέχει ένα πρόγραμμα οδήγησης (driver) για το σύστημα DBMS που κατασκευάζει έτσι ώστε να μπορεί να χρησιμοποιηθεί σαν μια πηγή δεδομένων ODBC (ODBC data source). Ουσιαστικά σήμερα όλα τα συστήματα DBMS έχουν ένα πρόγραμμα οδήγησης ODBC,
Το πρότυπο ODBC επιτυγχάνει την ανεξαρτησία από το υποκείμενο DBMS παρεμβάλλοντας δυο επίπεδα πριν από το επίπεδο που αντιστοιχεί στο λογισμικό DBMS. Το πρώτο επίπεδο παρέχει ένα στάνταρ API για το οποίο οι εφαρμογές μπορούν να είναι σίγουρες ότι θα είναι συνεπές. Αυτό είναι το client πρόγραμμα ODBC. To δεύτερο επίπεδο είναι το πρόγραμμα οδήγησης που εκτελεί την μετάφραση.
14.2 Borland Database Engine (BDE)
To Borland Database Engine είναι ένα επίπεδο ακριβώς κάτω από την βιβλιοθήκη VCL (Visual Component Library) και είναι ανεξάρτητο από την γλώσσα προγραμματισμού. Η Borland το δημιούργησε με στόχο να επιτρέψει την απρόσκοπτη συνεργασία διαφόρων μορφών βάσεων δεδομένων με τα εργαλεία προγραμματισμού της.
Οι μορφές που υποστηρίζει είναι οι εξής :
Αυτόνομες βάσεις δεδομένων : ASCII delimited (κείμενο), xBase, Paradox, Βάσεις δεδομένων client/server : Oracle , Interbase , Sybase και άλλες, Open Database Connectivity (ODBC). Μμε το ODBC υπάρχει δυνατότητα υποστήριξης πολλών άλλων μορφών (π.χ. Access) επειδή είναι ένα πρότυπο της Microsoft και κατά συνέπεια έχουν δημιουργηθεί προγράμματα οδήγησης σχεδόν για όλατα DBMS που υπάρχουν.
To BDE επιτρέπει να χρησιμοποιούνται πολύ διαφορετικές μορφές βάσεων δεδομένων χωρίς να υπάρχει υποχρέωση για αγορά νέων συστατικών. Σε πολλές περιπτώσεις είναι εύκολο να χρησιμοποιηθούν διαφορετικά DBMS με την ίδια εφαρμογή. Ταυτόχρονα ένα επιπλέον χαρακτηριστικό είναι η δυνατότητα για ετερογενείς ενώσεις ΒΔ. Οι ετερογενείς ενώσεις δίνουν την δυνατότητα ένωσης πινάκων δεδομένων που προέρχονται από διαφορετικά συστήματα βάσεων δεδομένων κάτι το οποίο δεν έχουν καταφέρει να παρέχουν ακόμη άλλες τεχνολογίες .
To BDE κρύβει την πολυπλοκότητα πολλών ισχυρών χαρακτηριστικών και λειτουργιών όπως οι συναλλαγές, οι τοπικά αποθηκευμένες ενημερώσεις και η XML. Ουσιαστικά αυτό που έχει σημασία είναι ότι επιτρέπει την επικέντροση στα δεδομένα που πρέπει να ανακτηθούν και όχι στον τρόπο με τον οποίο θα ανακτηθούν.
To BDE κάνει πιο απλή την διαδικασία σύνδεσης σε μια βάση δεδομένων, επιτρέποντας στα συστατικά BDE της βιβλιοθήκης VCL να αναφέρονται απλώς σε ένα ψευδώνυμο . Το ψευδώνυμο είναι ένα όνομα το οποίο ορίζει ο δημιουργός της εφαρμογής ή αυτός που την εγκαθιστά χρησιμοποιώντας το εργαλείο διαχείρισης του BDE για τον συσχετισμό του ονόματος αυτού, με ένα πρόγραμμα οδήγησης βάσεων δεδομένων. Στην συνέχεια κάνει τις περαιτέρω ρυθμίσεις, συμπεριλαμβανομένων και αυτών που προσδιορίζουν την θέση της ίδιας της βάσης δεδομένων. Όπως είναι αναμενόμενο για όλες αυτές τις δυνατότητες υπάρχει ένα αντίτιμο. To BDE είναι λίγο ακριβό όσος αφορά στην κατανάλωση μνήμης και χώρου στον δίσκο.
Τέλος το BDE μπορεί να χρησιμοποιηθεί είτε για την ανάπτυξη αυτόνομων εφαρμογών (αρχιτεκτονική μίας βαθμίδας) αλλά και για την ανάπτυξη εφαρμογών client/server (δυο βαθμίδων).
Εφαρμογές με αρχιτεκτονική
μίας βαθμίδας
Η αρχιτεκτονική μίας βαθμίδας είναι ιδανική για προγράμματα για τα οποία η απόδοση και η τιμή είναι δύο παράγοντες πιο σημαντικοί από την ισχύ του DBMS ή την ακεραιότητα και την ασφάλεια των δεδομένων. Μια αυτόνομη βάση δεδομένων ενός χρήστη μπορεί να αυξήσει σημαντικά την ευελιξία ενός προγράμματος με χαμηλό κόστος.
Πλεονεκτήματα
Η χρήση οποιασδήποτε από τις προαναφερθείσες μορφές θα δώσει σαν αποτέλεσμα
την βέλτιστη δυνατή απόδοση όταν χρησιμοποιείται η βιβλιοθήκη VCL.
Πολλές από τις προαναφερθείσες μορφές είναι απαλλαγμένες από δικαιώματα και
μπορούν να χρησιμοποιούνται ελεύθερα.
Η xBase είναι μία δημοφιλής μορφή στο κόσμο των PCs και αναγνωρίζεται από τις περισσότερες εφαρμογές που επιτρέπουν εισαγωγή δεδομένων. Η εναλλαγή μεταξύ διαφορετικών μορφών είναι σχετικά εύκολη υπόθεση. Δεν υπάρχει ανάγκη αγοράς και εκμάθησης νέων συστατικών βιβλιοθηκών
Μειονεκτήματα
Καμία από τις προαναφερθείσες μορφές δεν παρέχει καλή ασφάλεια ή εγγενή υποστήριξη της ακεραιότητας των δεδομένων. Η χρήση τους σε περιβάλλον δικτύου ή σε περιβάλλοντα πολλαπλών χρηστών απαιτεί εξαιρετική προσοχή και σε ορισμένες περιπτώσεις είναι επικίνδυνη επειδή κάθε εφαρμογή ενημερώνει απευθείας τους πίνακες και είναι πολύ πιθανόν οι ενημερώσεις αυτές να αντικαθιστούν η μία την άλλη.
Πλεονεκτήματα χρήσης ODBC και BDE
To ODBC είναι ένα ευρέως αποδεκτό πρότυπο.
Μπορεί να συνεργάζεται με το BDE και δεν απαιτεί αλλαγές στο πρόγραμμα κατά την εναλλαγή μεταξύ των BDE ή των προγραμμάτων οδήγησης ODBC πράγμα το οποίο παρέχει σημαντική ευελιξία.
Επιτρέπει στην ίδια την εφαρμογή να δουλεύει ουσιαστικά με οποιαδήποτε βάση δεδομένων, ανεξάρτητα από την μορφή της (υπό τον όρο ότι υπάρχει ένα πρόγραμμα οδήγησης ODBC για αυτήν.)
Μπορεί να μετατρέψει μία εφαρμογή η οποία κατά τα άλλα θεωρείται σαν "μιας βαθμίδας" σε εφαρμογή client/server.
Δεν υπάρχει ανάγκη αγοράς και εκμάθησης νέων συστατικών /βιβλιοθηκών
Μειονεκτήματα χρήσης ODBC και BDE
Όταν χρησιμοποιούνται σε συνδυασμό τα BDE και ODBC, αυξάνονται σημαντικά οι απαιτήσεις σε χώρο δίσκου και μνήμης πράγμα το οποίο μπορεί να μειώσει την απόδοση. Επιπλέον σ' αυτήν την περίπτωση υπάρχουν τρία επίπεδα ανάμεσα στο πρόγραμμα και στο DBMS.
Ορισμένα προγράμματα οδήγησης ODBC δεν είναι όσο εύρωστα θα έπρεπε. Είναι πολύ σημαντικό να ελέγχεται το πρόγραμμα οδήγησης που σκοπεύετε να χρησιμοποιήσετε πριν δεσμευτείτε σε αυτήν την αρχιτεκτονική.
Η αναβάθμιση δεν είναι εύκολη υπόθεση .Η εφαρμογή, και οι βασιζόμενες στο ODBC εφαρμογές, πρέπει να ενημερώνονται ανεξάρτητα σχετικά με τα προγράμματα οδήγησης ODBC.
14.3 DAO (Data Access
Objects)
Για τους πρώτους δημιουργούς της visual basic ο μόνος ολοκληρωμένος τρόπος για πρόσβαση δεδομένων ήταν μέσω του DAO. Φυσικά προμηθευτές τρίτων πρόσφεραν εναλλακτικές λύσεις και σε κάποιες περιπτώσεις περισσότερο αποδοτικές λύσεις όπως το ODBC.
To DAO ήταν η πρώτη αντικειμενοστραφής διεπαφή που βασίζεται στον μηχανισμό JET μια έμφυτη μηχανή δεδομένων για την βάση δεδομένων Microsoft Access. To DAO αρχικά πρόσφερε ένα σύνολο αντικειμένων που μας επέτρεπαν να φτάσουμε στα δεδομένα. Αυτά τα αντικείμενα αντιπροσώπευαν μέρη μιας βάσης δεδομένων όπως πίνακες, ερωτήματα και άλλα στα οποία θα χρειαζόταν να υπαρχει πρόσβαση. Σχεδιαστικά το DAO μας δίνει το πιο γρήγορο και πιο απλό μέσο χειρισμού της Access επειδή τα αντικείμενα του μοντέλου αντικειμένων DAO είναι όμοια με τα αντικείμενα που βρίσκουμε σε μια βάση δεδομένων Access.
Επίσης το DAO ήταν πολύ χρήσιμο επειδή είχε πρόσβαση σε απόμακρες πηγές δεδομένων (όπως η βάση δεδομένων Oracle ή SQL Server). Η σύνδεση μέσω του ODBC με μια βάση δεδομένων client - server όπως η Microsoft SQL Server δεν αντιμετωπίστηκε με τρόπο client - server. Για παράδειγμα σε μια πρόσβαση δεδομένων ενός συστήματος client - server τα ανακτημένα δεδομένα από την βάση δεδομένων αναλύονται στον server και τότε ο client δέχεται μόνο τα δεδομένα που ζητήθηκαν αρχικά. Εντούτοις όταν το DAO ανακτά δεδομένα από τον SQL Server ο μηχανισμός JET παίρνει όλα τα δεδομένα και μετά τα αναλύει όλα στο μηχάνημα του client. Στη συνέχεια το DAO εισήγαγε το ODBCDirect για να βοηθήσει με την συνδεσιμότητα του το ODBC. To ODBCDirect είναι ένας τρόπος σύνδεσης σε μια βάση δεδομένων ODBC που παρακάμπτει το μηχανισμό JET. To ODBCDirect επιτράπηκε για έναν αποδοτικότερο μηχανισμό επικοινωνίας κατά την σύνδεση με τις βάσεις δεδομένων όπως η Oracle και SQL Server.
14.4 RDO (Remote Data
Objects)
RDO (Remote Data Objects) είναι μία αντικειμενοστραφής διεπαφή η οποία επιτρέπει να την πρόσβαση στις βάσεις δεδομένων του Microsoft SQL Server και της Oracle χωρίς την διέλευση μέσα από τον μηχανισμό JET. To RDO είναι ένα σύνολο αντικειμένων που ενσωματώνει το ODBC καλύτερα από ότι το ενσωματώσει ο μηχανισμός JET. Από τότε που το JET έπεψε να χρησιμοποιείται, η πρόσβαση σε πηγές δεδομένων του ODBC δεν απαιτεί την πρόσθετη μετάφραση και αυτό έχει σαν αποτέλεσμα την γρηγορότερη ανάκτηση δεδομένων.
To RDO βοήθησε να γίνονται πιο γρήγορα άμεσες κλήσεις στο ODBC Application Programming Interface (API). Ήταν απλό στην χρήση και ήταν βασισμένο σε ένα πρότυπο αντικείμενου τύπου COM - based. Έτσι το RDO είναι περιορισμένο γιατί δεν είναι πολύ αποτελεσματικό όταν έχει πρόσβαση σε πηγές δεδομένων τύπου JET και ISAM και η πρόσβαση σε σχεσιακές βάσεις δεδομένων μπορεί να γίνει μόνο μέσω υπαρχόντων ODBC οδηγών. Παρ' όλα αυτά το RDO αποδείχτηκε ότι ήταν η καλύτερη επιλογή για ένα μεγάλο αριθμό σχεσιακών βάσεων δεδομένων όπως SQL Server, Oracle.
1.1
14.5 ADO
Ο όρος ADO είναι
το ακρωνύμιο του όρου ActiveX Database Objects. Η Microsoft αντικατέστησε το πρότυπο ODBC (Open Database Connectivity)
και προγενέστερες τεχνολογίες προσπέλασης δεδομένων όπως οι DAO και RDO με το ADO
Το ADO είναι ένα μοντέλο βασιζόμενο στο πρότυπο COM(Component Object Model ) το οποίο αποτελεί ένα σύστημα
επικοινωνίας εφαρμογών (Application Programming Interface API). Το πρότυπο COM αντικαθιστά το API του ODBC που
βασίζεται στη γλώσσα C ώστε
να διευκολύνει την χρήση
αντικειμενοστραφών τεχνικών με βάσεις δεδομένων.
Τα συστατικά ADO αποκρύπτουν μεγάλο μέρος της πολυπλοκότητας
που συνεπάγεται η ενασχόληση με το μοντέλο COM και
διαθέτουν συναρτήσεις επικοινωνίας με
διεπαφές (interface) παρόμοιες με αυτές των συστατικών της
βιβλιοθήκης VCL
της Borland. Επιπρόσθετα τα
δεδομένα που προέρχονται από τα συστατικά ADO μπορούν εύκολα να χρησιμοποιηθούν, από διάφορα συστατικά της βιβλιοθήκης του VCL (components) όπως τα πλέγματα εμφάνισης δεδομένων (DBGrid) , πεδία επεξεργασίας κειμένου (DBText) και γραφήματα κά. Αυτό είναι εφικτό επειδή
τα συστατικά ADO
είναι απόγονοι της κλάσης TDataSet και επειδή το συστατικό TDataSource μπορεί να δουλέψει με οποιοδήποτε συστατικό –απόγονο του TDataSet .
Το ADO μπορεί να συνεργάζεται με οποιαδήποτε βάση δεδομένων για την οποία
υπάρχει πρόγραμμα οδήγησης ODBC. Επιπρόσθετα το ADO παρέχει υποστήριξη για δεδομένα αποθηκευμένα σε μη σχεσιακές μορφές
όπως η XML (διάδοχος της HTML) εφόσον υπάρχει ένας παροχέας δεδομένων (data
provider) ο οποίος
συμμορφώνεται με τις προδιαγραφές του ADO. Στη θεωρεία μπορείτε να εκτελέσετε εντολές SQL σε οποιοδήποτε σύνολο δεδομένων ADO, αλλά μπορεί να απαιτούνται ειδικές μορφές
της SQL για την προσπέραση μη σχεσιακών δεδομένων .
Το ADO είναι μια ολοκληρωμένη τεχνολογία, ικανή να παρέχει πλήρη πρόσβαση σε
σχεδόν κάθε βάση δεδομένων που
χρησιμοποιείται σήμερα .
14.5.1
Τα Συστατικά του ADO
Τα συστατικά (components) που μπορεί να χρησιμοποιήσει
ένας προγραμματιστής για να αναπτύξει μια εφαρμογή και να την συνδέσει με μία
βάση δεδομένων είναι:
TADOConnection: Υλοποιεί την σύνδεση με μια βάση δεδομένων
και διαχειρίζεται τις συναλλαγές.
TRDSConnection: Υλοποιεί την σύνδεση με μία βάση δεδομένων
με τρόπο που επιτρέπει την πρόσβαση πολλαπλών βαθμίδων σε ένα σύνολο εγγραφών.
Εάν χρησιμοποιηθεί μόνο με το ΤADODataSet υποστηρίζει το βοήθημα Microsoft
Remote Data Space το οποίο
επιτρέπει το πέρασμα ενός συνόλου εγγραφών ADO μεταξύ των βαθμίδων μιας εφαρμογής βάσεων
δεδομένων πολλαπλών βαθμίδων (n-tiered).
TADOTable: Επιτρέπει την προσπέλαση ενός πίνακα μιας
βάσης δεδομένων βάσει του ονόματός του.
TADOQuery: Προσπελαύνει έναν ή περισσότερους πίνακες
μιας βάσης δεδομένων χρησιμοποιώντας εντολές SQL .Μπορεί να εκτελεί οποιαδήποτε εντολή SQL.
.
TADOStoredProc: Εκτελεί μια αποθηκευμένη διαδικασία από
μία συγκεκριμένη βάση δεδομένων.
TADODataSet: Ουσιαστικά είναι ίσιο με το TADOQuery εκτός από το γεγονός ότι δεν επιτρέπει κατά
την εκτέλεση εντολών SQL να
επιστρέφεται ένα σύνολο εγγραφών σαν αποτέλεσμα.
TADOCommand: Ουσιαστικά είναι ίσιο με το TADOQuery. Επιτρέπει την εκτέλεση οποιασδήποτε
εντολής SQL αλλά για να
προσπελάσετε το σύνολο εγγραφών του αποτελέσματος θα πρέπει να παρέχετε ένα
ξεχωριστό αντικείμενο TADODataSet το οποίο θα συνδεθεί με αυτό το σύνολο εγγραφών.
Το δέντρο κληρονομικότητας των συστατικών ADO έχει τις ρίζες του στο συστατικό TDataSet όπως φαίνεται στην Εικόνα 14.2. Η ιεραρχία
των συστατικών ADO (η
θέση τους δηλαδή στην βιβλιοθήκη VCL) είναι η ακόλουθη :
Εικόνα 14.2 : Η ιεραρχία των
συστατικών ADO
Το πρωτόκολλο επικοινωνίας που χρησιμοποιεί
το ADO είναι το COM το οποίο είναι ένα πρωτόκολλο επικοινωνίας
γνωστό και ως ActiveX
κατασκευασμένο από την Microsoft και χρησιμοποιείται για επικοινωνία μεταξύ εφαρμογών και ενεργών
αντικειμένων.
To OLE DB αποτέλεσε την βάση για την άφιξη του
ActiveX Data Objects -ADO. To ADO πήρε τις βασικές έννοιες της πρόσβασης
δεδομένων και τις παρουσίασε σε ένα μοντέλο αντικειμένων που ήταν απλούστερο
από το DAO και RDO και το οποίο είχε την ευελιξία να έχει πρόσβαση σχεδόν σε
κάθε τύπο δεδομένων. Τώρα μπορούμε να έχουμε πρόσβαση σχεδόν σε κάθε τύπο
σχεσιακής βάσης δεδομένων και μη σχεσιακής. Αν και αρχικά απλό, δίνοντας μας
μόνο τα βασικά για την πρόσβαση στα δεδομένα μας, το ADO αναπτύχθηκε τα δύο
τελευταία χρόνια ωριμάζοντας και επεκτείνοντας τις ικανότητες του. Με το ADO
2.0 τα δεδομένα μπορούν τώρα να προσπελαθούν χρησιμοποιώντας μια μεθοδολογία
σελιδοποίησης (paging),
που είναι εξαιρετική για ανάπτυξη δικτυακών εφαρμογών. Μπορούμε να
αποσυνδέσουμε σύνολα εγγραφών από την αρχική πηγή δεδομένων και να συνεχίσουμε
να τα χειριζόμαστε στον client.
Υπάρχουν τέσσερις διαφορετικές βιβλιοθήκες:
ADODB (Microsoft ActiveX
Data Objects library): περιέχει Command,
Correction, Error(s), Field(s), Parameters, Properties, Property και Recordset.
ADOR (Microsoft ActiveX
Data Objects Recordset Library ) περιέχει
Field(s), Parameters, Properties, Property και Recordset.
RDS (Microsoft
Remote Data Services
library): περιέχει DataControl
και
DataSpace
RDSServer (Microsoft Remote
Data Services Server library): περιέχει
DataFactory.
14.5.4
RDS (Remote Data Service)
To RDS είναι μία έκδοση του
Το μοντέλο Συστατικών Αντικειμένων (Component
Object Model,COM), είναι ένα αντικειμενοστραφές πλαίσιο για την ενοποίηση
συστατικών λογισμικού σε δυαδική μορφή. Το μοντέλο COM υποστηρίζει την
επαναχρησιμοποίηση και την διαλειτουργικότητα των αντικειμένων, ανεξάρτητα από
την γλώσσα που χρησιμοποιήθηκε για την ανάπτυξη του λογισμικού. Ορισμένες
τεχνολογίες βασιζόμενες στο μοντέλο COM είναι οι COM servers/clients , οι
μηχανισμοί ActiveX, η διασύνδεση και ενσωμάτωση αντικειμένων (OLE ) κά . Η
κύρια πλατφόρμα για το COM είναι τα Windows, μπορεί επίσης να υποστηριχθεί
και άλλες πλατφόρμες όπως το Unix χωρίς
όμως την ίδια ευκολία
Το μοντέλο COM είναι ειδικά σχεδιασμένο ώστε
να επιτρέπει την δημιουργία στοιχείων μέσα από ένα προγράμμα, που να μπορούν να χρησιμοποιούνται
τόσο από το ίδιο πρόγραμμα όσο και από άλλα προγράμματα. Τα πλεονεκτήματα του
COM και των σχετιζόμενων με αυτό τεχνολογιών είναι δύο:
To COM καθορίζει ένα πρότυπο σε δυαδικό
επίπεδο για την ανάπτυξη και χρήση συστατικών σε οποιαδήποτε γλώσσα ή εργαλείο
ανάπτυξης.
To COM παρέχει διαφάνεια. Ο χρήστης ενός
συστατικού δεν χρειάζεται να ξέρει που βρίσκεται πραγματικά το συστατικό. Ακόμη
κι αν το συστατικό βρίσκεται σε έναν απομακρυσμένο server η client εφαρμογή το
χρησιμοποιεί σαν να ήταν ένα τοπικό συστατικό.
To ADO είναι μια διεπαφή υψηλού επιπέδου η
οποία βασίζεται σε μία άλλη διεπαφή το ΟLΕDΒ.Ουσιαστικά
το ADO βασίζεται στο OLEDB παρουσιάζοντας τις ικανότητες και κρύβοντας τις
πολυπλοκότητες (μειονεκτήματα) του OLEDB. To OLEDB, είναι μια διεπαφή με χαμηλό
επίπεδο προγραμματισμού που παρέχει πρόσβαση σε δεδομένα. Παρέχει όλες τις
ικανότητες (λειτουργίες) του ODBC καθιστώντας το ως έναν από τους τρόπους πρόσβασης σε δεδομένα. Επίσης το OLEDB
υπερβαίνει το ODBC παρέχοντας πρόσβαση υψηλής απόδοσης σε όλα τα είδη δεδομένων
σχεσιακά και μη σχεσιακά. Πρέπει να σημειωθεί ότι το OLEDB δεν προορίστηκε για
να αντικαταστήσει το ODBC.
Το OLEDB έχει δύο κύρια εξαρτήματα για να
συνδέεται με τα δεδομένα : καταναλωτές (clients) και παροχείς (servers). Καταναλωτές όπως client-server ή web εφαρμογές
χρησιμοποιούν δεδομένα. Οι παροχείς είναι τα εξαρτήματα που επικοινωνούν με τα
δεδομένα μεταφράζοντας την πληροφορία και παρουσιάζοντας μια κοινή διεπαφή για
κάθε τύπο καταναλωτή. Ο χρήστης δεν χρειάζεται να ξέρει τον τρόπο πρόσβασης των
δεδομένων. Αυτή η ικανότητα είναι ενσωματωμένη στο OLEDB μέσω του παρόχου.
Αυτή την στιγμή υπάρχουν οδηγοί OLE DB μόνο
για κάποια συστήματα βάσεων δεδομένων : για την Access , Microsoft SQL Server
και Oracle .Τα συστήματα που δεν χρησιμοποιούν ακόμη οδηγούς OLE DB έχουν έναν
οδηγό ODBC που σημαίνει ότι επικοινωνούν με την βάση δεδομένων χρησιμοποιώντας
τρία επίπεδα : Σύστημα βάσης δεδομένων à ODBC à OLE DB.
To OLEDB είναι σχεδιασμένο για όλους τους
τύπους αποθήκευσης δεδομένων, περιλαμβάνοντας σχεσιακές βάσεις δεδομένων και μη
σχεσιακές πηγές δεδομένων όπως το ηλεκτρονικό ταχυδρομείο ή συστήματα αρχείων.
To OLEDB περιλαμβάνει επιπρόσθετα στοιχεία (συναρτήσεις στην πραγματικότητα)
που δεν έχουν δεδομένα αλλά ενσωματώνουν κάποιες υπηρεσίες παράγοντας και
χρησιμοποιώντας δεδομένα. Ένα στοιχείο αυτών των υπηρεσιών είναι ο επεξεργαστής
ερωτημάτων που επιτρέπει την σύνδεση μεταξύ ετερογενών πηγών δεδομένων ή μεταξύ
δεδομένων από πίνακες διαφορετικού τύπου. Ο επεξεργαστής ερωτημάτων δρα ως
καταναλωτής-client
παίρνοντας γραμμές από κάθε πίνακα . Από την άλλη δρα ως παροχέας-server δημιουργώντας ένα σύνολο δεδομένων και από
τις δύο πηγές επιστρέφοντας στον καταναλωτή ένα σύνολο έγγραφων.
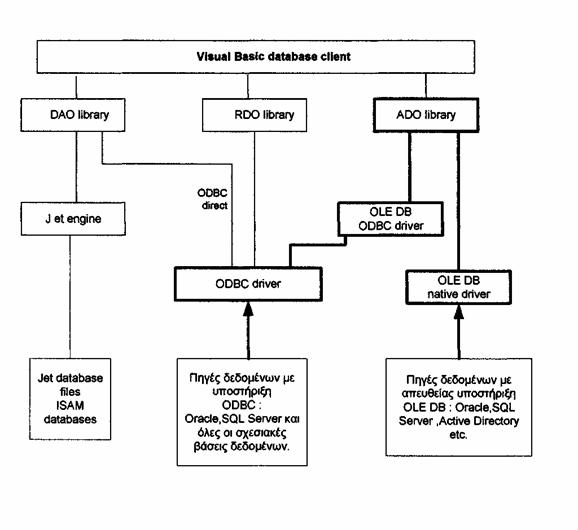
Εικόνα 14.3 Η
Ιεραρχία των διαθέσιμων τρόπων πρόσβασης σε ΒΔ.
14.5.7
Το ADO έναντι του BDE
Το BDE (Borland Database Engine
) είναι ένας δημοφιλής τρόπος προσπέλασης δεδομένων μέσω του C++Builder και είναι ένα ανεξάρτητο επίπεδο γλώσσα προγραμματισμού ακριβώς κάτω από την βιβλιοθήκη του VCL .
Πάντα υπήρχε μια αγορά για τη χρήση μη ΒDE
συστατικών με βασιζόμενα στη VCL σε προγράμματα της Delphi και του C++Builder. Επίσης το BDE θεωρείται ότι είναι αργό για ορισμένες
εφαρμογές, ανεξάρτητα από το εάν αυτό ισχύει πραγματικά ή όχι .Κατά δεύτερον,
οι απαιτήσεις του BDE σε
χώρο δίσκου και μνήμης θεωρούνται υπερβολικές από ορισμένους. Είναι δύσκολη η
εγκατάσταση του BDE στην
εφαρμογή του τελικού χρήστη. Ακόμη και με εργαλεία εγκατάστασης όπως το Wise και InstallShield, τα οποία μειώνουν την πολυπλοκότητα της
διαδικασίας εγκατάστασης σε BDE, το να διασφαλίσει κανείς μια ασφαλή εγκατάσταση ή αναβάθμιση του BDE παραμένει δύσκολη υπόθεση, κυρίως για τις
εκδόσεις του BDE
που παρουσιάζονται μεταξύ διαδοχικών εκδόσεων του εργαλείου εγκατάστασης.
Πριν από το ADO, οι περισσότερες ομάδες συστατικών
επικοινωνίας με βάσεις δεδομένων απευθύνονταν είτε σε συγκεκριμένα συστήματα DBMS όπως η dBase, InterBase είτε σε τεχνολογίες βάσεων δεδομένων όπως το πρότυπο ODBC. Άλλες ομάδες συστατικών υλοποιούσαν δικά
τους υποκατάστατα για το BDE. Ωστόσο, όλες αυτές οι προσεγγίσεις είχαν πρόβλημα –τα συστατικά
διέθεταν διεπαφή διαφορετική από αυτή παρείχαν τα συστατικά που ήταν
προσανατολισμένα στο BDE.
Το γεγονός αυτό καθιστούσε πιο δύσκολη την επαναφορά μιας εφαρμογής στα πλαίσια
του BDE εάν αυτό ήταν επιθυμητό. Δυστυχώς το ίδιο
ακριβώς μειονέκτημα έχουν και τα συστατικά ADO.
Το ADO έχει αρκετά αλλά μειονεκτήματα συγκριτικά με το BDE. Πρώτα απ’ όλα απαιτεί ένα συγκεκριμένο
αλφαριθμητικό σύνδεσης το οποίο θα κατονομάζει έναν πάροχο, έναν server και μία βάση δεδομένων. Αυτό καθιστά πολύ
πιο δύσκολη την αλλαγή της εφαρμογής ώστε να υποστηρίζει άλλες βάσεις δεδομένων
ή συστήματα DBMS
χωρίς να απαιτούνται αλλαγές στον κώδικα. Κατά δεύτερον, σε αντίθεση με το BDE, η SQL στα συστατικά ADO δεν μπορεί να χρησιμοποιείται για
ετερογενείς ενώσεις πινάκων από διαφορετικές βάσεις δεδομένων του ίδιου ή
διαφορετικών DBMS .
Ένα σημείο προσοχής είναι ότι με τα
συστατικά ADO θα πρέπει να
ανησυχεί ο χρήστης για τις πιθανές αναθεωρήσεις των υποκείμενων
βιβλιοθηκών. Όπως για παράδειγμα η
βιβλιοθήκη jet
των αντικειμένων ADO
που απαιτείται από την access για την σύνδεσή της με άλλες εφαρμογές.
Μεγάλο μέρος του λογισμικού που απαιτείται
για την υποστήριξη τους παρέχεται μαζί με το λειτουργικό σύστημα, οπότε δεν
χρειάζεται να κάνει κάτι ειδικό ο χρήστης για την εγκατάσταση .
Λόγω του ότι η εξέλιξη των προγραμμάτων
οδήγησης για το BDE
είναι βραδύτερη απ’ ότι στις προηγούμενες εκδόσεις (αν και το BDE μπορεί να χρησιμοποιεί νεότερα προγράμματα
οδήγησης ODBC και αυτά θα
συνεχίσουν να συμβαδίζουν με την εξέλιξη των συστημάτων DBMS για αρκετό χρόνο), το ADO είναι ο μοναδικός τρόπος για την προσπέλαση
ασυνήθιστων ή προηγμένων τεχνολογιών δεδομένων όπως η XML.
Τα συστατικά ADO μπορούν να διευκολύνουν την μετάβαση μεταξύ
διαφορετικών γλωσσών όπως για παράδειγμα από όπως η Visual C++
της Microsoft στην C++ Builder της Borland.
Τα συστατικά TADOQuery είναι πάντα επεξεργάσιμα, χωρίς να
καταφεύγουν σε αποθηκευμένες ενημερώσεις, UpdateSQL, ή στις πολύπλοκες συνθήκες που καθιστούν
επιτυχή μια αίτηση για ανάκτηση δεδομένων (RequestLive). Αξίζει να σημειωθεί το γεγονός ότι είναι
διαθέσιμη μια μορφή αποθηκευμένων ενημερώσεων (αποκαλείται batch
update-μαζική ενημέρωση- για
συστατικά ADO).
Τα συστατικά ADO επιτρέπουν την ασύγχρονη εκτέλεση κώδικα SQL και την παρακολούθηση της προόδου εκτέλεσης
εντολών μέσω χειριστών συμβάντων. Αυτό μπορεί επίσης να χρησιμοποιηθεί για να
παρέχει τον εξαιρετικά χρήσιμο μηχανισμό εμφάνισης προόδου, ο οποίος δείχνει το
ποσοστό ολοκλήρωσης της εκτέλεσης ενός ερωτήματος ή μιας εντολής .
Ανόμοια με τα συστατικά BDE, είναι σχετικά ασφαλές να τερματιστεί
ένα πρόγραμμα βάσεων δεδομένων
χρησιμοποιώντας την Program Reset (πράγμα το οποίο συνήθως προκαλεί ένα μήνυμα σφάλματος out of
memory από το BDE κατά την επόμενη εκτέλεση και συνήθως ο
τερματισμός του προγράμματος προκαλεί και την κατάρρευση του συστήματος) .
14.5.8
Πλεονεκτήματα τoυ ADO ως προς το DAO/RDO
Η ιεραρχία αντικειμένων του ADO είναι
απλούστερη και ξεκάθαρη. Τα αντικείμενα του ADO μπορούν να χρησιμοποιηθούν και
εκτός από την ιεραρχία τους, που σημαίνει ότι δεν είναι απαραίτητο να
δημιουργηθεί πρώτα ένα αντικείμενο Connection και Command και μετά να
δημιουργηθεί ένα αντικείμενο που να προέρχεται από αυτά.
Το μοντέλο αντικειμένων ADO υποστηρίζει
γεγονότα. Αυτό βοηθάει ώστε να αποφεύγεται ο πλεονασμός στον κώδικα, π.χ ένας
κώδικας που πρέπει να εκτελεστεί όταν αλλάζει η τρέχουσα εγγραφή τώρα γράφεται
πάνω στο αντίστοιχο γεγονός αντί να γράφεται και να καλείται σε πολλά σημεία
του προγράμματος.
To ADO υποστηρίζει ασύγχρονες διαδικασίες.
Το αντικείμενο του ADO Recordset έχει
εντελώς νέες λειτουργίες σε σχέση με το Recordset του DAO όπως η διαχείριση
ιεραρχικών εγγραφών ή η επιλογή να σωθεί ολόκληρη η λίστα εγγραφών σε ένα
αρχείο τοπικά.
To ADO είναι αρκετά βελτιστοποιημένο στην
πρόσβαση βάσεων δεδομένων στο διαδίκτυο. Τα Remote Data Services αντικείμενα
μπορούν να χρησιμοποιηθούν για την ελαχιστοποίηση της προσπάθειας επικοινωνίας.
Η βιβλιοθήκη ADO επιτρέπει το προγραμματισμό
νέων στοιχείων ελέγχου του ADO και τον ορισμό ξεχωριστών πηγών δεδομένων (OLEDB
Provider)
Η σύνδεση μεταξύ ADO προγραμμάτων (όπως
μεταξύ βάσεων δεδομένων client και server) μπορεί να πραγματοποιηθεί μεταξύ
διαφορετικών πρωτοκόλλων δικτύου όπως μια http σύνδεση ή μέσω DCOM
14.6
Παγκόσμια Πρόσβαση Δεδομένων (Universal data access)
Οι δραματικές αλλαγές που συμβαίνουν στον
κόσμο των υπολογιστών έχουν αλλάξει σημαντικά τις έννοιες της πρόσβασης στα
δεδομένα. Πριν από μερικά χρόνια, η πρόσβαση σε δεδομένα περιοριζόταν
αποκλειστικά σε σχεσιακές βάσεις δεδομένων με συγκεκριμένες τεχνολογίες να
γεφυρώνουν το χάσμα μεταξύ μεγάλων υπολογιστικών συστημάτων και προσωπικών
υπολογιστών.
Η εμφάνιση και η ευρύτατη διάδοση του
Διαδικτύου και του Παγκόσμιου Ιστού έφερε στο προσκήνιο την πρόσβαση σε
απομακρυσμένα δεδομένα. Η προσπέλαση βάσεων δεδομένων μέσω του πρωτοκόλλου HTTP
που είναι παγκοσμίως γνωστό αλλάζει σημαντικά τα δεδομένα. Προκειμένου να
μπορεί μια εφαρμογή να αντιμετωπίσει όλους του τύπους πελατών (τοπικούς και
απομακρυσμένους) με διαφάνεια, απαιτείται η ενσωμάτωση επιπλέον
λειτουργικότητας από τους προγραμματιστές. Η χρήση τεχνολογιών ιστού απαιτεί
επίσης την προσεκτική παρακολούθηση των δεδομένων και των καταστάσεων τους
καθώς αυτά (ταξιδεύουν ανά τον κόσμο).
Η παγκόσμια πρόσβαση δεδομένων είναι ένας
τρόπος της Microsoft να αντιμετωπίζει αυτά τα προβλήματα και όλα βασίζονται
πάνω στο OLEDB, και ειδικότερα στους δύο τύπους χρηστών των δεδομένων :
Παρόχους και χρήστες . Ο πάροχος είναι
αυτός που μεταφέρει δεδομένα - συνδέεται με τον χρήστη και δίνει τα δεδομένα σε
όποιον τα ζητήσει. Ο χρήστης είναι αυτός που χρησιμοποιεί τα δεδομένα.
Το JDBC ΑPI (Java
DataBase Connectivity) είναι
ένα από τα ισχυρότερα και πιο ολοκληρωμένα APIs της Java. Παρέχει στον προγραμματιστή τη δυνατότητα
να συνδέσει την εφαρμογή του με βάσεις δεδομένων διαφόρων τύπων χωρίς να
χρειαστεί να τροποποιήσει το πρόγραμμά του κάθε φορά που συνδέει την εφαρμογή
του σε μια διαφορετική βάση. Παρεμβάλλει και ενεργεί ως διαμεσολαβητής (middleware) ανάμεσα στις Java εφαρμογές και τις σχεσιακές (relational) βάσεις. Το JDBC είναι ένα interface για πρόσβαση σε βάσεις δεδομένων (database
access interface) που
χρησιμοποιεί standard SQL ερωτήσεις. Προσφέρει στον προγραμματιστή την άνεση να γράφει ένα
πρόγραμμα που να στέλνει μια SQL ερώτηση σε μια σχεσιακή βάση δεδομένων είτε πρόκειται για SQL
Server είτε για Oracle είτε για Access είτε για οποιαδήποτε άλλη πλατφόρμα. Η μόνη
φροντίδα του προγραμματιστή είναι να επιλέγει κάθε φορά που συνδέεται σε μια
βάση τον κατάλληλο driver
για να καταλαβαίνει το JDBC τι είδους βάση πρόκειται να προσπελάσει ώστε να φορτώνει τις
απαραίτητες ρουτίνες.
Με το JDBC API ο προγραμματιστής της εφαρμογής μπορεί να
ρωτήσει την βάση οποιαδήποτε SQL ερώτηση επιθυμεί, να πάρει μεταδεδομένα από την βάση δεδομένων και όχι
μόνον να παραλάβει τα αποτελέσματα από την βάση αλλά και να τα τροποποιήσει και
να τα μορφοποιήσει όπως αυτός θέλει.
Επιπλέον το JDBC API περιέχει το JDBC–ODBC bridge (πρόκειται για κοινό προiόν
της Javasoft με την Intersolv). Αφορά ένα σύνολο προγραμμάτων που
περιέχει το JDBC ΑPI τα οποία επιτρέπουν τη σύνδεση και την
επικοινωνία των εφαρμογών που γράφει ο προγραμματιστής με οποιαδήποτε βάση
δεδομένων που μπορεί να προσπελαστεί με τον οδηγό ODBC (Open DataBase Connectivity) της Microsoft. Η γέφυρα αυτή προσδίδει στο JDBC τη δυνατότητα να χρησιμοποιήσει ένα μέρος
από τις λειτουργίες του ODBC προκειμένου η εφαρμογή να επικοινωνήσει με την βάση που χρησιμοποιεί
τον οδηγό ODBC. Φαίνεται έτσι η καταπληκτική
ευελιξία που χαρακτηρίζει το JDBC API.
Η μεγάλη επιτυχία και λειτουργικότητα του JDBC οδηγεί καθημερινά ένα μεγάλο αριθμό
κατασκευαστριών εταιριών συστημάτων client-server, database και middleware να υιοθετήσουν και να ενσωματώσουν την
τεχνολογία JDBC
στα προϊόντα τους.
14.8 Microsoft SQL Server
 Ο Microsoft SQL Server είναι ένα σχεσιακό σύστημα
διαχείρισης βάσεων δεδομένων. Υποστηρίζει την SQL, την ποιο διαδεδομένη γλώσσα βάσεων δεδομένων.
Χρησιμοποιείται συχνά από επιχειρήσεις για μικρομεσαίες βάσεις δεδομένων αν και
μπορεί να ανταγωνιστεί επάξια και άλλα παρόμοια προϊόντα. Χρησιμοποιεί μια
παραλλαγή της SQL την T-SQL (Transact –SQL,βασισμένη στην SQL-92). Μέχρι αυτή την στιγμή έχουν
κυκλοφορήσει 8 εκδόσεις με τελευταία την SQL SERVER 2005 64bit. Ιστορικά να αναφέρουμε ότι η βάση του
κώδικα του Sql server αρχικά προήλθε από το Sybase Sql Server και αποτελούσε την είσοδος της Microsoft στο χώρο των βάσεων δεδομένων απέναντι στην
Oracle, IBM και Sybase. Η πρώτη έκδοσή της προοριζόταν για το OS/2 (1993) ήταν ουσιαστικά ο ίδιος ο Sybase
Sql Server. Αργότερα με την
έλευση των Windows NT οι δυο εταιρείες έπαψαν την συνεργασία και επιδίωξαν δικά τους
σχεδιαστικά και marketing μονοπάτια. Την παρούσα στιγμή ο Microsoft SQL Server αποτελεί ένα από τα πιο ανταγωνιστικά
προϊόντα στο χώρο. Σαν μειονέκτημα θα μπορούσαμε να προσδιορίσουμε την απαίτηση
του Microsoft SQL Server για
συνεργασία με συγκεκριμένα λειτουργικά συστήματα (windows server και όχι άλλες εκδόσεις).
Ο Microsoft SQL Server είναι ένα σχεσιακό σύστημα
διαχείρισης βάσεων δεδομένων. Υποστηρίζει την SQL, την ποιο διαδεδομένη γλώσσα βάσεων δεδομένων.
Χρησιμοποιείται συχνά από επιχειρήσεις για μικρομεσαίες βάσεις δεδομένων αν και
μπορεί να ανταγωνιστεί επάξια και άλλα παρόμοια προϊόντα. Χρησιμοποιεί μια
παραλλαγή της SQL την T-SQL (Transact –SQL,βασισμένη στην SQL-92). Μέχρι αυτή την στιγμή έχουν
κυκλοφορήσει 8 εκδόσεις με τελευταία την SQL SERVER 2005 64bit. Ιστορικά να αναφέρουμε ότι η βάση του
κώδικα του Sql server αρχικά προήλθε από το Sybase Sql Server και αποτελούσε την είσοδος της Microsoft στο χώρο των βάσεων δεδομένων απέναντι στην
Oracle, IBM και Sybase. Η πρώτη έκδοσή της προοριζόταν για το OS/2 (1993) ήταν ουσιαστικά ο ίδιος ο Sybase
Sql Server. Αργότερα με την
έλευση των Windows NT οι δυο εταιρείες έπαψαν την συνεργασία και επιδίωξαν δικά τους
σχεδιαστικά και marketing μονοπάτια. Την παρούσα στιγμή ο Microsoft SQL Server αποτελεί ένα από τα πιο ανταγωνιστικά
προϊόντα στο χώρο. Σαν μειονέκτημα θα μπορούσαμε να προσδιορίσουμε την απαίτηση
του Microsoft SQL Server για
συνεργασία με συγκεκριμένα λειτουργικά συστήματα (windows server και όχι άλλες εκδόσεις).
![]()
Η Oracle αποτελεί το καλύτερο και πιο ολοκληρωμένο
σύστημα διαχείρισης βάσεων δεδομένων, με χιλιάδες τεχνολογίες και προαιρετικά
στοιχεία, διαθέσιμα σε πάρα πολλές εκδόσεις και παραλλαγές.
Η Oracle προσφέρει ως αναπόσπαστο τμήμα κάθε
διακομιστή βάσης δεδομένων, τον Oracle Enterprise Manager (EM),
που είναι ένα πακέτο με εργαλεία διαχείρισης βάσεων δεδομένων σε γραφικό
περιβάλλον. Το περιβάλλον αυτό μπορεί να χρησιμοποιηθεί για την διαχείριση των
χρηστών της βάσης, τη δημιουργία στιγμιότυπων (instances) της βάσης, την παρακολούθηση της απόδοσης της
βάσης, της χρήσης μνήμης, τη ρύθμιση ευρετηρίων και γενικότερα ότι έχει να
κάνει με την διαχείριση της βάσης.
Οι δυνατότητες που έχει το RDBMS της Oracle είναι πολλές και μπορούμε να τις κατατάξουμε
στις παρακάτω μεγάλες κατηγορίες: δυνατότητες ανάπτυξης εφαρμογών, σύνδεσης
βάσεων δεδομένων, ανάπτυξης κατανεμημένων βάσεων δεδομένων, συναλλαγής
δεδομένων, απόδοσης της βάσης, διαχείρισης βάσεων δεδομένων.
Μια ξεχοριστή δυνατότητα της Oracle είναι η ενσωμάτωση της Java, η οποία επιτρέπει στους προγραμματιστές να
αναπτύξουν εφαρμογές στον πελάτη (client), στον διακομιστή εφαρμογών Oracle ή πάνω στη βάση δεδομένων, ανάλογα με τις ανάγκες της εφρογής.
Η Oracle μπορεί να αποθηκεύσει και να
εκτελέσει ερωτήματα, αποθηκευμένες διαδικασίες και συναρτήσεις. Χρησιμοποιεί
την PL/SQL (επέκταση της SQL), η οποία είναι μια προηγμένη γλώσσα
προγραμματισμού, για την προσπέλαση των δεδομένων της Oracle μέσα από διαφορεικά περιβάλλοντα. Ο κώδικας
που γράφεται σε PL/SQL για τις βάσεις, εκτελείται γρήγορα και αποτελεσματικά
επειδή είναι ενοποιημένη με το Oracle Server. Η γλώσσα αυτή είναι γλώσσα τέταρτης γενεάς που σημαίνει ότι οι εντολές
της περιγράφουν το τι πρέπει να γίνει αλλά όχι τον τρόπο με τον οποίο θα γίνει.
Ο Server αναλαμβάνει να
κάνει τον έλεγχο στις εγγραφές της βάσης και να εκτελέσει τις εντολές της SQL. Οι γλώσσες τρίτης γενεάς, όπως C, C++,
Java κλπ, είναι πιο
διαδικαστικές και πρέπει βήμα βήμα να καθορίζουν αυτό που πρέπει να γίνει και
τον τρόπο με τον οποίο θα γίνει μια διαδικασία. Το PL/SQL είναι ακρωνύμιο των λέξεων Procedural Laguage/SQL, και όπως δηλώνει
και το όνομά της, προσθέτει στην SQL δομές που υπάρχουν σε διαδικαστικές γλώσσες, όπως πχ. μεταβλητές και
τύπους δεδομένων, εντολές όπως IF-THEN-ELSE και βρόγχους, τύπους αντικειμένων και μεθόδους, σκανδάλες, εντολές υπό
συνθήκη και ρουτίνες χειρισμού
σφαλμάτων.
Όλες οι εκδόσεις της Oracle περιλαμβάνουν προγράμματα οδήγησης (drivers) που επιτρέπουν στις εφαρμογές να
προσπελαύνουν τα δεδομένα μέσω του προτύπου ODBC ή του ανοιχτού προτύπου JDBC.
Μια εγκατάσταση βάσεων δεδομένων Oracle
έρχεται παραδοσιακά με ένα σχήμα προεπιλογής
το οποίο αποκαλείται ‘’scott’’. Ο κάθε χρήστης, μπορεί να έχει πρόσβαση στη ΒΔ με όνομα χρήστη «scott» και κωδικό πρόσβασης «tiger», ώστε να δημιουργήσει τους δικούς του
πίνακες και βάσεις.
Στον παρακάτω πίνακα παρουσιάζονται κάποια
βασικά προϊόντα της Oracle
|
|
|
|
Πίνακας
14.1 Ενδεικτικά προϊόντα από το site της Oracle
14.10
MySQL
 Η MySQL είναι ένα πολύ
γρήγορο και δυνατό σύστημα διαχείρισης βάσεων δεδομένων πολλών χρηστών. Είναι
από τις πιο δημοφιλείς βάσεις δεδομένων με περισσότερες από έξι εκατομμύρια
εγκαταστάσεις παγκοσμίως. Ο διακομιστής της
MySQL ελέγχει την
πρόσβαση στα δεδομένα ώστε να μπορούν να δουλεύουν πολλοί χρήστες ταυτόχρονα.
Για να παρέχει γρήγορη πρόσβαση και να διασφαλίσει ότι μόνο πιστοποιημένοι
χρήστες μπορούν να έχουν πρόσβαση χρησιμοποιεί την SQL (STRUCTURED QUERY LANGUAGE),
την τυπική γλώσσα ερωτημάτων για βάσεις δεδομένων. Η MySQL είναι διαθέσιμη από το 1996, αλλά η ιστορία
της ξεκινά από το 1979.
Η MySQL είναι ένα πολύ
γρήγορο και δυνατό σύστημα διαχείρισης βάσεων δεδομένων πολλών χρηστών. Είναι
από τις πιο δημοφιλείς βάσεις δεδομένων με περισσότερες από έξι εκατομμύρια
εγκαταστάσεις παγκοσμίως. Ο διακομιστής της
MySQL ελέγχει την
πρόσβαση στα δεδομένα ώστε να μπορούν να δουλεύουν πολλοί χρήστες ταυτόχρονα.
Για να παρέχει γρήγορη πρόσβαση και να διασφαλίσει ότι μόνο πιστοποιημένοι
χρήστες μπορούν να έχουν πρόσβαση χρησιμοποιεί την SQL (STRUCTURED QUERY LANGUAGE),
την τυπική γλώσσα ερωτημάτων για βάσεις δεδομένων. Η MySQL είναι διαθέσιμη από το 1996, αλλά η ιστορία
της ξεκινά από το 1979.
1.2
14.10.1
Σημαντικοί χρήστες της MySQL
·
Yahoo! για μερικές
διοικητικές λειτουργίες στοιχείων
·
Οι επικοινωνίες COX, τέταρτος ο μεγαλύτερος
καλώδιο-τηλεοπτικός προμηθευτής στις Ηνωμένες Πολιτείες, έχουν περισσότερους
από 3.600 πίνακες και δύο δισεκατομμύρια γραμμές των στοιχείων στις βάσεις
δεδομένων τους και χειρίζονται περίπου τέσσερα εκατομμύριο ένθετα κάθε δύο
ώρες.
·
LiveJournal, περίπου
300 εκατομμύριο απόψεις
σελίδων ανά ημέρα
·
Amazon.com για πολλά
εσωτερικά προγράμματα
·
Slashdot, με περίπου 50 εκατομμύριο απόψεις σελίδων ανά ημέρα.
·
Δημοφιλής περιοχή ειδήσεων Digg.
·
Wikipedia, περισσότερες από 200
εκατομμύρια ερωτήσεις και 1,2 εκατομμύρια αναπροσαρμογές ανά ημέρα με μέγιστα
φορτία 11.000 ερωτήσεων ανά δευτερόλεπτο.
14.10.2 Μερικά από τα πλεονεκτήματα της MySQL
Απόδοση
Η MySQL είναι χωρίς αμφιβολία γρήγορη .
Χαμηλό κόστος
Η MySQL είναι διαθέσιμη δωρεάν, με άδεια ανοικτού κώδικα (open
source), ή με χαμηλό κόστος ,
αν απαιτείται από την εφαρμογή μας και πάρουμε εμπορική άδεια.
Ευκολία χρήσης
Οι περισσότερες μοντέρνες βάσεις
δεδομένων χρησιμοποιούν SQL. Αν έχουμε χρησιμοποιήσει ένα άλλο σύστημα
διαχείρισης βάσεων δεδομένων δεν θα έχουμε πρόβλημα να προσαρμοστούμε σε αυτό
μιας και όλα τα RDBMS χρησιμοπιούν
πλέον την SQL.
Μεταφερσιμότητα
Η MySQL μπορεί να χρησιμοποιηθεί σε πολλά διαφορετικά λειτουργικά συστήματα
όπως UNIX, WINDOWS.
Κώδικας προέλευσης
Μπορούμε να πάρουμε και να τροποποιήσουμε
τον κώδικα προέλευσης της MySQL.
14.10.3 Χρήστες και Δικαιώματα
Ένα σύστημα RDBMS μπορεί να έχει πολλούς χρηστές. Παρακάτω θα
παρουσιάσουμε ένα παράδειγμα εκχώρησης προνομίων σε χρήστες μέσω της MySQL.
Ο χρήστης root θα
πρέπει γενικά να χρησιμοποιείται μόνο για διαχειριστικούς σκοπούς, για λόγους
ασφάλειας. Για κάθε χρήστη που χρειάζεται να χρησιμοποιήσει το σύστημα, θα
πρέπει να διαμορφώσουμε έναν λογαριασμό χρήστη και έναν κωδικό πρόσβασης. Με το
άνοιγμα της βάσης θα πρέπει τα παραπάνω στοιχεία να συμπληρωθούν, ειδάλλως ο
χρήστης δεν θα έχει πρόσβαση στη βάση αν δε δώσει τα σωστά στοιχεία ή δώσει
ελλιπή στοιχεία.
Μια από τις καλύτερες λειτουργίες της MySQL είναι ότι υποστηρίζει ένα προχωρημένο
σύστημα εκχώρησης δικαιωμάτων. Ένα δικαίωμα είναι η δυνατότητα να εκτελείται
μια συγκεκριμένη ενέργεια σε ένα συγκεκριμένο αντικείμενο και να σχετίζεται με
ένα συγκεκριμένο χρήστη. Όταν δημιουργούμε ένα χρήστη στην MySQL του δίνουμε ένα σύνολο δικαιωμάτων για να καθορίσουμε τι θα μπορεί και τι δεν θα
μπορεί να κάνει στο σύστημα.
Για παράδειγμα, ο χρήστης user1 έχει τα δικαιώματα που αναφέρονται στη
στήλη Assigned Privileges.
Αυτά τα δικαιώματα ισχύουν μόνο για τη συγκεκριμένη βάση. Ο διαχειριστής πρέπει
να του ορίζει δικαιώματα εκ νέου για κάθε νέα βάση που θέλει ο χρήστης να
συνδεθεί. Η παρακάτω διαδικασία έγινε με τη βοήθεια του Mysql administrator. Στην στήλη Available Privileges περιέχονται τα δικαιώματα από τα οποία όλα
ή μερικά μπορούμε να παραχωρήσουμε στον χρήστη.
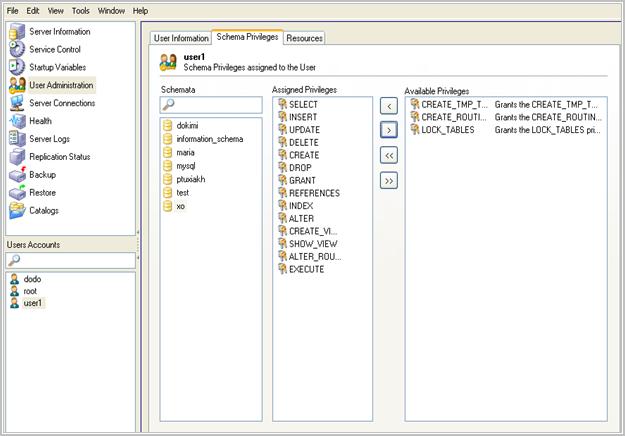
Εικόνα 14.4 Ορισμός δικαιωμάτων σε έναν χρήστη της MySQL
Υπάρχουν
τρεις βασικοί τύποι δικαιωμάτων στην MySQL, δικαιώματα για κανονικούς χρήστες ,
δικαιώματα για διαχειριστές και κάποια ειδικά δικαιώματα.
Οποιοσδήποτε χρηστής μπορεί να πάρει
οποιοδήποτε δικαίωμα, αλλά θα ήταν λογικό τα δικαιώματα του διαχειριστή να μην
τα δίνουμε στους απλούς χρήστες. Στο παράδειγμα αυτό ενδεικτικά δημιουργήσαμε
έναν χρήστη διαχειριστή και έναν χρήστη χωρίς δικαιώματα στη βάση.
14.10.4 Διαμορφώνοντας Xρήστες.
Οι εντολές GRANT και REVOKE χρησιμοποιούνται για να δώσουν και να
πάρουν δικαιώματα από και προς τους χρήστες της MySQL.

Εικόνα 14.5
Απεικόνιση της σχέσης μεταξύ του διαχειριστή της βάσης και ενός χρήστη
Η γενική μορφή της εντολής GRANT είναι :
GRANT
privileges (privileges είναι η λίστα των δικαιωμάτων χωρισμένη με κόμματα)
ON item (item είναι η βάση ή ο
πίνακας)
TO user_name [IDENTIFIED BY ‘password’] (δηλώνουμε το όνομα και τον
κωδικό πρόσβασης του χρήστη)
[WITH GRANT OPTION] (η
εντολή αυτή επιτρέπει στον συγκεκριμένο χριστή να δώσει τα δικά του δικαιώματα
σε άλλους )
* τα περιεχόμενα στις αγκύλες
είναι προαιρετικά
Η γενική μορφή της εντολής REVOKE είναι :
REVOKE
privileges
ON item
FROM
user_name
Θέλουμε να διαμορφώσουμε έναν χρήστη που θα
ονομάζεται Χ και θα έχει τον κωδικό πρόσβασης $$$$ και θα έχει το δικαίωμα της επιλογής για τη βάση δεδομένων test στην MySQL.
Λύση
Mysql > grant select
-> on test.*
->
to x identified by ‘$$$$’ ;
Εάν θελήσουμε να ανακαλέσουμε
τα δικαιώματα του παραπάνω χρήστη γράφουμε το εξής:
Mysql > revoke select
-> on test.*
-> from x ;
14.10.5 Τύποι Δικαιωμάτων/ Προνομίων
Δικαιώματα Χρηστών
Select: Επιτρέπει στους χρήστες να επιλέγουν γραμμές από πίνακες.
Insert : Επιτρέπει στους χρήστες να εισάγουν νέες γραμμές.
Update:Επιτρέπει στους χρήστες να τροποποιούν
τιμές σε υπάρχουσες γραμμές.
Delete : Επιτρέπει στους χρήστες να διαγράφουν υπάρχουσες τιμές πινάκων .
Index : Επιτρέπει στους χρήστες να δημιουργούν και να διαγράφουν ευρετήρια σε
συγκεκριμένους πίνακες .
Alter : Επιτρέπει στους χρήστες να αλλάζουν την δομή υπαρχόντων πινάκων, για παράδειγμα,
προσθέτοντας στήλες , μετονομάζοντας στήλες και αλλάζοντας τους τύπους
δεδομένων των στηλών.
Describe : Με την εντολή Describe
η MySQL θα εμφανίσει τις
πληροφορίες που δώσαμε όταν δημιουργήσαμε τον πίνακα στην βάση δεδομένων.
Drop : Επιτρέπει στους χρήστες να διαγράφουν βάσεις ή πίνακες.
Δικαιώματα Διαχειριστών
Shutdown: Επιτρέπει σε έναν διαχειριστή να τερματίζει
τον MySQL
διακομιστή.
Process : Επιτρέπει σε έναν διαχειριστή να
βλέπει τις διαδικασίες του διακομιστή και να τις τερματίζει.
File : Επιτρέπει σε δεδομένα να διαβάζονται σε πίνακες από αρχεία και το
αντίστροφο.
Ειδικά Δικαιώματα
All : Δίνει όλα τα δικαιώματα.
Usage : Δεν δίνει δικαίωμα , θα δημιουργήσει έναν χρήστη και θα του επιτρέψει
απλά να συνδεθεί χωρίς να μπορεί να κάνει
κάτι.
Δημιουργία
user interface με
τον Borland Builder και
την MySQL.
Λύση
Ο BDE
Administrator της Borland είναι
ένα πλήρως λειτουργικό εργαλείο το οποίο μας δίνει την δυνατότητα παρουσίασης ή
τροποποίησης πληροφοριών που αφορούν τη δομή μίας βάσης δεδομένων καθώς και τις
πληροφορίες που βρίσκονται αποθηκευμένες στους πίνακες της.
Ο BDE
Administrator έχει
δύο τμήματα. Το αριστερό τμήμα όπως φαίνεται στην Εικόνα 14.4 είναι μία γραφική
απεικόνιση των ονομάτων ALIAS που αντιστοιχούν οι βάσεις δεδομένων για τις οποίες είναι
ενήμερη η Μηχανή Βάσεων Δεδομένων της Borland. Στο δεξιό τμήμα παρουσιάζονται
οι πληροφορίες που αφορούν το όνομα ALIAS που έχουμε επιλέξει στο αριστερό μέρος.
Εικόνα
14.6 BDE Administrator Tool
Η C Builder περιέχει μη οπτικά αντικείμενα ή αλλιώς χειριστήρια (non
visual components) για πρόσβαση
στις βάσεις δεδομένων (data - access components) τα οποία συνδέουν τα αντικείμενα της εφαρμογής με τη βάση. Τα
αντικείμενα αυτά τοποθετούνται στις φόρμες της εφαρμογής (Data
Modules). Περιέχει ακόμη τα
οπτικά αντικείμενα (visual components) τα οποία προβάλουν τα δεδομένα (data - aware) της βάσης. Τα αντικείμενα αυτά είναι τα οπτικά σημεία ελέγχου (visual
controls) και αποτελούν τα
σημεία της επικοινωνίας του χρήστη της εφαρμογής, με τη βάση δεδομένων. Είναι
μια φόρμα επικοινωνίας ανάμεσα στο χρήστη και την εφαρμογή (user
interface). Κάθε σημείο ελέγχου
είναι συνδεδεμένο με ένα ή περισσότερα πεδία.
Βήματα για την επίτευξη της
επικοινωνίας με ΒΔ
Βήμα
1ο :
Ανοίγουμε τον C Builder. Στην φόρμα που εμφανίζεται τοποθετούμε και
προγραμματίζουμε τα αντικείμενα πρόσβασης βάσεων δεδομένων. Στην καρτέλα Data
Access της γραμμής εργαλείων
του Builder, περιέχονται μη
οπτικά αντικείμενα πρόσβασης δεδομένων μιας βάσης
Το αντικείμενο Tdatabase αντιπροσωπεύει μια σύνδεση με τη βάση δεδομένων. Στο
χειριστήριο (component) αυτό ρυθμίζουμε τις παρακάτω ιδιότητες:

|
Alias Name: |
το όνομα του ALIAS του BDE με το
οποίο είναι συνδεδεμένο το εξάρτημα. |
|
DatabaseName: |
Το όνομα της βάσεως με την
οποία θα γίνει η σύνδεση. |
|
Connected: |
True, το εξάρτημα συνδέεται κατά τη
έναρξη της εφαρμογής με τη βάση που ορίζεται στην ιδιότητα AliasName.
Όταν γίνεται η σύνδεση ζητείται το User Name και το Password
του Server με τον οποίο θα γίνει η σύνδεση. |
Βήμα 2ο :
Στη συνέχεια τοποθετείται το
αντικείμενο TTable που αντιπροσωπεύει ένα σετ πληροφοριών (Dataset) το
οποίο αποτελείται από όλες τις εγγραφές και τα πεδία που βρίσκονται
αποθηκευμένα σε ένα πίνακα.

Στο αντικείμενο TTable ρυθμίζονται
οι παρακάτω ιδιότητες.
|
DatabaseName: |
To όνομα
της βάσεως με την οποία θα γίνει η σύνδεση και από την οποία προέρχεται ο
πίνακας που αντιπροσωπεύει ο TTable. |
|
TableName: |
Το όνομα του πίνακα τον οποίο
αντιπροσωπεύει ο TTable και από τον οποίο αντλεί τα δεδομένα. |
|
Active: |
True, τα
δεδομένα του πίνακα της βάσεις είναι διαθέσιμα προς τα εξαρτήματα που
λαμβάνουν δεδομένα από τον πίνακα. |
|
Name: |
Το όνομα που ορίζεται το
εξάρτημα και είναι γνωστό στα υπόλοιπα εξαρτήματα. |
Βήμα 3ο :
Τέλος τοποθετείται
το αντικείμενο TDataSource
που λειτουργεί ως
αγωγός μεταξύ των μη οπτικών αντικειμένων δεδομένων και
των οπτικών αντικειμένων.

Στο component
TDataSource στη
ρυθμίζονται οι παρακάτω ιδιότητες.
|
DataSet: |
To όνομα του
πίνακα ή του ερωτήματος από το οποίο προέρχονται τα δεδομένα. |
|
Name: |
Το όνομα που θα είναι γνωστό
το αντικείμενο στα υπόλοιπα αντικείμενα. |
Κεφάλαιο 15. Εξόρυξη Δεδομένων (data
mining)
Ο όρος εξόρυξη δεδομένων αναφέρεται στην διαδικασία ανάλυσης μεγάλων βάσεων δεδομένων για εύρεση χρήσιμων μοτίβων. Σχετίζεται με την ανακάλυψη της γνώσης σε βάσεις δεδομένων. Στο κεφάλαιο αυτό γίνεται μια αναφορά σε βασικές τεχνικές εξόρυξης γνώσεις όπως συσταδοποίηση, κατηγοριοποίηση, δέντρα αποφάσεων και κανόνες συσχέτισης. Παρουσιάζονται στον σπουδαστή νέα επιστημονικά πεδία ερευνητικής και επαγγελματικής δράσης και γίνεται λεπτομερής επεξήγηση του διαμεριστικού αλγορίθμου συσταδοποίησης K-Means.
15.1 Εισαγωγή
ΣΤΗΝ KDD
Στις μέρες μας και σε ένα πολύ μεγάλο εύρος
πεδίων η συλλογή, καταγραφή και επεξεργασία δεδομένων γίνεται με δραματικούς
ρυθμούς. Δημιουργούνται συνεχώς θεωρίες και εργαλεα τα οποία βοηθούν στην
συλλογή χρήσιμων πληροφοριών από τα ολοένα αυξανόμενα δεδομένα. Αυτές οι
θεωρίες και τα εργαλεία είναι το αντικείμενο της Ανακάλυψης Γνώσης σε Βάσεις
Δεδομένων γνωστή και ως KDD (Knowledge Discovery in Databases). H KDD διαδικασία
ασχολείται με την δημιουργία και μελέτη μεθόδων και τεχνικών που εφαρμόζονται
στα δεδομένα με σκοπό την εξαγωγή χρήσιμων πληροφοριών. Ένα πρόβλημα στη KDD διαδικασία είναι όταν έχουμε να μελετήσουμε
low – level
data (δεδομένα χαμηλής
δυναμικότητας) οπού είναι δύσκολο να μελετηθούν και να εξάγουμε από αυτά
χρήσιμα συμπεράσματα σχετικά με αυτά τα δεδομένα (όπως πχ την εύρεση του
μοντέλου από το οποίο προήρθαν).
v
O
όρος KDD αναφέρετε στη
συνολική διαδικασία εύρεσης χρήσιμης πληροφορίας από βάσεις δεδομένων. Σύμφωνα
με τους Piatesky-Shaphiro & Matheus (1991): "KDD είναι μία μη
τετριμμένη διαδικασία εύρεσης έγκυρων, νέων, χρήσιμων και πλήρως κατανοητών
προτύπων από τα δεδομένα".
15.2 Που
χρειάζεται η KDD
Η ανάγκη για
τη χρησιμοποίηση των τεχνικών KDD στην εξόρυξη χρήσιμων πληροφοριών γίνεται κυρίως για 2 λόγους,
οικονομικούς και επιστημονικούς. Οι επιχειρήσεις χρησιμοποιούν αυτά τα πολύτιμα
δεδομένα ώστε να αποκτήσουν πλεονέκτημα έναντι των ανταγωνιστών, να αυξήσουν την αποτελεσματικότητα τους και να
προσφέρουν πιο πολύτιμες υπηρεσίες στους πελάτες τους. Τα δεδομένα που
συλλέγουμε από το περιβάλλον μπορούν να χρησιμοποιηθούν και να μας βοηθήσουν να
καταλάβουμε καλύτερα τον κόσμο στο οποίο ζούμε μελετώντας τα. Επειδή οι
υπολογιστές έχουν βοηθήσει τους ανθρώπους να συλλέξουν και να αποθηκεύσουν
αυτούς τους τεράστιους όγκους δεδομένων είναι λογικό να συμβάλουν και στη μελέτη και
στην επεξεργασία τους.
Χρησιμοποίηση των τεχνικών KDD γίνεται σε πολλούς κλάδους όπως:
Ø
Marketing: Στο marketing όπου γίνεται μελέτη και επεξεργασία όλων
των στοιχείων των πελατών, χωρίζονται σε group και μπορεί να γίνει πρόβλεψη της
συμπεριφοράς τους. Για παράδειγμα σε ένα super market όπου μπορεί να παρατηρηθεί ότι αν ένας
αγοράσει το αντικείμενο Χ τότε είναι πολύ πιθανό να αγοράσει το αντικείμενο Υ
και Χ, οπότε αυτά τοποθετούνται δίπλα το ένα στο άλλο.
Ø
Επενδύσεις(Investment) : Πολλές επιχρίσεις χρησιμοποιούν μεθόδους εξόρυξης γνώσης και μελετούν τα
αποτελέσματα με στόχο να αυξήσουν την αποδοτικότητα τους σε διάφορους τομείς.
Ø
Fraud
Detection: Έχουν αναπτυχθεί συστήματα τα οποία μελετούν και καταγράφουν της
τραπεζικές συναλλαγές και με βάση αυτά τα στοιχεία μπορούν να εντοπίσουν αν
υπάρχει κάποια παρατυπία – κλοπή.
Ø
Επικοινωνίες και Data Cleaning: Υπάρχουν πολλές διαδικασίες που
χρησιμοποιούν Data Mining τεχνικές για να παράγουν χρήσιμες πληροφορίες από μεγάλους όγκους
δεδομένων
15.3
KDD
και
Data Mining
Η διαδικασία εύρεσης χρήσιμων μοντέλων και πληροφοριών έχει πάρει διάφορα ονόματα όπως, data mining,
knowledge extraction, information discovery, information harvesting, data archaeology, and data pattern
processing. O όρος data
mining χρησιμοποιούταν κυρίως
από στατιστικολόγους, αναλυτές δεδομένων, και management
information systems (MIS). Επίσης είναι αρκετά δημοφιλής στο πεδίο
των Βάσεων Δεδομένων. Η φράση Knowledge Discovery in KDD τέθηκε το 1991 από τους Piatesky – Saphiro για να δώσει έμφαση στο ότι η γνώση
είναι το αποτέλεσμα αυτής της διαδικασίας.
Γενικά ο όρος KDD αναφέρεται στη συνολική διαδικασία την
εύρεσης γνώσης από σύνολα δεδομένων και ο όρος Data Mining αναφέρεται σε ένα μέρος αυτής της
διαδικασίας. Data Mining είναι η εφαρμογή συγκεκριμένου αλγορίθμου για την εξαγωγή μοντέλου από
τα δεδομένα.
Τα επιπλέον
βήματα στην KDD
διαδικασία όπως, προετοιμασία των δεδομένων, επιλογή δεδομένων, καθαρισμός
δεδομένων (data cleaning), ενσωμάτωση κατάλληλης γνώσης και σωστή μετάφραση και μελέτη των
αποτελεσμάτων.
15.4 Η Διαδικασία ΚDD
Η διαδικασία
ΚDD εξελίσσεται και θα
συνεχίσει να εξελίσσεται με την εισαγωγή διαφόρων επιστημονικών πεδίων όπως machine learning, pattern recognition,
στατιστική βάσεων, Τεχνίτη νοημοσύνη, παρουσίαση δεδομένων και υπολογισμό
υψηλής απόδοσης. Ο απώτερος
σκοπός είναι η εξαγωγή υψηλού επιπέδου πληροφοριών από χαμηλού επιπέδου
δεδομένα που υπάρχουν σε μεγάλες βάσεις δεδομένων.
Το
αντικείμενο του Data Mining βασίζετε κυρίως σε γνωστές τεχνικές όπως αναφέρθηκε και πριν όπως machine
learning, pattern
recognition και στατιστική για
την εξαγωγή των μοντέλων από την data mining διαδικασία της KDD. Μια φυσιολογική απορία θα ήταν σχετικά με το πώς η KDD διαφοροποιείτε από την αναγνώριση προτύπων
(pattern recognition) ή
άλλων σχετικών μεθόδων. Η απάντηση είναι ότι αυτά τα πεδία παρέχουν κάποιες
μεθόδους data mining οι οποίες
χρησιμοποιούνται στο data mining βήμα της συνολικής KDD διαδικασίας.
Ο όρος ΚDD
επικεντρώνεται στη συνολική διαδικασία της εξόρυξης γνώσης ακόμη και στο πως τα
δεδομένα αυτά αποθηκεύονται, στο πως θα γίνει η προσπέλαση τους, στο πως θα
χρησιμοποιηθεί και τροποποιηθεί ο αλγόριθμος στα συγκεκριμένα σύνολα δεδομένων,
πως θα μελετηθούν και θα παρουσιαστούν τα αποτελέσματα.
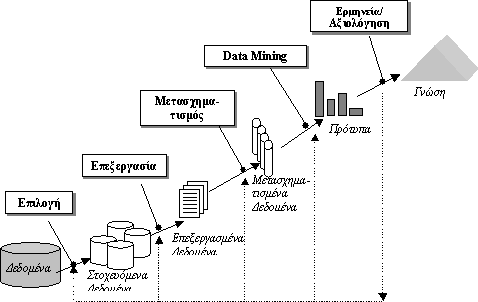
Εικόνα
15.1 H KDD
διαδικασία
Η ΚDD διαδικασία είναι διαλογική και επαναληπτική
και περιλαμβάνει πολλά βήματα με πολλές αποφάσεις να πρέπει να ληφθούν από το
χρήστη. ΟΙ Brachman
και Anand(1996) έδωσαν μια
πρακτική άποψη δίνοντας έμφαση στη διαλογική φύση της διαδικασίας. Αποτελείτε
από τα ακόλουθα Βήματα :
1. Ανάπτυξη
και κατανόηση της εφαρμογής και της σχετικής προγενέστερης γνώσης και
αναγνωρίζοντας το στόχο της KDD διαδικασίας από την πλευρά του πελάτη.
2. Η
δημιουργία των δεδομένων που θα ασχοληθεί η διαδικασία, επιλογή των δεδομένων
από ένα σύνολο.
3. Data
Cleaning (καθαρισμός
δεδομένων), περιλαμβάνει τεχνικές αφαίρεσης θορύβου, συλλογή απαραίτητων
πληροφοριών η τεχνικές κάλυψης χαμένων δεδομένων
4. Μείωση
δεδομένων και προβολή. Η εύρεση χρήσιμων τρόπων για την αναπαράσταση των
δεδομένων ανάλογα με το σκοπό .
5. με βάση
το στόχο της διαδικασίας η χρησιμοποίηση μιας μεθόδου data mining όπως για παράδειγμα summarization, classification , regression, clustering.
6. Ανάλυση
του μοντέλου και η επιλογή του κατάλληλου αλγόριθμου που θα χρησιμοποιηθεί στα
δεδομένα. Αυτή η διαδικασία περιλαμβάνει την ταύτιση του αλγορίθμου data
mining με τα συνολικά κριτήρια
της KDD διαδικασίας.
7. Data
Mining: εφαρμογή του
αλγορίθμου, ο χρήστης μπορεί να βοηθήσει και να παραμετροποιήσει την data
mining μέθοδο με σκοπό τα
καλύτερα αποτελέσματα
8. Έλεγχος
της όλης διαδικασίας, ίσως και επιστροφή σε προηγούμενο βήμα για κάποιες
αλλαγές η παραμετροποιήσεις
9. Η δράση
πάνω στην γνώση που ανακαλύφθηκε ,είτε χρησιμοποιώντας την άμεσα είτε
εισάγοντας την σε ένα άλλο σύστημα για περαιτέρω επεξεργασία επίσης αυτό το βήμα περιλαμβάνει
και τον έλεγχο για πιθανή σύγκρουση με προηγούμενη γνώση.
Η περισσότερη
εργασία και μελέτη έχει γίνει πάνω στις μεθόδους του Data Mining ωστόσο και τα άλλα βήματα είναι πολύ
σημαντικά για την επιτυχή ολοκλήρωση της KDD διαδικασίας.
15.5
Data Μining
Το Data
Mining είναι μια διαδικασία που
ανήκει στην συνολική προσπάθεια της εξόρυξης γνώσης. Η ανακάλυψη αυτής
της γνώσης καθορίζετε με την χρησιμοποίηση 2 συστημάτων: (1) επαλήθευση και (2) ανακάλυψη. Στην επαλήθευση
το σύστημα περιορίζετε στο να επαληθεύσει την αρχική υπόθεση του χρήστη. Στην
ανακάλυψη το σύστημα αυτόνομα αναγνωρίζει καινούργια πρότυπα. Επίσης
περιλαμβάνετε η πρόβλεψη όπου το
σύστημα βρίσκει πρότυπα ώστε να προβλέψει την μελλοντική συμπεριφορά ορισμένων
εγγραφών στη βάση και τέλος η περιγραφή
όπου το σύστημα στοχεύει στην εύρεση προτύπων για την παρουσίαση των
αποτελεσμάτων σε κατανοητή μορφή. Παρακάτω μελετάται κυρίως ως αναφορά την ανακάλυψη προτύπων.
Η εξόρυξη
γνώσης χρησιμοποιεί αλγόριθμους για την ανάλυση των αρκετά μεγάλων συνόλων
από δεδομένα και την εύρεση ανυποψίαστων σχέσεων και την σύνοψη αυτών με
νέους τρόπους κατανοητούς και χρήσιμους στον ιδιοκτήτη. Οι σχέσεις και οι
συνόψεις που παράγονται μέσω του data mining συχνά παρουσιάζονται ως μοντέλα ή πρότυπα.
Η λειτουργία
του «Data Mining» έχει να
κάνει ουσιαστικά με δεδομένα που έχουν συλλεχθεί ήδη για κάποιο άλλο
σκοπό. Αυτό σημαίνει πως οι στόχοι της εξόρυξης γνώσης δεν επηρεάζουν τον τρόπο
με τον οποίο συλλέγονται τα δεδομένα. Αυτή θα μπορούσε να είναι μία διαφορά της
εξόρυξης δεδομένων με τις στατιστικές, όπου τα δεδομένα συλλέγονται με
συγκεκριμένους τρόπους για την απάντηση συγκεκριμένων ερωτημάτων. Για αυτόν τον
λόγο η μέθοδος του Data Mining συχνά αναφέρεται ως δευτερεύουσα ανάλυση δεδομένων.
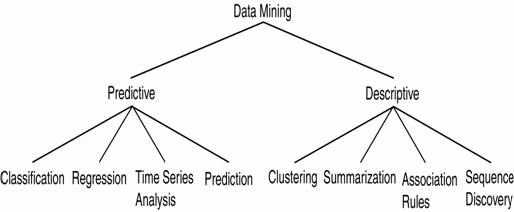
Εικόνα 15.2
Για να
έχουν τα αποτελέσματα της διαδικασίας
πρακτική αξία και τα πρότυπα που θα δημιουργηθούν από την διαδικασία απαιτείται
και η ανθρώπινη παρέμβαση. Οι περισσότερες Data Mining μέθοδοι βασίζονται σε χρησιμοποιημένες και
δοκιμασμένες τεχνικές όπως machine learning, αναγνώριση προτύπων (pattern recognition) και στατιστική: classification, regression, κ.α .
Συχνά τα
διαθέσιμα στοιχεία περιλαμβάνουν μόνο ένα δείγμα από τον πλήρη πληθυσμό. Ο στόχος μπορεί να είναι να γενικεύσουμε από
το δείγμα στον πληθυσμό. Παραδείγματος χάριν, μπορεί να επιθυμήσουμε να προβλέψουμε πώς οι μελλοντικοί
πελάτες είναι πιθανό να συμπεριφερθούν ή να καθορίσουμε τις ιδιότητες των πρωτεϊνικών δομών που δεν έχουμε δει ακόμα.
Μερικές φορές μπορούμε να θελήσουμε να συνοψίσουμε ή να συμπιέσουμε ένα
πολύ μεγάλο σύνολο στοιχείων κατά τέτοιο τρόπο ώστε το αποτέλεσμα είναι
πιο κατανοητό, χωρίς οποιαδήποτε έννοια της γενίκευσης. Αυτό το ζήτημα θα
προέκυπτε, παραδείγματος χάριν, εάν είχαμε τα πλήρη στοιχεία απογραφής για τα
εκατομμύρια συγκεκριμένων χωρών ή μιας καταγραφής βάσεων δεδομένων των
μεμονωμένων λιανικών συναλλαγών.
Με την εξέλιξη της εξόρυξης γνώσης και την
αναγνώριση της αποτελεσματικότητάς της, πολλοί διαφορετικοί επιστημονικοί
κλάδοι συγκλίνανε προς αυτήν την κατεύθυνση, όπως:
·
Στατιστική,
·
Μηχανική
μάθηση (είναι ο αντίστοιχος όρος στην Τεχνητή νοημοσύνη),
·
Αλγόριθμοι
συσταδοποίησης,
·
Τεχνικές
Οπτικοποίησης των αποτελεσμάτων,
·
Ανάκτηση
πληροφοριών,
·
Βάσεις
Δεδομένων, όπου τα δεδομένα πολλά και τα ερωτήματα περίπλοκα
Εικόνα 15.3
15.6
Μέθοδοι Data Mining
Χάρη στην εξέλιξη των υπολογιστών και την τεχνολογία
συλλογής των δεδομένων, μπορούν πλέον να συλλεχθούν τεράστιοι όγκοι δεδομένων.
Αυτοί οι όγκοι περιέχουν συχνά πολύτιμη πληροφορία. Το «δύσκολο» είναι να
εξάγουμε την πολύτιμη αυτή πληροφορία από τον μεγάλο αυτό όγκο έτσι ώστε οι
ιδιοκτήτες των δεδομένων να μπορούν να επενδύσουν σε αυτή. Το Data
Mining είναι μια νέα αρχή, η
οποία αναζητά να κάνει ακριβώς αυτό. Με το «κοσκίνισμα» των δεδομένων με στόχο
την σύνοψη αυτών και την εύρεση προτύπων.
Οι περισσότερες Data Mining (Εικόνα 15.4) μέθοδοι βασίζονται σε
χρησιμοποιημένες και δοκιμασμένες τεχνικές από κλάδους όπως της μηχανικής
μάθησης (machine learning),
αναγνώρισης προτύπων (pattern recognition), στατιστικής και άλλων και αφορούν:
·
συσταδοποίηση
δεδομένων,
·
κατηγοριοποίηση
δεδομένων,
·
εξαγωγή
κανόνων συσχέτισης,
·
πρότυπα
ακολουθιών,
·
ανάλυση
χρονοσειρών,
·
παλινδρόμηση,
·
εκτίμηση
και πρόβλεψη μελλοντικών τάσεων
·
συνοπτική
παρουσίαση πληροφορίας.
Εικόνα 15.4
Ø
Clustering
(συσταδοποίηση)
To
clustering είναι η εργασία του μερισμού ενός συνόλου δεδομένων σε ομάδες ομοίων
στοιχείων, clusters. Τα δεδομένα ομαδοποιούνται
σε σύνολα με βάση κάποιο κριτήριο ομοιότητας. Το clustering δεν
βασίζεται σε προκαθορισμένες κλάσεις.
Ø
Classification
(κατηγοριοποίηση)
Η διαδικασία
κατηγοριοποίησης των δεδομένων σε κάποια από τις προκαθορισμένες κλάσεις. Συχνά
η διαδικασία του classification περιγράφεται σαν μία συνάρτηση μάθησης (learning function), η οποία ταξινομεί (classifies) κάθε αντικείμενο του συνόλου δεδομένων σε
μία από τις προκαθορισμένες κατηγορίες. Η διαδικασία του classification χαρακτηρίζεται από: Ένα σύνολο καλά
ορισμένων κατηγοριών, ένα training set . Στόχος: Ο ορισμός ενός μοντέλου το οποίο μπορεί να
κατηγοριοποιεί νέα δεδομένα
Ø
Εξαγωγή
κανόνων συσχέτισης (association rules extraction)
Προσδιορισμός
και εξαγωγή των συσχετίσεων ή προτύπων τα οποία υπάρχουν σε μία συλλογή
αντικειμένων. Τα πρότυπα μπορούν να εκφραστούν με κανόνες, των οποίων η γενική
μορφή είναι “If X then Y”. Κριτήρια εγκυρότητας και
σημαντικότητας κανόνων: support factor, confidence factor
Ø
Estimation
& prediction (εκτίμηση και πρόβλεψη).
Περιλαμβάνει
τεχνικές εκτίμησης και πρόβλεψης μελλοντικών τάσεων ή τιμών. Ο στόχος εδώ είναι να κατασκευάσουμε
ένα μοντέλο που θα επιτρέπει την τιμή μιας μεταβλητής να προβλεφθεί από τις
γνωστές τιμές άλλων μεταβλητών.
Ø
Regression (παλινδρόμηση).
Αντιστοιχεί
τα αντικείμενα από ένα σύνολο δεδομένων στην τιμή μίας μεταβλητής πρόβλεψης
Ø
Summarization
Περιλαμβάνει
μεθόδους για την περιγραφή ενός υποσυνόλου δεδομένων. Π.χ. η εκτίμηση της μέσης
και της τυπικής απόκλισης για όλα τα πεδία, reports, τεχνικές παρουσίασης, την παραγωγή
συνοπτικών κανόνων.
15.7 Συσταδοποίηση (Clustering)
15.7.1
Βασικές
Έννοιες Και Εφαρμογές
Το πρόβλημα της συσταδοποίησης σχετίζεται με
την τμηματοποίηση (partitioning, clustering) ενός συνόλου
δεδομένων σε συστάδες έτσι ώστε τα στοιχεία του συνόλου των δεδομένων που
ανήκουν σε μία συστάδα να είναι περισσότερο όμοια μεταξύ τους από ότι είναι με
τα στοιχεία των άλλων συστάδων.
Η συσταδοποίηση εκτός από την πληροφορική
συναντάται σε διάφορα άλλα πεδία όπως για παράδειγμα, Επιχειρησιακή έρευνα,
Βιολογία, Στατιστική, Χωρική Ανάλυση Στοιχείων, Ψυχολογία και Ιατρική. Η
συσταδοποίηση έτσι μπορεί να βρεθεί με διαφορετικά ονόματα σε διαφορετικά
πεδία, όπως μη εποπτευόμενη μάθηση (unsupervised learning), στην αναγνώριση προτύπων, αριθμητική
ταξονομία (numerical taxonomy) στην βιολογία, οικολογία, τυπολογία στις κοινωνικές επιστήμες
και τμηματοποίηση (segmentation, partitioning) στη θεωρία
των γράφων.
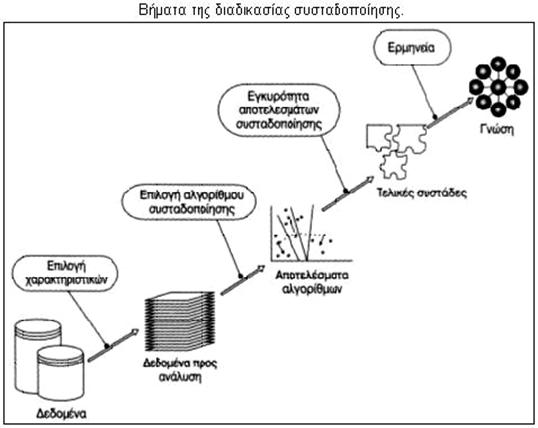
Εικόνα 15.5 Βήματα
Συσταδοποίησης
Η συσταδοποίηση (clustering) είναι μια
διαδικασία που εντάσσεται γενικότερα στην μη επιβλεπόμενη κατηγοριοποίηση
(unsupervised classification). Είναι σημαντικό να τονίσουμε την διαφορά μεταξύ
supervised και unsupervised classification.
v
Στην επιβλεπόμενη κατηγοριοποίηση (supervised
classification) ένα σύνολο από πρό-ομαδοποιημένα στοιχεία είναι διαθέσιμο,
και αυτό που μας ζητείται είναι να εντάξουμε ένα νέο στοιχείο σε κάποια από τις
υπάρχουσες ομάδες. Συνήθως τα προ-ομαδοποιημένα στοιχεία χρησιμοποιούνται για
να περιγράψουν τις διαφορετικές ομάδες – κλάσεις στις οποίες θα εντάξουμε νέα
στοιχεία.
v
Αντίθετα στην unsupervised classification και στην συσταδοποίηση το πρόβλημα
είναι να ομαδοποιήσουμε σε λογικές κλάσεις τα στοιχεία μας, χωρίς καμία γνώση για
προϋπάρχουσες ομάδες. Έτσι η κατηγοριοποιήση είναι απόλυτα οδηγούμενη από τα
δεδομένα (data driven) και παράγεται μόνο από αυτά.
Η συσταδοποίηση (clustering) βρίσκει
εφαρμογές σε πολλούς τομείς όπως η ανάλυση
προτύπων (pattern-analysis), η λήψη αποφάσεων (decision-making), η μηχανική
εκμάθηση (machine-learning), η εξόρυξη δεδομένων (data mining), η ανάκτηση
κειμένων (document retrieval) κ.α. Στις περισσότερες των περιπτώσεων που
εφαρμόζεται το Clustering υπάρχει μικρή γνώση για την δομή και το είδος των
στοιχείων π.χ. στατιστικά μοντέλα, που να περιγράφουν τα δεδομένα. Έτσι ο
υπεύθυνος για την λήψη των τελικών αποφάσεων και την εφαρμογή του Clustering
στα δεδομένα θα πρέπει να κάνει κάποιες υποθέσεις για τα δεδομένα. Κάτω από
αυτούς τους περιορισμούς η μεθοδολογία του Clustering διαφαίνεται ιδιαίτερα
κατάλληλη για την ανακάλυψη αλληλοσχησχετισμών μεταξύ των δεδομένων
προκειμένου να κατανοηθεί η δομή τους, κάτι που είναι και ο απώτερος στόχος.
Αλγόριθμοι συσταδοποίησης εμσωματώνονται και
στην ίδια την τεχνολογία των βάσεων δεδομένων όχι μόνο σαν τεχνική ανάλυσης
δεδομένων όπως ο αλγόριθμος K-means στον SQL Server 2005 , αλλά κυριότερα ως:
Οπτικοποίηση
μεγάλων βάσεων δεδομένων :
εύκολος εντοπισμός ομάδων και υποσυνόλων δεδομένων που έχουν παρόμοια χαρακτηριστικά
Κατάτμηση
βάσεων δεδομένων: μέθοδοι clustering χρησιμοποιούνται για τεμαχισμό βάσεων
δεδομένων σε ομογενή κομμάτια. Εύκολη συμπίεση δεδομένων
Βελτιστοποίηση Ευρετηρίων: Τα ευρετήρια κλειδιών ομοδοποιούνται
καλύτερα. Στην ORACLE
9i χρησιμοποιείται ο k-means σε δομές R-tree.
Ανακατασκευή ευρετηρίων: Μετά από πολλές εισαγωγές δεδομένων και την
μεταφορά ενός πίνακα σε άλλη βάση αναλαμβάνει ένας αλγόριθμος συσταδοποίησης (ο
dbscan) να ανακατασκευάσει
ευρετήρια σύμφωνα με τη φυσική τοποθέτηση των εγγραφών στο δίσκο.
15.7.2
Κατάταξη
Μεθόδων Συσταδοποίησης
Οι ίδιες οι μέθοδοι συσταδοποίησης μπορούν
να καταταχθούν με βάση: Τον τύπο δεδομένων που εισάγονται στον αλγόριθμο, Τη
μέθοδο που καθορίζει την συσταδοποίηση του συνόλου των δεδομένων, Τη θεωρία και
τις θεμελιώδεις έννοιες στις οποίες είναι βασισμένες οι τεχνικές ανάλυσης
συστάδας.
Κατάταξη με βάση τον τύπο των δεδομένων
1.Συσταδοποίηση αριθμητικών δεδομένων
2.Εννοιολογική Συσταδοποίηση (αριθμός
διαφορετικών στοιχείων)
Κατάταξη με βάση Μέδοδο
Συσταδοποίησης
v
Διαιρετική
συσταδοποίηση (Partitioning Clustering)
v
Ασαφής
συσταδοποίηση (Fuzzy Clustering)
v
Μη
ασαφής συσταδοποίηση (Crisp Clustering)
v
Συσταδοποίηση
βασισμένη στα δίκτυα Kohonen
(Kohonen Net Clustering)
v
Ιεραρχική Συσταδοποίηση (Hierarchical
Clustering)
v
Συσταδοποίηση
βασισμένη στην πυκνότητα (Density-based Clustering)
v
Συσταδοποίηση
βασισμένη σε πλέγμα (Grid-based
Clustering)
v
Συσταδοποίηση
υποχώρων (Subspace Clustering).
Κατάταξη με βάση Θεωρία Ορισμού
Συστάδας
n
Prototype
Based (μία συστάδα είναι τα
αντικείμενα που είναι πιο κοντά σε ένα πρωτότυπο (prototype) από ότι κάποιο άλλο αντικείμενο. Συνήθως
σαν πρωτότυπο επιλέγεται το μέσο των σημείων μίας συστάδας).
n
Well
Separated (μία συστάδα
είναι το σύνολο των αντικειμένων όπου κάθε αντικείμενο είναι πιο κοντά σε κάθε
άλλο αντικείμενο της συστάδας, από ότι σε κάποιο άλλο αντικείμενο).
n
Graph
Based (μία συνεκτική
συνιστώσα ή μία κλίκα του γραφήματος).
n
Density Based (μία πυκνή περιοχή αντικειμένων που περιβάλλεται από μία αραιή)
n
Shared
Property (conceptual
clusters) ( σύνολο αντικειμένων
που μοιράζονται μία ιδιότητα)
n
Κατηγοριοποίηση
με βάση τον τρόπο που γίνεται ο χειρισμός
της αβεβαιότητας από την άποψη της επικάλυψης συστάδας
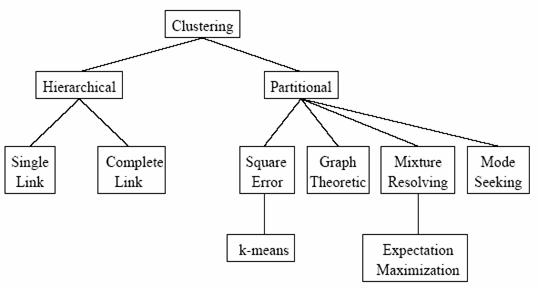
Εικόνα 15.6
Συνοπτική κατάταξη μεθόδων συσταδοποίησης
Η ανάλυση των
συστάδων δηλαδή η οργάνωση μιας συλλογής από δείγματα-στοιχεία (patterns) σε
συστάδες (clusters) γίνεται με βάση κάποιο μέτρο ομοιότητας. Τα στοιχεία συνήθως περιγράφονται σαν
διανύσματα τιμών κάποιων μέτρων ή αναπαριστώνται ως σημεία σε έναν πολυδιάστατο
χώρο. Στοιχεία που ανήκουν στην ίδια ομάδα παρουσιάζουν μεγαλύτερη ομοιότητα
από ότι στοιχεία που ανήκουν σε διαφορετικές ομάδες. Η ποικιλία τεχνικών για
την αναπαράσταση των δεδομένων, έκφρασης της ομοιότητας μεταξύ στοιχείων και
ομαδοποίησης των δεδομένων έχει ως αποτέλεσμα την ύπαρξη μιας πλούσιας συλλογής
μεθόδων συσταδοποίησης..
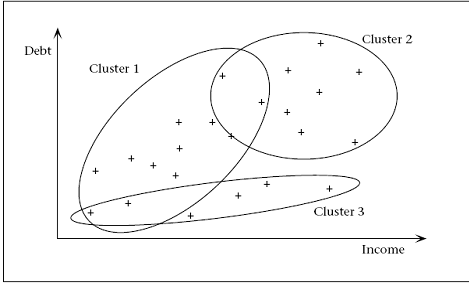
Εικόνα 15.7
Παράδειγμα διαιρετικής ασαφούς συσταδοποίησης
15.7.3
Η Διαδικασία Clustering
Συνήθως τα βήματα που ακολουθούνται κατά την
διαδικασία του Clustering είναι:
1.
Αναπαράσταση
των στοιχείων η οποία μπορεί να περιλαμβάνει παραγωγή νέων χαρακτηριστικών η
επιλογή μέρους των χαρακτηριστικών των στοιχείων. (Pattern
representation)
2.
Ορισμός
του μέτρου ομοιότητας μεταξύ των στοιχείων. (Similarity measure
definition)
3.
Η
καθεαυτή διαδικασία της ομαδοποίησης. (Clustering)
4.
Αφαίρεση
δεδομένων όταν χρειάζεται. (Data abstraction)
5.
Προσδιορισμός
και εκτίμηση του αποτελέσματος. (Assessment of output)
Η αναπαράσταση των στοιχείων αφορά
στον αριθμό των κλάσεων, τον αριθμό των διαθέσιμων στοιχείων, στον αριθμό και
τύπο των χαρακτηριστικών τα οποία ενδιαφέρουν τον αλγόριθμο του Clustering.
Ενδιαφέρον παρουσιάζει η διαδικασία της επιλογής χαρακτηριστικών κατά την οποία
βρίσκονται και επιλέγονται τα καταλληλότερα χαρακτηριστικά των στοιχείων τα
οποία θα χρησιμοποιηθούν για το Clustering. Εξάλλου, η διαδικασία της εξαγωγής
χαρακτηριστικών χρησιμοποιεί μετασχηματισμούς υπαρχόντων χαρακτηριστικών για
την παραγωγή άλλων τα οποία πιθανόν να είναι πιο ενδιαφέροντα.
|
ObjectID |
x |
y |
clusterID |
|
1158 |
7,97448173848523 |
0,123684334053648 |
|
|
1159 |
0,102073359974272 |
0,131579058117017 |
|
|
1160 |
0,127591699967849 |
0,134210632804845 |
|
|
1161 |
0,151515146164289 |
0,110526460614508 |
|
|
1162 |
0,090909093584522 |
7,89474024975334 |
|
|
1163 |
0,167464113565217 |
8,68421265609022 |
|
|
1164 |
7,01754349823185 |
5,78948049950247 |
|
|
1165 |
8,45294987762255 |
2,10527593657782 |
|
|
1166 |
0,12599680617073 |
0,34535675786 |
|
|
1167 |
0,149920252367171 |
2,63159087414341 |
|
|
|
|
|
|
Στην παρούσα πτυχιακή εργασία χρησιμοποιούμε
δείγμα δεδομένων από αντικείμενα μίας και δύο διαστάσεων
Το μέτρο ομοιότητας μεταξύ των στοιχείων καθορίζεται από μια
συνάρτηση απόστασης. Ένα μέτρο απόστασης όπως η Ευκλείδεια απόσταση μπορεί
να χρησιμοποιηθεί για να αντικατοπτρίσει την διαφορά-ανομοιότητα μεταξύ δύο
στοιχείων, ενώ άλλα μέτρα απόστασης ποσοτικοποιούν την ομοιότητα των στοιχείων.
Στην παρούσα πτυχιακή εργασία για τον αλγόριθμο k-means χρησιμοποιείται η ευκλείδια απόσταση. D(x,y) = 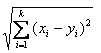
Η διαδικασία του Clustering μπορεί να
πραγματοποιηθεί με πολλούς τρόπους. Το αποτέλεσμα μπορεί να είναι απόλυτα
καθορισμένο (ομαδοποίηση των δεδομένων σε ξένες μεταξύ τους κλάσεις), ή fuzzy
(όπου κάθε στοιχείο δεν ανήκει μόνο σε μία κλάση αλλά είναι μέλος όλων των
κλάσεων με κάποιο βαθμό σε κάθε μια). Οι αλγόριθμοι ιεραρχικού Clustering
παράγουν μια σειρά από εμφωλευμένες κλάσεις μετά από διαδικασίες διαχωρισμού ή
συγχώνευσης με βάση το μέτρο ομοιότητας μεταξύ των στοιχείων διαφορετικών
ομάδων. Οι αλγόριθμοι διαμεριστικού clustering από την μεριά τους στοχεύουν στο να
διαχωρίσουν τα δεδομένα με τέτοιο τρόπο ώστε να βελτιστοποιείται το κριτήριο με
το οποίο γίνεται το Clustering, πιθανόν κάποιο μέτρο ομοιότητας η διαφοροποίησης.
Άλλες τεχνικές Clustering βασίζονται στην θεωρία των πιθανοτήτων και άλλες σε
θεωρία γράφων. Στην παρούσα εργασία χρησιμοποιούμε αλγόριθμους διαμεριστικού clustering (k-means) και fuzzy clustering (fuzzy c-means).
Η αφαίρεση δεδομένων είναι διαδικασία κατά την οποία το σύνολο των
δεδομένων αποκτά μια απλή και συμπαγή αναπαράσταση. Συνήθως η αφαίρεση
δεδομένων στο Clustering είναι μια συνοπτική αναπαράσταση κάθε κλάσης με την
βοήθεια κάπου αντιπροσώπου στοιχείου το οποίο καλείται κεντροειδές
(centroid). Στην παρούσα πτυχιακή εργασία κάθε
συστάδα αντιπροσωπεύεται από το κέντρο βάρους της Centroid.
Centroid =![]() .
.
Τέλος η εκτίμηση της διαδικασίας του
Clustering προσπαθεί να εκτιμήσει το αποτέλεσμα ενός αλγορίθμου, να βρει τι
χαρακτηρίζει μια καλή διαδικασία από μια όχι και τόσο επιτυχή. Κυρίως αυτό που
εκτιμάται είναι το τελικό αποτέλεσμα, δηλαδή κατά πόσο οι κλάσης που
δημιουργήθηκαν έχουν νόημα και κατά πόσο αυτές δεν δημιουργήθηκαν κατά τυχαίο
τρόπο εξαιτίας του συγκεκριμένου αλγορίθμου που χρησιμοποιήθηκε.
15.7.4 Ιεραρχικό ,
Διαμεριστικό Και Ασαφές Clustering
Υπάρχει ένας μεγάλος αριθμός αλγορίθμων που
ασχολούνται με την ιεραρχική, διαμεριστική και η ασαφής (fuzzy) συσταδοποίηση, οι οποίες έχουν μελετηθεί
στην εξόρυξη γνώσης, την μηχανική μάθηση, την Στατιστική και την αναγνώριση
προτύπων.
|
Hierarchical
Clustering |
Partitional
Clustering |
Fuzzy
Clustering |
|
AGNES |
Κ- Means
|
Fuzzy C-Means |
|
DIANA |
K-medoids (ΡΑΜ) |
Fuzzy c-medoids |
|
CURE |
Κ-mode (conceptual) |
Fuzzy Kohonen
Network |
|
ROCK (conceptual) |
CLARA |
|
Στο Ιεραρχικό
Clustering ένας αλγόριθμος που χρησιμοποιεί την
ιεραρχία παράγει ένα δεντρόδιάγραμμα που αναπαριστά μια ένθετη σχέση ομαδοποίησης
μεταξύ των αντικειμένων. Αν η ιεραρχία για την συσταδοποίηση είναι από κάτω
προς τα πάνω, στην αρχή κάθε αντικείμενο αποτελεί και μια συστάδα και μετά
μικρές συστάδες ενώνονται σε μεγαλύτερες σε κάθε επίπεδο ιεραρχίας μέχρι το
τελευταίο επίπεδο ιεραρχίας. Αυτό το είδος της μεθόδου ονομάζεται συσσωρευτική.
Η αντίστροφη μέθοδος λέγεται διαιρετική ιεραρχική μέθοδος.
Στο διαμεριστικό
clustering οι Αλγόριθμοι προσπαθούν να διασπάσουν ένα
σύνολο από n αντικείμενα σε k συστάδες (συμπλέγματα) με βάση την απόστασή τους.
Το επιθυμητό πλήθος k των συμπλεγμάτων δίνεται ως είσοδος. Η
βασική ιδέα του διαμερισμού είναι αρκετά διαισθητική και η διαδικασία γίνεται
ουσιαστικά για να επιτευχθούν σταθερά βέλτιστα κριτήρια κατά επανάληψη. Οι πιο
γνωστοί αλγόριθμοι που ανήκουν σε αυτή την κατηγορία είναι οι k-means και k-medoid όπου η κάθε συστάδα
αντιπροσωπεύεται από το κέντρο βάρους (Centroid =![]() ) της συστάδας στον k-means ή από το πιο
κεντρικό σημείο (Medoid)
της συστάδας στην μέθοδο k-medoid. Μόλις επιλεχτούν οι
αντιπρόσωποι συστάδων, τα σημεία των αντικειμένων ορίζονται σε αυτούς τους
αντιπροσώπους, και επαναληπτικά, νέοι καλύτεροι αντιπρόσωποι επιλέγονται και τα σημεία
επανεκχώρούνται έως ότου δεν γίνεται καμία αλλαγή.
) της συστάδας στον k-means ή από το πιο
κεντρικό σημείο (Medoid)
της συστάδας στην μέθοδο k-medoid. Μόλις επιλεχτούν οι
αντιπρόσωποι συστάδων, τα σημεία των αντικειμένων ορίζονται σε αυτούς τους
αντιπροσώπους, και επαναληπτικά, νέοι καλύτεροι αντιπρόσωποι επιλέγονται και τα σημεία
επανεκχώρούνται έως ότου δεν γίνεται καμία αλλαγή.
Το fuzzy clustering επεκτείνει την έννοια
του «ένα στοιχείο ανήκει σε ένα cluster»
και συνδέει κάθε στοιχείο με όλα τα clusters χρησιμοποιώντας μια συνάρτηση
συμμετοχής μέλους. Το αποτέλεσμα είναι κάποια σύνολα από στοιχεία αλλά όχι μια απόλυτη
διαμέριση του χώρου δεδομένων.
15.7.5 Αλγόριθμοι Ιεραρχικού clustering
Το πως λειτουργεί ένας ιεραρχικός αλγόριθμος
clustering φαίνεται στα παρακάτω σχήματα χρησιμοποιώντας τα δεδομένα ενός
δισδιάστατου χώρου τα οποία μπορούν να ομαδοποιηθούν όπως παρουσιάζεται στο
σχήμα 15.8. Εδώ υπάρχουν επτά στοιχεία τα οποία σχηματίζουν τρία clusters.
Ένας ιεραρχικός αλγόριθμος μπορεί να
αποδοθεί με ένα δενδροδιάγραμμα το οποίο παρουσιάζει τις συγχωνεύσεις στοιχείων
για την δημιουργία clusters και τα επίπεδα ομοιότητας με βάση τα οποία αλλάζουν
οι ομάδες και διαμορφώνονται τα clusters. Το δενδροδιάγραμμα ή
δενδρόγραμμα που αντιστοιχεί στα
δεδομένα του σχήματος 15.8 παρουσιάζεται στο σχήμα 15.9. Χαρακτηριστικό του
διαγράμματος είναι τα διάφορα επίπεδα στα οποία αποδίδονται διαφορετικές
ομαδοποιήσεις.
Εικόνα 15.8 : Σημεία σε τρία clusters Εικόνα 15.9 : Δενδοδιάγραμμα
ιεραρχίας
Οι περισσότεροι ιεραρχικοί αλγόριθμοι είναι
παραλλαγές των αλγορίθμων απλού-συνδέσμου(single-link), του πλήρους-συνδέσμου(complete-link).
Οι διαφορά μεταξύ των αλγορίθμων αυτών έχει να κάνει με τον τρόπο με τον οποίο
ορίζουν την ομοιότητα μεταξύ στοιχείων και κατά συνέπεια clusters πριν την
συγχώνευσή τους.
Ø
Στην περίπτωση του απλού-συνδέσμου
η απόσταση μεταξύ δύο clusters είναι η ελάχιστη από τις αποστάσεις μεταξύ όλων
των ζευγών στοιχείων από τα δύο clusters (κάθε ζεύγος περιέχει ένα στοιχείο από
το ένα cluster και ένα από το άλλο).
Ø
Στον αλγόριθμο πλήρους-συνδέσμου η απόσταση
μεταξύ δύο clusters είναι η μέγιστη από τις αποστάσεις μεταξύ όλων των ζευγών
στοιχείων από τα δύο clusters.
Και στις δύο περιπτώσεις απλού-συνδέσμου και
πλήρους-συνδέσμου δυο συστάδες συγχωνεύονται για να δημιουργήσουν μία όταν η
απόσταση των δύο συστάδων, όπως και αν ορίζεται είναι ελάχιστη. Έχει αποδειχτεί
ότι ο αλγόριθμος του πλήρους συνδέσμου δημιουργεί καλύτερα, πιο συμπαγή
clusters. Αντίθετα ο αλγόριθμος του απλού-συνδέσμου έχει την τάση να δημιουργεί
σκόρπια και επιμήκη clusters.
Στο σχήμα 6 φαίνονται μια σειρά από στοιχεία
τα οποία ορίζουν δύο clusters αλλά χωρίζονται από σημεία τα αποτελούν θόρυβο
και δεν μας ενδιαφέρουν. Ο αλγόριθμος απλού-συνδέσμου δημιουργεί τα clusters
που φαίνονται στο σχήμα 6 και ο αλγόριθμος πλήρους συνδέσμου δημιουργεί τα
clusters του σχήματος 7. Είναι προφανές ότι στην δεύτερη περίπτωση τα clusters
είναι πιο συμπαγή από την πρώτη στην οποία τα στοιχεία θορύβου έχουν
δημιουργήσει ανεπιθύμητα φαινόμενα.
Εικόνα 15.10: Clustering απλού- Εικόνα15.11: Clustering
πλήρους-
συνδέσμου
συνδέσμου
Παρόλα αυτά ο αλγόριθμος απλού συνδέσμου
είναι αρκετά ευέλικτος σε δύσκολες περιπτώσεις. Για παράδειγμα ο αλγόριθμος
απλού-συνδέσμου μπορεί να εξάγει τα ομόκεντρα clusters που φαίνονται στο σχήμα
15.10 ενώ ο αλγόριθμος πλήρους-συνδέσμου στο σχήμα 15.11 δεν μπορεί. Τελικά
κανείς από του δύο αλγορίθμους δεν είναι πανάκεια. Διαφαίνεται όμως ότι ο
δεύτερος παράγει καλύτερες και πιο χρήσιμες ιεραρχίες από τον πρώτο σε πολλές
εφαρμογές.
Εικόνα 15.12 : Δύο ομοκεντρικά clusters.
15.7.6 Διαμεριστικοί Αλγόριθμοι
Ένας διαμεριστικός αλγόριθμος έχει ως
αποτέλεσμα μια διαμέριση του χώρου των δεδομένων σε αντίθεση με τους
ιεραρχικούς αλγορίθμους που δημιουργούν πιο πολύπλοκες δομές που περιγράφονται
από τα δενδρογράμματα.
Οι αλγόριθμοι αυτοί υπερτερούν σε
περιπτώσεις όπου τα δεδομένα είναι παρά πολλά και η δημιουργία
δενδροδιαγραμματων είναι αδύνατη. Το κυρίως πρόβλημα των αλγορίθμων αυτών είναι
η απόφαση για τον αριθμό των τελικών clusters. Ο αριθμός αυτός καθορίζεται
κυρίως από την προσπάθεια βελτιστοποίησης μιας συνάρτησης. Στην πραγματικότητα
αυτό που γίνεται είναι να τρέχει ο αλγόριθμος για διάφορους αριθμούς από
clusters και να επιλέγεται εκείνη η τελική κατάσταση η οποία βελτιστοποιεί την
παραπάνω συνάρτηση.
Η κριτήριο που χρησιμοποιείται κυρίως σε
διαμεριστικούς αλγορίθμους για την τελική απόφαση του αριθμού των clusters
είναι το κριτήριο του τετραγωνικού σφάλματος ή η συνάρτηση τετραγωνικού
σφάλματος (squared error function). Αυτή η συνάρτηση ορίζεται για ένα αποτέλεσμα clustering L με σύνολο στοιχείων S και Κ clusters ως εξής:
![]()
όπου ![]() είναι το i στοιχείο του j cluster, και το
είναι το i στοιχείο του j cluster, και το ![]() είναι το κεντροειδές του j cluster.
είναι το κεντροειδές του j cluster.
Ο αλγόριθμος k-means είναι ένας πολύ απλός
και πολύ διαδεδομένος διαμεριστικός αλγόριθμος. Ο αλγόριθμος ξεκινά με μια
τυχαία διαμέριση σε clusters και συνεχώς τοποθετεί στοιχεία στα clusters με
βάση την απόσταση των στοιχείων από το κεντροειδές του cluster. Αυτό σταματάει
μέχρι να ικανοποιηθεί κάποιο κριτήριο το οποίο μπορεί να είναι η ελαχιστοποίηση
της συνάρτησης τετραγωνικού σφάλματος ή η μη διαφοροποίηση των clusters από
κάποια επανάληψη και μετά.
Ο αλγόριθμος k-means είναι δημοφιλής
εξαιτίας της απλότητας υλοποίησης του και της πολυπλοκότητας του η οποία είναι
της τάξης O(tkn), όπου n τα αντικείμενα, k οι συστάδες και t οι επαναλήψεις. Το πρόβλημα που έχει αυτός
ο αλγόριθμος είναι στην αρχική επιλογή των clusters. Αν η επιλογή αυτή δεν
είναι αρκετά προσεκτική τότε το κριτήριο τετραγωνικού λάθους συγκλίνει σε
τοπικά ελάχιστο κάνοντας την τελική επιλογή cluster ανεπιτυχή.
Ας θεωρήσουμε το χώρο του σχήματος 9 με επτά
στοιχεία. Αν η αρχική μας επιλογή είναι τρία clusters με αρχικά στοιχεία το Α,B,C
στο καθένα, το αποτέλεσμα του clustering θα είναι αυτό που φαίνεται στο σχήμα
με τις ελλείψεις.
Αντίθετα αν η αρχική επιλογή είναι τα
clusters με σημεία το Α,D,F τα τελικά clusters φαίνονται με τα
παραλληλόγραμμα. Στην πρώτη περίπτωση το κριτήριο τετραγωνικού λάθους είναι
αρκετά μεγαλύτερο από την δεύτερη περίπτωση στη
όποία επιλέξαμε διαφορετική αρχική διαμέριση.
Εικόνα 15.13:
Ευαισθησία του αλγορίθμου k-means
στην αρχική επιλογή
clusters.
1. Επιλογή k κεντοειδών cluster τα οποία αποτελούν και
τα μόνα στοιχεία των k
επελεγμένων clusters.
2. Τοποθέτησε κάθε στοιχείο στο πιο κοντινό
cluster μετά από υπολογισμό της απόστασης του σημείου από το κεντροειδές του
cluster.
3. Υπολόγισε το νέο κεντροειδές.
4. Αν το κριτήριο τερματισμού δεν ικανοποιείται
πήγαινε στο βήμα 2.
Fuzzy
clustering
Μέχρι τώρα έχουμε δει ότι όλες οι τεχνικές
και οι αλγόριθμοι clustering τοποθετούν ένα στοιχείο σε ένα και μόνο cluster, σε
αυτό που τελικά ανήκει. Πρόκειται λοιπόν για «σκληρούς» αλγόριθμους και αυτό
συνεπάγεται ότι τα clusters σε αυτές τις περιπτώσεις είναι ξένα μεταξύ τους
σύνολα. Το fuzzy clustering επεκτείνει την έννοια του «ένα στοιχείο ανήκει σε ένα cluster» και συνδέει
κάθε στοιχείο με όλα τα clusters χρησιμοποιώντας μια συνάρτηση μέλους. Το
αποτέλεσμα είναι κάποια σύνολα από στοιχεία αλλά όχι μια απόλυτη διαμέριση του
χώρου δεδομένων. Ένας αλγόριθμος fuzzy clustering κάνει τα εξής σε γενικές
γραμμές:
1.
Επιλογή
μιας fuzzy διαμέρισης των Ν στοιχείων σε Κ clusters. Καθορισμός του πίνακα U=ΝxΚ
του οποίου κάθε στοιχείο uij δηλώνει τον βαθμό συμμετοχής του στοιχείου i στο cluster j. Η τιμές των u είναι μεταξύ 0 και 1.
2.
Χρησιμοποιώντας
τον πίνακα U βρίσκεται η τιμή
κάποιας συνάρτησης που αποτελεί και το κριτήριο τερματισμού, και η οποία πρέπει
να βελτιστοποιηθεί. Συνεχώς επανατοποθετούμε στοιχεία στα clusters με νέες
τιμές συμμετοχής και επαναπροσδιορίζουμε τον πίνακα U και την τιμή της συνάρτησης.
3.
Επαναλαμβάνουμε
το βήμα 2 μέχρι να μην επέρχονται σημαντικές αλλαγές στον πίνακα U και την τιμή της συνάρτησης.
Στο σχήμα 10 φαίνεται η ιδέα του fuzzy
clustering. Τα παραλληλόγραμμα Η1 και Η2 εκφράζουν τα clusters μετά από κάποιον
σκληρό αλγόριθμο, ενώ οι ελλείψεις δείχνουν δύο fuzzy clusters, το F1 και F2. Τα στοιχεία των ελλείψεων συνοδεύονται
από τιμές συμμετοχής σε κάθε cluster. Έτσι το cluster F1 περιγράφεται από το σύνολο τιμών {(1,0.9),
(2,0.8), (3,0.7), (4,0.6), (5,0.55), (6,0.4), (7,0.35), (8,0.0), (9,0.0)}.
Αντίστοιχα με ένα τέτοιο σύνολο περιγράφεται και το cluster F2. Κάθε ζευγάρι τιμών (i, μ) σε αυτό το σύνολο εκφράζει το ποσοστό
συμμετοχής μ του στοιχείου i στο cluster αυτό.
Εικόνα 15.14 Fuzzy clustering
15.8
Ανάλυση Αλγορίθμου K-Means
Ο K-means είναι ένας από τους πιο απλούς και εύκολους
στην εκμάθηση αλγόριθμους για την επίλυση προβλημάτων συσταδοποίησης. Η
διαδικασία είναι ένας απλός τρόπος να διαχωρίσουμε ένα σύνολο δεδομένων (data set) σε ένα αριθμό k clusters ο οποίος δηλώνετε από πριν. Η βασική ιδέα
είναι να καθορίσουμε ένα κεντροειδές (centroid) για κάθε cluster.
Αυτά τα centroids πρέπει να
επιλεγούν κατάλληλα διότι κάθε διαφορετικό centroid μπορεί να οδηγήσει σε διαφορετικό αποτέλεσμα.
Έτσι, η καλύτερη επιλογή είναι να τοποθετηθούν όσο το δυνατόν μακρύτερα το ένα
από το άλλο. Το επόμενο βήμα είναι να ληφθεί κάθε σημείο που ανήκει σε ένα
δεδομένο σύνολο στοιχείων και να συνδεθεί το κοντινότερο centroid. Όταν τελειώσουν όλα τα σημεία, το πρώτο
βήμα ολοκληρώνεται και μια πρόωρη ομάδα cluster είναι έτοιμη. Σε αυτό το σημείο πρέπει να
υπολογίσουμε εκ νέου νέα centroids Κ των συστάδων(clusters) ως αποτέλεσμα του προηγούμενου βήματος.
Αφότου έχουμε αυτά τα νέα centroids Κ, μια νέα σύνδεση πρέπει να γίνει μεταξύ των ίδιων καθορισμένων
σημείων στοιχείων και το κοντινότερο νέο centroid. Ένας βρόχος έχει παραχθεί. Ως αποτέλεσμα
αυτού του βρόχου μπορούμε να παρατηρήσουμε ότι centroids Κ αλλάζουν τη θέση τους βαθμιαία έως ότου
δεν γίνονται άλλες αλλαγές.
Αν και μπορεί να αποδειχθεί ότι η διαδικασία
θα τερματίζει πάντα, ο αλγόριθμος Κ-Means δεν βρίσκει απαραιτήτως τη βέλτιστη κατάταξη των δεδομένων στις
συστάδες(clusters). Ο αλγόριθμος
είναι επίσης σημαντικά ευαίσθητος στα αρχικά τυχαία επιλεγμένα κέντρα συστάδων.
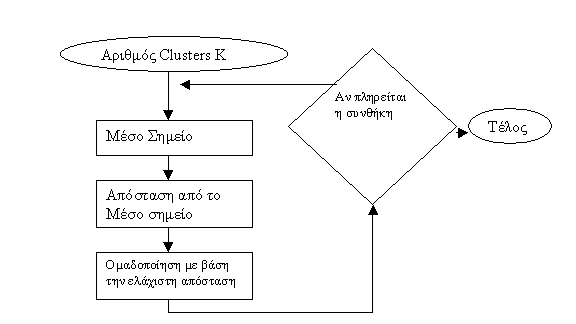
Εικόνα 15.15 O Αλγόριθμος K-Means
·
Βήμα
1ο : Διαλέγουμε τον αριθμό
των συστάδων που επιθυμούμε.
·
Βήμα
2ο : Διαλέγουμε τυχαία τα
Κέντρα ( Centroid) κάθε cluster.
·
Βήμα
3ο : Παίρνουμε κάθε δείγμα
στη σειρά και υπολογίζουμε την απόσταση του από το Μέσο Σημείο κάθε συστάδας.
Αν το δείγμα δεν είναι στη συστάδα με το κοντινότερο προς αυτό Μέσο Σημείο τότε
του αλλάζουμε συστάδα και υπολογίζουμε ξανά το Μέσο Σημείο και της συστάδας που
έχασε το δείγμα αλλά και της συστάδας που προστέθηκε το δείγμα.
·
Βήμα
4ο : Επαναλαμβάνουμε το 3ο
βήμα μέχρι να πληρούνται οι προϋποθέσεις δηλαδή σε μία επανάληψη που δεν θα
υπάρξει καμία μετακίνηση δείγματος ή μέχρι να ολοκληρωθεί ο αριθμός των
επαναλήψεων που έχει οριστεί.
·
Αν ο αριθμός των δεδομένων είναι μικρότερος
από τον αριθμό των συστάδων τότε αναθέτουμε κάθε δεδομένο σαν Μέσο Σημείο της
Συστάδας. Κάθε Μέσο Σημείο θα έχει έναν αριθμό Συστάδας.
Αν ο αριθμός των δεδομένων είναι
μεγαλύτερος από τον αριθμό των συστάδων
τότε, για όλα τα δεδομένα, υπολογίζουμε τις αποστάσεις από όλα τα Μέσα Σημείο
για να πάρουμε τις μικρότερες αποστάσεις. Το δεδομένο θα ανήκει στη συστάδα από
την οποία έχει την μικρότερη απόσταση.
Αφού δεν είμαστε σίγουροι για την θέση του Μέσου
Σημείου, το υπολογίζουμε και πάλι με βάση τα ανανεωμένα δεδομένα. Τότε
αναθέτουμε όλα τα δεδομένα με βάση το νέο Μέσο Σημείο. Η διαδικασία
επαναλαμβάνετε μέχρι να μην υπάρχει καμία μετακίνηση δεδομένων σε άλλη συστάδα.
Παράδειγμα Xρήσης
του αλγορίθμου K-Means
Υποθέτουμε πως έχουμε 4 αντικείμενα (objects) και το καθένα έχει από 2 χαρακτηριστικά
|
Object |
Attribute 1 (X): weight |
Attribute
2 (Y): pH |
|
Medicine A |
1 |
1 |
|
Medicine B |
2 |
1 |
|
Medicine C |
4 |
3 |
|
Medicine D |
5
|
4
|
Θέλουμε να χωρίσουμε τα δεδομένα σε 2
συστάδες (Cluster 1 και Cluster 2). Τώρα πρέπει να υπολογίσουμε πιο Medicine (object) ανήκει στο 1ο cluster και ποιο στο 2ο. Κάθε medicine αποτελεί ένα σημείο το οποίο έχει 2
χαρακτηριστικά.
Λύση
Η βασική διαδικασία του K Means
1.
Καθορίζουμε
το κέντρο(centroid) κάθε cluster
2.
Υπολογίζουμε
την απόσταση κάθε σημείου από το κέντρο(centroid)
3.
Ομαδοποιούμε
τα δεδομένα με βάση την ελάχιστη απόσταση
Στο παραπάνω παράδειγμα έχουμε 4 είδη medicine και κάθε ένα από αυτά έχει από 2
χαρακτηριστικά. Σκοπός μας είναι να τα διαχωρίσουμε σε Κ = 2 ομάδες με βάση τα
2 χαρακτηριστικά (ph και
weight)
1. Αρχική τιμή των centroid : Επιλέγουμε τα σημεία των Medicine
A και Medicine B σαν τα αρχικά κέντρα των 2 cluster οπότε, C1 =
(1,1) και C2 = (2,1)
2. Υπολογισμός απόστασης σημείου από centroid:
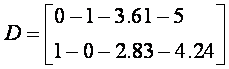
C1 = (1,1)
C2 = (2,1)
A B
C D
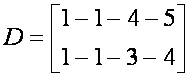 X,Y
X,Y
Η πρώτη σειρά στο πίνακα των αποστάσεων
αντιστοιχεί στην απόσταση κάθε αντικειμένου πρώτο centroid και η δεύτερη σειρά
είναι η απόσταση κάθε αντικειμένου δεύτερο centroid. Π. χ, απόσταση από την C = (4, 3) στον πρώτο centroid
c1 ,![]() και η απόσταση από το 2ο centroid c2
και η απόσταση από το 2ο centroid c2 ![]() είναι κ.ο.κ.
είναι κ.ο.κ.
3. Συσταδοποίηση
δεδομένων : Ορίζουμε κάθε σημείο σε ένα cluster με βάση την ελάχιστη απόσταση. Συνεπώς, medicine A θα ανήκει στο group 1, medicine B στο group
2, medicine C στο group 2 and medicine D στο group 2.
4.Υπόλογισμός νέων centroid: Γνωρίζοντας τα μέλη κάθε group υπολογίζουμε το νέο centoid κάθε cluster
με βάση τις νέες συμμετοχές. Το cluster 1 έχει μόνο ένα σημείο οπότε το centroid παραμένει το ίδιο, στο 2ο cluster έχουμε 3 μέλη και το νέο centroid θα είναι (![]()
![]() ),C2 =
(11/3,8/3)
),C2 =
(11/3,8/3)
4.
Υπολογίζουμε
και πάλι τις αποστάσεις των σημείων από τα cluster :
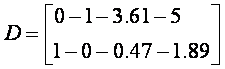
C1 = (1,1)
C2 = (11/3,8/3)
A B
C D
 X,Y
X,Y
6. Συσταδοποίηση δεδομένων : Ορίζουμε
κάθε σημείο σε ένα cluster
με βάση την ελάχιστη απόσταση. Τα cluster 1 και 2 έχουν τώρα από 2 δεδομένα
7. Υπολογισμός νέων centroid: Γνωρίζοντας τα μέλη κάθε group υπολογίζουμε το νέο centoid κάθε cluster
με βάση τις νέες συμμετοχές.
C1 = (1+2 / 2, 1+1 / 2 ) = (1.5 , 1 ) και C2 =
(4+5 / 2, 3+4 / 2 ) = (4.5 , 3,5 )
8. Υπολογισμός απόστασης σημείου από centroid
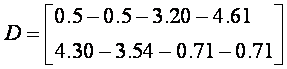
C1 = (1*1/2.5,1), C2
= (4*1/2,3*1/2)
A B
C D
X,Y
9. Συσταδοποίηση δεδομένων : Ορίζουμε
κάθε σημείο σε ένα cluster
με βάση την ελάχιστη απόσταση. Πλέον στο 1ο cluster έχουμε 2 σημεία (1,1) και (2,1) και στο 2ο (4,3) (5,4)
Ο αλγόριθμος εκτελείτε μέχρι να πληρωθεί η
συνθήκη που έχει οριστεί από πριν είτε μέχρι να μην υπάρχει μετακίνηση δεδομένων μεταξύ των cluster είτε μέχρι να ολοκληρωθεί ένας
προκαθορισμένος αριθμός επαναλήψεων.
Κεφάλαιο 16. Σύγχρονα Θέματα Βάσεων Δεδομένων
Στο κεφαλαίο αυτό γίνεται μια γενική αναφορά στις
έννοιες των χωρικών και / πολυμεσικών βάσεων δεδομένων, που αποτελούν έναν
τομέα σύγχρονο με μεγάλο ενδιαφέρον και
προοπτική. Επίσης γίνεται εκτενής και λεπτομερής περιγραφή των
συστημάτων διαχείρισης βιντεο -βάσεων δεδομένων μιας και το βίντεο είναι ο πλουσιότερος, σε χαρακτηριστικά, τύπος πολυμέσων.
16.1Εισαγωγή Στις Eέννοιες Των Χωρικών Βάσεων Δεδομένων
Οι χωρικές βάσεις δεδομένων υποστηρίζουν
έννοιες για βάσεις δεδομένων που καταγράφουν
αντικείμενα σ' έναν πολυδιάστατο χώρο. Για παράδειγμα, χαρτογραφικές βάσεις δεδομένων που αποθηκεύουν χάρτες
περιέχουν δισδιάστατες χωρικές περιγραφές των αντικειμένων τους -από
χώρες και πολιτείες σε ποταμούς, πόλεις δρόμους,
θάλασσες κοκ. Αυτές οι βάσεις δεδομένων χρησιμοποιούνται σε πολλές εφαρμογές
όπως περιβαλλοντολογικές, ενεργειακές και διαχείρισης μαχών. Άλλες βάσεις δεδομένων, όπως μετεωρολογικές βάσεις
δεδομένων για καιρικές πληροφορίες, είναι τρισδιάστατες, αφού οι θερμοκρασίες
και οι άλλες μετεωρολογικές πληροφορίες σχετίζονται με τρισδιάστατα
χωρικά σημεία. Γενικά, μια χωρική βάση δεδομένων αποθηκεύει αντικείμενα που
περιγράφονται με χωρικά χαρακτηριστικά. Οι
χωρικές συσχετίσεις μεταξύ των αντικειμένων είναι σημαντικές και συχνά είναι απαραίτητες όταν γίνονται επερωτήσεις στη βάση
δεδομένων. Αν και γενικά μια χωρική
βάση δεδομένων μπορεί να αναφέρεται σ' ένα χώρο n διαστάσεων για οποιοδήποτε η,
για απλότητα θα περιορίσουμε την εξέταση μας σε δύο διαστάσεις.
Οι κυρίες επεκτάσεις που
απαιτούνται για χωρικές βάσεις δεδομένων είναι μοντέλα που μπορούν να
ερμηνεύσουν τα χωρικά χαρακτηριστικά. Επιπλέον, για βελτίωση της απόδοσης συχνά απαιτούνται ειδικές δομές ευρετηρίων και
αποθήκευσης. Ας εξετάσουμε πρώτα μερικές από τις επεκτάσεις του μοντέλου
για χωρικές βάσεις δεδομένων δύο
διαστάσεων. Οι βασικές επεκτάσεις που χρειάζονται είναι να συμπεριληφθούν
γεωμετρικές έννοιες δύο διαστάσεων όπως σημεία, γραμμές και τμήματα γραμμών, κύκλοι, πολύγωνα και τόξα ώστε να
προσδιορίζονται τα χωρικά χαρακτηριστικά
των αντικειμένων. Επιπλέον χρειάζονται χωρικές πράξεις για να εφαρμοσθούν στα
χωρικά χαρακτηριστικά των αντικειμένων -για παράδειγμα, να υπολογισθεί η
απόσταση μεταξύ δύο αντικειμένων- καθώς και λογικές χωρικές συνθήκες -για παράδειγμα, να ελεγχθεί αν δύο αντικείμενα
επικαλύπτονται χωρικά. Για να
δειχθεί αυτό, θεωρήστε μια βάση δεδομένων που χρησιμοποιείται για εφαρμογές διαχείριση; έκτακτων αναγκών. Χρειάζεται μια
περιγραφή των χωρικών θέσεων πολλών τύπων αντικειμένων. Μερικά από τα
αντικείμενα αυτά γενικά έχουν στατικά χωρικά χαρακτηριστικά, όπως δρόμοι και
εθνικές οδοί, αντλίες νερού (για έλεγχο
πυρκαγιών), αστυνομικά τμήματα, πυροσβεστικοί σταθμοί και νοσοκομεία. Άλλα
αντικείμενα έχουν δυναμικά χωρικά χαρακτηριστικά που αλλάζουν χρονικά, όπως αστυνομικά οχήματα, ασθενοφόρα ή
πυροσβεστικά οχήματα.
16.1.1
Κατηγορίες Τυπικών Χωρικών Ερωτημάτων
Υπάρχουν τρεις κατηγορίες τυπικών
χωρικών ερωτημάτων:
Ερώτημα διαστήματος: Βρίσκει τα
αντικείμενα ενός συγκεκριμένου τύπου που βρίσκονται μέσα σε δεδομένη
χωρική περιοχή ή σε συγκεκριμένη απόσταση από δοθείσα θέση. (Για παράδειγμα,
βρίσκει όλα τα νοσοκομεία που βρίσκονται
στην περιοχή της Αθήνας ή βρίσκει όλα τα ασθενοφόρα σε απόσταση πέντε
χιλιομέτρων από τη θέση ενός ατυχήματος).
Ερώτημα για τον κοντινότερο γείτονα: Βρίσκει ένα
αντικείμενο συγκεκριμένου τύπου που
βρίσκεται πιο κοντά σε δεδομένη θέση. (Για παράδειγμα, βρίσκει το περιπολικό
που βρίσκεται πιο κοντά σε συγκεκριμένη θέση).
Χωρικές συνενώσεις ή επικαλύψεις:
Τυπικά συνενώνει αντικείμενα δύο τύπων
με βάση κάποια χωρική συνθήκη, όπως αντικείμενα που τέμνονται ή επικαλύπτονται χωρικά ή που βρίσκονται σε κάποια
απόσταση το ένα από το άλλο. (Για
παράδειγμα, βρίσκει όλες τις πόλεις που βρίσκονται σ' έναν
αυτοκινητόδρομο ή βρίσκει όλα τα σπίτια που απέχουν δύο μίλια από μια λίμνη.)
Για να απαντηθούν
αποτελεσματικά αυτοί και άλλοι τύποι χωρικών επερωτήσεων χρειάζονται
ειδικές τεχνικές για χωρικά ευρετήρια. Μια από τις πιο γνωστές τεχνικές είναι η
χρήση R-δένδρων και των παραλλαγών τους, που έχουν εξηγηθεί με λεπτομέρεια σε
προηγούμενο κεφάλαιο. Τα R-δένδρα ομαδοποιούν στους ίδιους τερματικούς κόμβους
(φύλλα) ενός δομημένου δενδροειδούς ευρετηρίου τα αντικείμενα που βρίσκονται
φυσικά κοντά με κάποια χωρική προσέγγιση. Αφού ένα φύλλο μπορεί να δείχνει μόνο
σε κάποιο πλήθος αντικειμένων, χρειάζονται
αλγόριθμοι για τον διαχωρισμό του χώρου σε ορθογώνιους υποχώρους που
περιέχουν τα αντικείμενα. Τυπικά κριτήρια για τον διαχωρισμό του χώρου περιλαμβάνουν την ελαχιστοποίηση των ορθογώνιων
περιοχών, αφού αυτό οδηγεί σε
γρήγορη συντόμευση του χώρου αναζήτησης. Προβλήματα όπως η ύπαρξη
αντικειμένων με επικαλυπτόμενες χωρικές περιοχές αντιμετωπίζονται με
διαφορετικούς τρόπους από τις πολλές διαφορετικές παραλλαγές των R-δένδρων. Οι εσωτερικοί κόμβοι των R-δένδρων αντιστοιχούν σε
ορθογώνια που η περιοχή τους καλύπτει
όλα τα ορθογώνια του υποδένδρου τους. Επομένως τα R-δένδρα μπορούν να απαντήσουν εύκολα επερωτήσεις όπως: βρες
όλα τα αντικείμενα σε μία περιοχή,
περιορίζοντας τη δενδρική αναζήτηση σε εκείνα τα υποδένδρα των οποίων τα ορθογώνια τέμνονται με την περιοχή που
δίδεται στο ερώτημα.
Άλλες χωρικές δομές αποθήκευσης περιλαμβάνουν τα τετραδικά
δένδρα και τις παραλλαγές τους. Γενικά τα τετραδικά δένδρα χωρίζουν κάθε
χώρο ή υποχώρο σε περιοχές ίσου μεγέθους
και προχωρούν με τις υποδιαιρέσεις κάθε υποχώρου για να προσδιορίσουν τις θέσεις των διαφόρων αντικειμένων. Πρόσφατα
έχουν προταθεί πολλές νέες δομές
χωρικής προσπέλασης και η περιοχή αυτή είναι ακόμη ανοικτή ερευνητικά.
16.2
Εισαγωγή στις έννοιες Βάσεων Δεδομένων Πολυμέσων
Οι βάσεις δεδομένων πολυμέσων παρέχουν
χαρακτηριστικά που επιτρέπουν στους χρήστες
να αποθηκεύουν και να κάνουν ερωτήματα σε διαφορετικούς τύπους πληροφοριών πολυμέσων που περιλαμβάνουν εικόνες
(όπως φωτογραφίες ή σχέδια), ακολουθίες βίντεο (ταινίες ειδήσεις
κλπ), ακολουθίες ήχου (όπως τραγούδια, τηλεφωνικά μηνύματα, ή αγορεύσεις) και έγγραφα (όπως βιβλία και
άρθρα). Οι βασικοί τύποι επερωτήσεων
βάσης δεδομένων που απαιτούνται περιλαμβάνουν τον εντοπισμό των πηγών πολυμέσων οι οποίες περιέχουν
κάποια αντικείμενα που ενδιαφέρουν.
Για παράδειγμα, μπορεί κάποιος να θέλει να εντοπίσει από μια βάση δεδομένων βίντεο όλες τις ακολουθίες βίντεο που
περιέχουν ένα συγκεκριμένο πρόσωπο,
έστω τον Κλίντον. Μπορεί επίσης να θέλει να ανακτήσει ακολουθίες βίντεο που να περιέχουν κάποιες δραστηριότητες,
όπως βίντεο στα οποία επιτυγχάνεται
γκολ σ' ένα ποδοσφαιρικό παιγνίδι από συγκεκριμένο παίκτη ή ομάδα.
Οι παραπάνω τύποι επερωτήσεων αναφέρονται σαν ανάκτηση
με βάση το περιεχόμενο, επειδή η. ανάκτηση από την πηγή του πολυμέσου
βασίζεται στο ότι περιέχει κάποια
αντικείμενα ή δραστηριότητες. Επομένως μια βάση δεδομένων πολυμέσων
πρέπει να χρησιμοποιεί κάποιο μοντέλο για την οργάνωση και τα ευρετήρια των πηγών πολυμέσων που θα βασίζεται στα
περιεχόμενα τους. Ο προσδιορισμός των περιεχομένων των πηγών πολυμέσων
είναι μια δύσκολη και χρονοβόρα προσπάθεια.
Υπάρχουν δύο βασικές προσεγγίσεις. Η πρώτη βασίζεται στην αυτόματη
ανάλυση των πηγών πολυμέσων για τον προσδιορισμό κάποιων μαθηματικών χαρακτηριστικών του περιεχομένου τους. Η
προσέγγιση αυτή χρησιμοποιεί διαφορετικές τεχνικές ανάλογα με τον τύπο
της πηγής του πολυμέσου (εικόνα, κείμενο,
βίντεο ή ήχος). Η δεύτερη προσέγγιση εξαρτάται από τον χειρονακτικό
προσδιορισμό των αντικειμένων και των δραστηριοτήτων που
ενδιαφέρουν σε κάθε πηγή πολυμέσων και στην χρησιμοποίηση αυτών των πληροφοριών
για τη δημιουργία ευρετηρίων. Η
προσέγγιση αυτή μπορεί να εφαρμοσθεί σε όλες τις διαφορετικές πηγές
πολυμέσων, αλλά απαιτεί μια φάση χειρονακτικής προεπεξεργασίας όπου κάποιο άτομο πρέπει να σαρώσει κάθε πηγή
πολυμέσου για να προσδιορίσει και να καταλογραφήσει τα αντικείμενα και τις
δραστηριότητες που περιέχει ώστε να
μπορούν να χρησιμοποιηθούν για ευρετηριοποίηση αυτών των πηγών.
Στο υπόλοιπο αυτού του κεφαλάιου θα περιγράψουμε
πολύ περιληπτικά μερικά από τα χαρακτηριστικά κάθε τύπου πηγής πολυμέσου
-εικόνες, βίντεο, ήχος και πήγε; κειμένων,
με τη σειρά αυτή.
16.2.1
Εικόνας
Μια εικόνα τυπικά αποθηκεύεται σε μη
επεξεργασμένη μορφή σαν ένα σύνολο από τιμές πλέγματος η κελιών, ή σε
συμπιεσμένη μορφή για εξοικονόμηση χώρου. Η
περιγραφή σχήματος της εικόνας περιγράφει το σχήμα της μη επεξεργασμένης εικόνας, που τυπικά είναι ένα ορθογώνιο από κελιά συγκεκριμένου
πλάτους και ύψους. Επομένως, κάθε
εικόνα μπορεί να αναπαρασταθεί από ένα m επί n πλέγμα από κελιά. Κάθε κελί περιέχει την τιμή ενός
εικονοστοιχείου που περιγράφει το περιεχόμενο του κελιού. Στις
μαυρόασπρες εικόνες, τα εικονοστοιχεία μπορεί να είναι ένα μπιτ. Στην γκρίζα κλίμακα ή στις έγχρωμες εικόνες το
εικονοστοιχείο αποτελείται από πολλά μπιτ. Επειδή οι εικόνες μπορεί να
απαιτούν μεγάλο χώρο, συχνά αποθηκεύονται σε
συμπιεσμένη μορφή. Τα πρότυπα συμπίεσης, όπως το πρότυπο GIF,
χρησιμοποιούν διάφορους μαθηματικούς μετασχηματισμούς για να μειώσουν το πλήθος
των κελιών που αποθηκεύονται αλλά να διατηρούν τα χαρακτηριστικά της κύριας εικόνας. Οι μαθηματικοί μετασχηματισμοί που
μπορούν να χρησιμοποιηθούν περιλαμβάνουν διακριτούς μετασχηματισμούς
Fourier, διακριτούς συνημιτονοειδείς μετασχηματισμούς και κυματοειδείς μετασχηματισμούς.
Για τον εντοπισμό των αντικειμένων που ενδιαφέρουν
σε μια εικόνα, η εικόνα τυπικά χωρίζεται σε
ομογενή τμήματα χρησιμοποιώντας ένα κατηγόρημα ομογε-νοποίησης.
Για παράδειγμα, σε μια έγχρωμη εικόνα, διαδοχικά κελιά και με περίπου ίδιες τιμές εικονοστοιχείου ομαδοποιούνται σε
τμήματα. Η τμηματοποίηση και η συμπίεση μπορούν επομένως να
προσδιορίσουν τα βασικά χαρακτηριστικά μιας εικόνας.
Μια τυπική επερώτηση σε μια βάση δεδομένων εικόνων
θα ήταν να βρεθούν οι εικόνες στη βάση δεδομένων που μοιάζουν με μια δοθείσα
εικόνα. Η δοθείσα εικόνα μπορεί να είναι
ένα μεμονωμένο τμήμα που περιέχει έστω ένα πρότυπο που ενδιαφέρει, και
η επερώτηση είναι να εντοπισθούν άλλες εικόνες που περιέχουν το ίδιο πρότυπο.
Υπάρχουν δύο βασικές τεχνικές γι' αυτό τον τύπο της αναζήτησης. Η πρώτη προσέγγιση χρησιμοποιεί μια συνάρτηση
απόστασης για να συγκρίνει τη δοθείσα εικόνα με τις αποθηκευμένες εικόνες και
τα τμήματα τους. Αν η τιμή της απόστασης που επιστρέφεται είναι μικρή,
τότε η πιθανότητα εύρεσης του προτύπου
είναι μεγάλη. Μπορούν να δημιουργηθούν ευρετήρια που να ομαδοποιούν τις
αποθηκευμένες εικόνες με περίπου ίδια μετρική απόσταση έτσι που να περιορίζεται
ο χώρος της αναζήτησης. Η δεύτερη προσέγγιση, που ονομάζεται προσέγγιση
μετασχηματισμού, μετράει την ομοιότητα των εικόνων εκτελώντας ένα
μικρό αριθμό μετασχηματισμών που
μπορούν να μετασχηματίσουν τα κελιά μιας εικόνας για να ταιριάζουν με της άλλης. Οι μετασχηματισμοί περιλαμβάνουν
στροφές, μεταφράσεις και κλιμάκωση. Αν και η τελευταία προσέγγιση είναι πιο γενική
, είναι επίσης πιο χρονοβόρα και δύσκολη.
16.2.2
Βίντεο
Μια πηγή βίντεο τυπικά αναπαριστάνεται από
μια ακολουθία από καρέ, όπου κάθε καρέ είναι μια παγωμένη εικόνα. Ωστόσο, αντί
να προσδιορίζονται τα αντίκείμενα και οι
δραστηριότητες σε κάθε ξεχωριστό καρέ, το βίντεο χωρίζεται σε τμήματα,
όπου κάθε τμήμα αποτελείται από μια ακολουθία διαδοχικών καρέ που περιέχουν
τα ίδια αντικείμενα ή δραστηριότητες. Κάθε τμήμα προσδιορίζεται από το αρχικό
και το τελικό καρέ. Τα αντικείμενα και οι δραστηριότητες που προσδιορίζονται σε κάθε τμήμα βίντεο μπορούν να
χρησιμοποιηθούν για την ευρετηριοποίηση
των τμημάτων. Για την ευρετηριοποίηση των βίντεο έχει προταθεί μια τεχνική ευρετηριοποίησης
που ονομάζεται δένδρα τμημάτων καρέ. Το ευρετήριο περιλαμβάνει τόσο αντικείμενα, όπως άτομα, σπίτια,
αυτοκίνητα, όσο και δραστηριότητες, όπως ένα άτομο που κάνει μια ομιλία
ή δύο άτομα που συζητούν.
16.2.3
Κειμένου
Μια πηγή
κειμένου είναι βασικά το πλήρες κείμενο κάποιου άρθρου, βιβλίου ή περιοδικού. Τυπικά η ευρετηριοποίηση αυτών των πηγών επιτυγχάνεται
με τον προσδιορισμό των λέξεων-κλειδιών που εμφανίζονται
στο κείμενο καθώς και των σχετικών
συχνοτήτων τους. Ωστόσο, από τη διαδικασία αυτή διαγράφονται κοινές λέξεις
(και, άρθρα κλπ.). Επειδή θα μπορούσαν να υπάρχουν πάρα πολλές λέξεις-κλειδιά στην προσπάθεια ευρετηριοποίησης
εγγράφων, έχουν αναπτυχθεί τεχνικές που ελαττώνουν το πλήθος των
λέξεων-κλειδιών στις πιο σχετικές με τη συλλογή. Για τον σκοπό αυτό μπορεί να
χρησιμοποιηθεί μια τεχνική που βασίζεται σε μετασχηματισμούς πινάκων και ονομάζεται διασπάσεις μοναδικών τιμών (singular
value decopositions (SVD)). Στη συνέχεια μπορεί να χρησιμοποιηθεί μια
τεχνική ευρετηριοποίησης που ονομάζεται δένδρα
τηλεσκοπικών διανυσμάτων ή TV-δένδρα
για την ομαδοποίηση κειμένων.
16.2.4
Ήχου
Οι πηγές ήχου περιέχουν ηχογραφημένα
μηνύματα όπως ομιλίες, παρουσιάσεις
διαλέξεων ή ακόμη καταγραφές παρακολούθησης τηλεφωνικών μηνυμάτων ή συνδιαλέξεων
που έχουν επιβληθεί από τον νόμο. Εδώ μπορούν να χρησιμοποιηθούν διακριτοί
μετασχηματισμοί για τον εντοπισμό των κύριων χαρακτηριστικών της φωνής κάποιου ατόμου, ώστε να έχουμε
ευρετηριοποίηση και ανάκτηση βασισμένες
στην ομοιότητα. Τα χαρακτηριστικά στοιχεία του ήχου περιλαμβάνουν ένταση, τόνο και καθαρότητα.
16.3 Video Databases.
Το κίνητρο για την χρησιμοποίηση των video Βάσεων Δεδομένων έγκειται
καταρχήν στο γεγονός ότι το μέγεθος και το πλήθος των αρχείων video που είναι διαθέσιμο είναι
τεράστιο. Το μεγάλο αυτό πλήθος αρχείων βόντεο περιέχει πολύτιμες πληροφορίες,
είναι ένα υλικό ευέλικτο, μπορεί να επεξεργασθεί να αποθηκευθεί και να
διαδοθεί, πλέον με τις υψηλές ταχύτητες που υπάρχουν, στο διαδίκτυο.
Συνδυάζοντας τις εικόνες,
τον ήχο, το κείμενο, και τη κίνηση, το video είναι αναμφισβήτητα ο πλουσιότερος τύπος πολυμέσων.
Διάφορες προκλήσεις γεννιούνται κατά την οικοδόμηση των video
Βάσεων Δεδομένων:
Ø Η ανάγκη για το σχολιασμό της ακατέργαστης
πληροφορίας του βίντεο είναι σημαντική. Ο χειρωνακτικός σχολιασμός είναι
διαδικασία κουραστική, χρονοβόρα αλλά και υποκειμενική.
Ø Έχουν βρεθεί αλγόριθμοι και τα συστήματα που
επιτρέπουν (ημι-) αυτόματους τρόπους περιγραφής και οργάνωσης με σκοπό
περιγράφουν τα δεδομένα του βίντεο βάση το περιεχόμενό τους.
Ø Υπάρχει
διαθέσιμη τεράστια ποσότητα δεδομένων: video, ήχος,
κείμενο.
Ø Τα διαθέσιμα βίντεο είναι πληροφορία μη δομημένη και
αποθηκευμένη σε πολλούς και διαφορετικούς τύπους αρχείων
Ø Κάθε
πρόγραμμα διαχείρισης βίντεο έχει τους δικούς του “κανόνες” και “αρχές”.
Ø Η
κατανόηση του video
είναι εξαρτημένη με το γύρω περιβάλλον.
Ø
Υπάρχουν
διαφορετικοί χρήστες, διαφορετικές πλατφόρμες, διαφορετικές ανάγκες.
Λαμβάνοντας υπόψη τις
παραπάνω ανάγκες, υπάρχει μεγάλο
ερευνητικό ενδιαφέρον που αφορά την οργάνωση τεράστιου όγκου πληροφοριών και
τον σχολιασμό του βάση του περιεχομένου.
16.
3. 1. Βασικά Στοιχεία Συστήματος
Διαχείρισης Video
Βάσεων Δεδομένων.
Ο αρχικός στόχος ενός
συστήματος διαχείρισης video Βάσεων Δεδομένων είναι να εξασφαλίσει τη πρόσβαση
στα διαδοχικά στοιχεία του video. Αυτό επιτυγχάνεται ως εξής:
Ø
Διαιρείται
ένα video σε
τμήματα με αρχή και τέλος συγκεκριμένες σκηνές.
Ø
Θέτονται
σαν δείκτες τα κομμάτια αυτά
Ø
Γίνεται
αντιπροσώπευση αυτών των δεικτών με τέτοιο τρόπο που να επιτρέπει το εύκολο
“ξεφύλλισμα” και την ανάκτηση.
Ένα τέτοιο σύστημα
ουσιαστικά είναι μία Βάση Δεδομένων των δεικτών σε μία καταγραφή των ακολουθιών
video. Το ακατέργαστο στοιχείο πρέπει να διαμορφωθεί, να
συνταχθεί και να γίνει δομημένο έτσι ώστε τα ερωτήματα και η στην συνέχεια η
ανάκτηση των ακολουθιών video να
βασίζονται σε γνωστούς αλγορίθμους. Ο
σχεδιασμός του γραφικού περιβάλλοντος ( GUI ) είναι επίσης εξαιρετικά σημαντικό
στοιχείο.
Ένα τέτοιο σύστημα πρέπει
να υποστηρίζει το σχολιασμό μιας
ακολουθίας video, αποθηκεύοντας τα μεταδεδομένα.
Υπάρχουν τρεις κατηγορίες
μεταδεδομένων:
Ø
Εξαρτημένου
περιεχομένου μεταδεδομένα
Ø
Περιγραφικού
περιεχομένου μεταδεδομένα
Ø
Ανεξαρτήτου
περιεχομένου μεταδεδομένα
16.
3. 2. Video Κατατμηση και Περιληψη.
Video
Κατατμηση είναι
η χρονική κατάτμηση του video
σε μικρότερες μονάδες.
Οι video τεχνικές ανάλυσης εξάγουν τις δομικές πληροφορίες
από το βίντεο με την ανίχνευση των χρονικών ορίων, είτε υποκειμενικά από τον
χρήστη, είτε από αλγόριθμους αναγνώρισης προτύπων σε frame του βίντεο.
Video
Περιληψη είναι
η τηλεοπτική περιληπτική παρουσίαση της
πληροφορίας η οποία προσπαθεί να παρουσιάσει μια εικονογραφική περίληψη μιας video
ακολουθίας, σε μια συμπαγέστερη μορφή, που αποβάλλει τον πλεονασμό.
16.
3. 2. 1. Video Κατάτμηση.
Η video
κατάτμηση είναι η διαδικασία της τμηματοποίησης των τηλεοπτικών ακολουθιών,
στις σκηνές που μπορούν να υποδιαιρεθούν περαιτέρω στα μεμονωμένα πλάνα.
Τα πλάνα είναι συνήθως το μικρότερο αντικείμενο
ενδιαφέροντος και ανιχνεύονται είτε αυτόματα είτε χειρονακτικά αφού
αντιπροσωπεύονται από key - frames.
Η video
κατάτμηση μπορεί να εμφανιστεί είτε σε επίπεδο “πλάνου” είτε σε επίπεδο
“σκηνής”.
Η ανίχνευση στιγμιότυπου
ή σε επίπεδο “πλάνου” είναι η διαδικασία της μετάβασης μεταξύ δύο διαδοχικών
πλάνων, έτσι ώστε να συγκεντρώνεται μια ακολουθία πλαισίων που ανήκουν σε ένα
πλάνο. Υπάρχουν δύο τύποι τέτοιων μεταβάσεων, οι απότομες βαθμιαίες μεταβάσεις
και οι βαθμιαίες αλλαγές (εμφάνιση, εξαφάνιση, διάλυση).
Η ανίχνευση σε επίπεδο
“σκηνής” στη τηλεοπτική κατάτμηση είναι η αυτόματη ή χειρονακτική ανίχνευση των
σημασιολογικών ορίων (σε αντιδιαστολή με τα φυσικά όρια) στα frames ενός video. Η λύση της απαιτεί ανάλυση περιεχομένου
υψηλού επιπέδου. Έχουν υιοθετηθεί τρεις κύριες στρατηγικές στη διαδικασία της video
κατάτμησης:
Ø
Βασισμένη
στους κανόνες παραγωγής ταινιών ώστε να ανιχνευθούν οι τοπικές (χρονικές)
ενδείξεις μιας μακροσκοπικής αλλαγής.
Ø
Χρονικά
περιορισμένη συγκέντρωση. Δηλ. οι εργασίες που αφορούν σημασιολογικά το
περιεχόμενο τείνουν να εντοπιστούν εγκαίρως κάτω από λογικούς περιορισμούς.
Ø
Πρότυποι
αλγόριθμοι. Με τη στρατηγική αυτή εφαρμόζονται αλγόριθμοι για άντληση
πληροφορίας και κατάτμηση σε συγκεκριμένα προγράμματα βίντεο των οποίων οι
χρονικές δομές είναι συνήθως πολύ άκαμπτες και προβλέψιμες, όπως οι ειδήσεις
και ο αθλητισμός.
16.3.2.2. Video Περίληψη.
Η video
περίληψη εστιάζει στη περιληπτική
παρουσίαση της πληροφορίας με σκοπό την εύρεση ενός μικρότερου συνόλου εικόνων
για να αντιπροσωπεύσει το οπτικό περιεχόμενο και την παρουσίαση των key-frames
στο χρήστη.
Μια τέτοια διαδικασία,
επίσης γνωστή και ως στατικό storyboard (στατικό πίνακα με διάταξη σκηνών
έργου), είναι μια συλλογή εικόνων ή key-frames που παράγονται από το video.
Το μεγαλύτερο μέρος της
έρευνας της περιληπτικής παρουσίασης της πληροφορίας, περιλαμβάνει την εξαγωγή
key-frames και την ανάπτυξη ενός “φυλλομετρήματος” που αντιπροσωπεύει καλύτερα
το αρχικό video.
Τα πλεονεκτήματα μιας
τέτοιας αντιπροσώπευσης του αρχικού βίντεο είναι τα εξής:
Ø Οι περιλήψεις αυτού του είδους μπορούν να δημιουργηθούν
πολύ γρηγορότερα από τις κινούμενες περιλήψεις εικόνας, δεδομένου ότι δεν είναι
απαραίτητος κανένας χειρισμός του ήχου ή των πληροφοριών κειμένων.
Ø
Η
χρονική διάταξη των αντιπροσωπευτικών frames
(πλαισίων) μπορεί να επιδειχθεί έτσι ώστε οι χρήστες να μπορούν να συλλάβουν τα
αποσπάσματα ακόμα πιο γρήγορα.
Ø Οι εξαγόμενες εικόνες είναι διαθέσιμες για
εκτύπωση..
Μία εναλλακτική λύση της
παραπάνω μεθόδου είναι τα “Video Skims”:
“Video
Skims”
ονομάζονται γειτονικά video clips που αποτελούνται
από μια συλλογή των ακολουθιών εικόνας και του αντίστοιχου ήχου, εξάγονται από
την αρχική πιο μακροχρόνια τηλεοπτική ακολουθία.
Τα Video Skims αντιπροσωπεύουν μια χρονική αφαίρεση πολυμέσων που
παίζεται παρά αντιμετωπίζεται στατικά. Αποτελούνται από τις πιο σχετικές
φράσεις, τις προτάσεις, και τις ακολουθίες εικόνας.
Στόχος είναι να
παρουσιάσει την αρχική video ακολουθία σε ένα μικρότερο χρονικό μέγεθος.
Υπάρχουν δύο βασικοί τύποι Video Skims:
Ø
Συνοπτικές
ακολουθίες οι οποίες χρησιμοποιούνται
για να παρέχουν στον χρήστη μια ιδέα των κυριοτέρων τηλεοπτικών σημείων.
Ø
Οι
ακολουθίες των σημαντικότερων σημείων με τα πιο ενδιαφέροντα μέρη μιας video
ακολουθίας.
Η επιλογή των κυριοτέρων
σημείων από μια video ακολουθία είναι μια υποκειμενική διαδικασία. Μια
πολύ σημαντική πτυχή της video περιληπτικής παρουσίασης της πληροφορίας είναι η
ανάπτυξη του περιβάλλοντος μεταξύ του χρήστη και των ενδιάμεσων στοιχείων που
αντιπροσωπεύουν καλύτερα την αρχική ακολουθία video.
Οι εναλλαγές μεταξύ των
διαφορετικών επιπέδων και των τύπων αφαιρέσεων που παρουσιάζονται στο χρήστη
είναι οι εξής:
Ø
Οι
περισσότεροι συμπυκνώνουν την αφαίρεση, όπου μελετούν ελάχιστα την όλη
ακολουθία αλλά η ποσότητα της πληροφορίας που λαμβάνουν δεν είναι αρκετή και
έτσι τα συμπεράσματα για την ακολουθία είναι βιαστικά και ανακριβή.
Ø
Όσο
περισσότερο λεπτομερής είναι η διαδικασία περίληψης τόσο περισσότερες
πληροφορίες μπορεί να εμφανίσει στο χρήστη ώστε να κατανοήσει το νόημα της video
ακολουθίας.
Παρακάτω,
στην Εικόνα 16.1, φαίνεται η περιληπτική παρουσίαση της πληροφορίας για την
παράδοση στους διάφορους χρήστες.

Εικόνα 16.1 Παράδοση πληροφορία Video στους διάφορους χρήστες
16.3.3
Ευρετηρίαση – Ερωτήματα - Ανάκτηση.
Συγκρίνοντας τον παραδοσιακό τρόπο ευρετηρίασης κειμένου σε ένα DBMS με αυτό της video
ευρετηρίασης διαπιστώνεται ότι είναι δυσκολότερο και πιο σύνθετο να επιτευχθεί
κάτι αντίστοιχο.
Ø
Ενώ στο
παραδοσιακό DBMS, τα στοιχεία που επιλέγονται συνήθως βασίζονται σε μια ή
περισσότερες μοναδικές ιδιότητες (βασικοί τομείς), στο βίντεο δεν είναι ούτε
σαφές ούτε εύκολο να αποφασιστεί τι πρέπει να επιλεγεί για τη σύνταξη ενός
ευρετηρίου.
Ø
Αντίθετα
από τα στοιχεία κειμένου, η αυτόματη διαδικασία εύρεσης χρονικών ορίων και στοιχείων του video που
παράγουν τους δείκτες για την ευρετηρίαση των στοιχείων του γίνεται πολύ πιο δύσκολα.
Η ευρετηρίαση
ενός video μπορεί να ταξινομηθεί σε δύο κατηγορίες: Σχολιασμός
και Γνωρίσματα.
Ο σχολιασμός είναι
συνήθως μια χειρωνακτική διαδικασία που εκτελείται από έναν πεπειραμένο χρήστη.
Η κοινή τεχνική απαιτεί τον ορισμό λέξης - κλειδί στις video
τεχνικές ευρετηρίασης τμημάτων (πλάνα).
Στο σχολιασμό ο χρήστης
ενδιαφέρεται πρώτιστα για την επιλογή των λέξεων κλειδιών, των δομών δεδομένων
και των διεπαφών για να διευκολύνει την
προσπάθεια του ίδιου.
Οι λέξεις κλειδιά ενώ
είναι πολύ χρήσιμες στον σχολιασμό, παρουσιάζουν κάποια μειονεκτήματα όπως:
- Οι λέξεις κλειδιά δεν εκφράζουν τις
χωρικές και χρονικές σχέσεις.
- Οι λέξεις κλειδιά δεν μπορούν να αντιπροσωπεύσουν
πλήρως τις σημασιολογικές πληροφορίες και δεν υποστηρίζουν την κληρονομιά,
ομοιότητα ή το συμπέρασμα μεταξύ των περιγραφών.
- Οι λέξεις κλειδιά δεν περιγράφουν τις
σχέσεις μεταξύ των περιγραφών.
- Οι
λέξεις κλειδιά δεν κλιμακώνονται.
Παρ’ όλα αυτά όμως
παραμένουν ο κλασσικός και σημαντικότερος τρόπος σχολιασμού των video.
Εναλλακτικές λύσεις των
λέξεων κλειδιών όσο αφορά τον σχολιασμό
είναι οι παρακάτω:
Ø Πολυστρωματικός, εικονικός σχολιασμός
Ø
Τμηματικός
σχολιασμός.
Ø
Χωρική
χρονική λογική
Η δεύτερη κατηγορία
μπορεί να επιτρέψει την πλήρως αυτοματοποιημένη ευρετηρίαση μιας ακολουθίας video
βασισμένης στο περιεχόμενό της.
Στηρίζεται στις τεχνικές
επεξεργασίας εικόνας για να εξαχθούν τα βασικά οπτικά χαρακτηριστικά γνωρίσματα
(χρώμα, σύσταση, κίνηση αντικειμένου, κ. λ. π...) από τα video
στοιχεία και χρησιμοποιεί αυτά τα χαρακτηριστικά γνωρίσματα για να χτίσει τους
δείκτες. Κύριο πρόβλημα, το σημασιολογικό χάσμα. Οι τεχνικές αυτές αποτελούν
μία πρόκληση για την εξέλιξη εφαρμογών σε συγκεκριμένες κατηγορίες video όπως για παράδειγμα ειδήσεις.
16.3.
4. Διαδικασία Ανάκτησης Στοιχείων Video.
- Ο χρήστης θέτει μια ερώτηση
χρησιμοποιώντας ένα γραφικό περιβάλλον επικοινωνίας (GUI).
- Η ερώτηση υποβάλλεται σε επεξεργασία και
αξιολογείται.
- Η αξία ή το χαρακτηριστικό γνώρισμα που
έχει χρησιμοποιείται για να ταιριάξει και να ανακτήσει τα στοιχεία του video που αποθηκεύθηκαν στη Βάση Δεδομένων.
4. Η ακολουθία video που
προκύπτει παρουσιάζεται στην οθόνη του χρήστη για μελέτη.
16.3.5. Τα Πρότυπα Συμπίεσης Video και ο Ρόλος τους στις Video Βάσεις Δεδομένων.
Η θέσπιση προτύπων συμπίεσης και κωδικοποίησης
video έχει βοηθήσει την πρόοδο σε αυτόν τον τομέα. Τα
πρότυπα που χρησιμοποιούνται ευρύτατα πηγάζουν από:
Ø
Interactive video
communications:
Ø
Entertainment
and digital TV: MPEG-1, 2, κλπ.
16.3 5. 1. Αλγοριθμοι Συμπιεσης Video.
Οι
αλγόριθμοι συμπίεσης video χρησιμοποιούνται για να συμπιέσουν το ψηφιακό video για μια ευρεία χρήση των εφαρμογών όπως:
1.Τηλεοπτική
μετάδοση στο Διαδίκτυο.
2.Ανάπτυξη
τηλεοπτικών δελτίων ειδήσεων.
3.Video συσκέψεις.
4.Κατανομές
video.
5.Αποθήκευση
και έκδοση video.
Η απόδοση των σύγχρονων
προτύπων συμπίεσης όπως Mpeg-1,
2, 4 είναι αρκετά εντυπωσιακή. Τα
ακατέργαστα στοιχεία των video μπορούν
να μειωθούν σε χωρητικότητα χωρίς ιδιαίτερη απώλεια στην αναδημιουργημένη
ποιότητα.
Παρακάτω παρουσιάζονται
ορισμένα στοιχεία για το μέγεθος την αξία και την χωρητικότητα των συμπιεσμένων
video:
Very Low
Bit Rate
Ø
Frame
size: 144 χ
176 (QCIF)
Ø
Frame
rate: 5 - 15 fps
Ø
Target bit
rates: 4.8 - 64 Kbps
Medium Bit
Rate
Ø
Frame
size: 288 χ
352 (GIF) to 576 χ
720
Ø
Frame
rate: 25 - 30 fps
Ø
Target bit
rates: 200 Kbps - 1.5 Mbps
Professional
and High End Applications
Ø
Frame
size: 576 χ
720 and larger
Ø
Frame
rate: 25 - 30 fps and larger
Ø
Target bit
rates: 1.5 - 35 Mbps
16.3.6. MPEG
Τα Moving Picture Expert
Group (MPEG) είναι ένα από τα ευρύτατα αποδεκτά διεθνή πρότυπα
για την ψηφιακή συμπίεση των video. Χρησιμοποιούν τρείς βασικές τεχνικές.
Ø
MPEG-1,
συμβατή τηλεοπτική αναπαραγωγή ήχου και
ευρέως χρησιμοποιημένος τύπος για το video και το Η/Υ.
Ø
MPEG-2,
στα DVD
και ευρέως χρησιμοποιημένος τύπος στα
ηλεκτρονικά είδη ευρείας κατανάλωσης.
Ø
MPEG-4,
μεγάλη συμπίεση της εικόνας με εφαρμογές στο internet σε συτήματα παρακολούθησης κά.